My father grew up on a small farm in eastern Washington. They say you can take the boy out of the farm, but you can’t take the farm out of the boy. As a kid, I was always hearing farm life sayings from my grandfather and father. To this day, I think they are some of the best pieces of advice I have ever received. Here are a few:
Don’t wrestle with pigs. You both get filthy and the pig likes it: Avoid pointless arguments with people who thrive on conflict. It only wastes your time and energy.
Don’t count your chickens before they hatch: Don’t assume a deal is closed until the contract is signed.
Make hay while the sun shines: Capitalize on opportunities while they are available.
Don’t put all your eggs in one basket: Diversify your investments and strategies to mitigate risk.
The early bird catches the worm: Being proactive and early can lead to the best opportunities.
Every cloud has a silver lining: Look for opportunities in every challenge or setback.
Don’t cry over spilled milk: Learn from mistakes, but don’t dwell on them; move forward.
When the rooster crows, it’s time to get up: Start your day early to maximize productivity.
You can’t make an omelet without breaking a few eggs: Achieving success often requires taking some risks and making sacrifices.
You reap what you sow: Your results are a reflection of the effort and quality you put in.
Don’t look a gift horse in the mouth: Be grateful for opportunities and advantages you receive.
When in doubt, let your horse do the thinking: Trust the expertise of your team when you’re unsure.
Never approach a bull from the front, a horse from the rear, or a fool from any direction: Avoid unnecessary risks and confrontations in business.
Don’t close the barn door after the horse has bolted: Take preventive measures rather than waiting until you need to react.
A stitch in time saves nine: Address small issues before they become large problems.
The squeaky wheel gets the grease: The most noticeable or pressing issues are the ones that receive the most attention and resources first.
There’s a saying, “where there’s smoke, there’s fire.” This adage holds especially true in the context of WebPKI Certificate Authorities (CAs). Patterns of issues are one of the key tools that root programs use to understand what’s happening inside organizations. While audits are essential, they are often insufficient. Historical cases like Wirecard and Enron illustrate how audits can provide a partial and sometimes incorrect picture. Just as in most interactions in life, understanding who you are dealing with is crucial for successful navigation, especially when a power dynamic differential exists.
The Limitations of Audits
Currently, there are 86 organizations in the Microsoft root program. Most root programs have at most two people involved in monitoring and policing these 86 CAs. Technologies like Certificate Transparency make this possible, and open-source tools like Zlint and others use this data to find technically observable issues. However, these tools, combined with audits, only provide a small slice of the picture. Audits are backward-looking, not forward-looking. To understand where an organization is going, you need to understand how they operate and how focused they are on meeting their obligations.
This is where the nuanced side of root program management, the standards, and norms of the ecosystem, come into play. If we look at signals in isolation, they often appear trivial. However, when we examine them over a long enough period in the context of their neighboring signals, a more complete picture becomes apparent.
For example, consider a CA with minor compliance issues that seem trivial in isolation. A single misissued certificate might not seem alarming. But when you see a pattern of such incidents over time, combined with other issues like poor incident response or associations with controversial entities, the picture becomes clearer. These patterns reveal deeper issues within the organization, indicating potential systemic problems.
Root Program Challenges
Root programs face significant challenges in managing and monitoring numerous CAs. With limited personnel and resources, they rely heavily on technology and community vigilance. Certificate Transparency logs and tools like Zlint help identify and flag issues, but they are only part of the solution. Understanding the intentions and operational integrity of CAs requires a deeper dive into their practices and behaviors.
In the WebPKI ecosystem, context is everything. Root programs must consider the broader picture, evaluating CAs not just on isolated incidents but on their overall track record. This involves looking at how CAs handle their responsibilities, their commitment to security standards, and their transparency with the community. A CA that consistently falls short in these areas, even in seemingly minor ways, can pose a significant risk to the ecosystem.
Conclusion
Understanding the nuances of CA operations and focusing on their adherence to obligations is critical. By examining patterns over time and considering the broader context, root programs can better identify and address potential risks. The combination of audits, technological tools, and a keen understanding of organizational behavior forms a more comprehensive approach to maintaining trust in the WebPKI system.
It’s always important to remember that CAs need to be careful to keep this in mind. After all, it’s not just what you do, but what you think you do. Having your house in order is essential. By learning from past mistakes and focusing on continuous improvement, organizations can navigate public reporting obligations more effectively, ensuring they emerge stronger and more resilient.
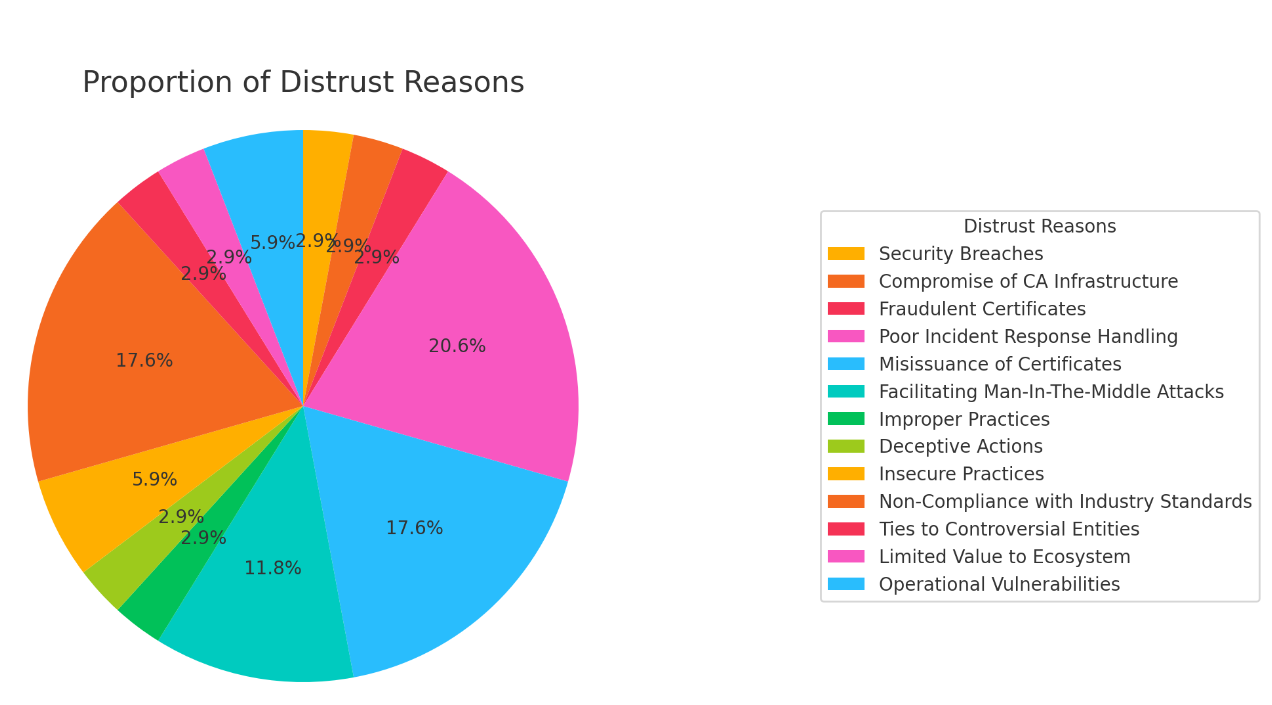
Browser distrust events of WebPKI Certificate Authorities occur on average approximately every 1.23 years. These events highlight the critical role the WebPKI plays in maintaining secure communications on the internet and how failures within this system can have far-reaching implications. By examining these incidents, we can identify common patterns and underlying causes that lead to distrust, so as implementors and operators, we don’t end up repeating the same mistakes.
Identifying Common Patterns
As they say, those who don’t know history are destined to repeat it, so it is worthwhile to take a look at the history of CA distrust events to understand what, if any common patterns exist:
Security Breaches: Involves unauthorized access to the CA’s infrastructure, leading to potential misuse of certificate issuance capabilities.
Compromise of CA Infrastructure: Refers to breaches where the core infrastructure of the CA is compromised, resulting in unauthorized certificate issuance.
Fraudulent Certificates: Occurs when certificates are issued without proper authorization, often leading to the impersonation of legitimate websites.
Poor Incident Response Handling: Indicates that the CA failed to adequately respond to security incidents, exacerbating the impact of the initial problem.
Misissuance of Certificates: Happens when CAs issue certificates incorrectly, either to the wrong entities or without proper validation, undermining trust.
Facilitating Man-In-The-Middle Attacks: Refers to situations where misissued or improperly handled certificates enable attackers to intercept and alter communications.
Improper Practices: Includes actions by CAs that deviate from accepted standards and best practices, leading to security risks.
Deceptive Actions: Involves deliberate misleading actions by CAs, such as backdating certificates or other forms of dishonesty.
Insecure Practices: Encompasses practices by CAs that fail to maintain adequate security controls, leading to vulnerabilities.
Non-Compliance with Industry Standards: Indicates that the CA has repeatedly failed to adhere to industry standards and guidelines, leading to a loss of trust.
Ties to Controversial Entities: Involves associations with entities that raise ethical or security concerns, leading to distrust.
Limited Value to Ecosystem: Indicates that the CA does not provide significant value to the security ecosystem, often due to questionable practices or minimal compliance.
Operational Vulnerabilities: Refers to weaknesses in the CA’s operational security, such as using default passwords or having exposed administrative tools, making them susceptible to attacks.
Browser Distrust Events
DigiNotar (2011):
Event: DigiNotar was hacked, leading to the issuance of fraudulent certificates. This prompted Mozilla, Google, and Microsoft to revoke trust in DigiNotar certificates.
Labels: Security Breaches, Compromise of CA Infrastructure, Fraudulent Certificates, Poor Incident Response Handling
Event: It was discovered that TurkTrust mistakenly issued two intermediate CA certificates, one of which was used to issue a fraudulent certificate for *.google.com. This led to the distrust of the TurkTrust CA by major browsers.
Labels: Misissuance of Certificates, Facilitating Man-In-The-Middle Attacks
Event: It was discovered that ANSSI had issued a certificate to a network appliance company, which used it to inspect encrypted traffic. This led Google to revoke trust in the intermediate certificate.
Labels: Misissuance of Certificates, Facilitating Man-In-The-Middle Attacks
Event: WoSign (and StartCom) were distrusted after discovering multiple security issues, including backdating certificates, lying, and improper issuance.
Labels: Misissuance of Certificates, Deceptive Actions, Insecure Practices
Event: Google announced a gradual distrust of Symantec certificates due to numerous instances of certificate misissuance, impacting millions of websites.
Labels: Misissuance of Certificates, Non-Compliance with Industry Standards, Poor Incident Response Handling
Event: TrustCor was distrusted due to concerns about its ties to companies linked to the US intelligence community and its failure to provide satisfactory responses to these concerns.
Labels: Ties to Controversial Entities, Limited Value to Ecosystem
Event: e-Tugra was distrusted due to security concerns. A researcher found numerous vulnerabilities in e-Tugra’s systems, including default passwords and accessible administrative tools, leading to a loss of trust.
Event: The Chrome Security Team announced the distrust of several Entrust roots due to a pattern of compliance failures and unmet improvement commitments.
Labels: Non-Compliance with Industry Standards, Poor Incident Response Handling
The frequency and patterns of browser distrust events underscore the critical importance of preventive measures, transparency, and effective incident response.
Implementing robust security practices, conducting regular audits, and maintaining compliance with industry standards can significantly reduce the risk of such incidents. Transparency in operations and public disclosure of security issues foster an environment of accountability and trust.
An ounce of prevention is indeed worth more than a pound of cure. By focusing on proactive measures and cultivating a culture of continuous improvement, Certificate Authorities can better navigate the complexities of WebPKI. Effective crisis communication and incident response plans are essential for managing the fallout from security breaches and maintaining the trust of users and the broader web community.
By learning from past incidents and addressing their root causes, we can work towards a more secure and resilient internet, where trust in the WebPKI system is consistently upheld. The collective effort of CAs, browser vendors, and security researchers will play a pivotal role in achieving this goal, ensuring the integrity and reliability of our online ecosystem.
Incident response is notoriously challenging, and with the rise in public reporting obligations, the stakes have never been higher. In the WebPKI world, mishandling incidents can severely damage a company’s reputation and revenue, and sometimes even end a business. The Cyber Incident Reporting for Critical Infrastructure Act of 2022 has intensified this pressure, requiring some companies to report significant breaches to CISA within 72 hours. This isn’t just about meeting deadlines. The stakes are high, and the pressure is on. Look at the recent actions of the Cyber Safety Review Board (CSRB), which investigates major cyber incidents much like how plane crashes are scrutinized. The recent case of Entrust’s cascade of incidents in the WebPKI ecosystem, and the scrutiny they have gone under as a result, shows how critical it is to respond professionally, humbly, swiftly, and transparently. The takeaway? If you don’t respond adequately to an incident, someone else might do it for you, and even if not, mishandling can result in things spiraling out of control.
The Complexity of Public Reporting
Public reports attract attention from all sides—customers, investors, regulators, the media, and more. This means your incident response team must be thorough and meticulous, leaving no stone unturned. Balancing transparency with protecting your organization’s image is critical. A well-managed incident can build trust, while a poorly handled one can cause long-term damage.
Public disclosures also potentially come with legal ramifications. Everything must be vetted to ensure compliance and mitigate potential liabilities. With tight timelines like the CISA 72-hour reporting requirement, there’s little room for error. Gathering and verifying information quickly is challenging, especially when the situation is still unfolding. Moreover, public reporting requires seamless coordination between IT, legal, PR, and executive teams. Miscommunication can lead to inconsistencies and errors in the public narrative.
The Role of Blameless Post Mortems
Blameless post-mortems are invaluable. When there’s no fear of blame, team members are more likely to share all relevant details, leading to a clearer understanding of the incident. These post-mortems focus on systemic issues rather than pointing fingers, which helps prevent similar problems in the future. By fostering a learning culture, teams can improve continuously without worrying about punitive actions.
It’s essential to identify the root causes of incidents and ensure they are fixed durably across the entire system. When the same issues happen repeatedly, it indicates that the true root causes were not addressed. Implementing automation and tooling wherever possible is crucial so that you always have the information needed to respond quickly. Incidents that close quickly have minimal impact, whereas those that linger can severely damage a business.
Knowing they won’t be blamed, team members can contribute more calmly and effectively, improving the quality of the response. This approach also encourages thorough documentation, creating valuable resources for future incidents.
Evolving Public Reporting Obligations
New regulations demand greater transparency and accountability, pushing organizations to improve their security practices. With detailed and timely information, organizations can better assess and manage their risks. The added legal and regulatory pressure leads to faster and more comprehensive responses, reducing the time vulnerabilities are left unaddressed. However, these strict timelines and detailed disclosures increase stress on incident response teams, necessitating better support and processes. Additionally, when there are systemic failures in an organization, one incident can lead to others, overwhelming stakeholders and making it challenging to prioritize critical issues.
Importance of a Strong Communication Strategy
Maintaining trust and credibility through transparent and timely communication is essential. Clear messaging prevents misinformation and reduces panic, ensuring stakeholders understand the situation and response efforts. Effective communication can mitigate negative perceptions and protect your brand, even in the face of serious incidents. Proper communication also helps ensure compliance with legal and regulatory requirements, avoiding fines and legal issues. Keeping stakeholders informed supports overall recovery efforts by maintaining engagement and trust.
Implementing Effective Communication Strategies
Preparation is key. Develop a crisis communication plan that outlines roles, responsibilities, and procedures. Scenario planning helps anticipate and prepare for different types of incidents. Speed and accuracy are critical. Provide regular updates as the situation evolves to keep stakeholders informed.
Consistency in messaging is vital. Ensure all communications are aligned across all channels and avoid jargon. Transparency and honesty are crucial—acknowledge the incident and its impact, and explain the steps being taken to address it. Showing empathy for those affected and offering support and resources demonstrates that your organization cares. Keep employees informed about the incident and the organization’s response through regular internal briefings to ensure all teams are aligned and prepared to handle inquiries.
Handling Open Public Dialogues
Involving skilled communicators who understand both the technical and broader implications of incidents is crucial. Coordination between legal and PR teams ensures that messaging is clear and accurate. Implement robust systems to track all public obligations, deadlines, and commitments, with regular audits to ensure compliance and documentation. Prepare for potential delays or issues with contingency plans and pre-drafted communications, and proactively communicate if commitments cannot be met on time.
Communication with Major Customers: It often becomes necessary to keep major customers in the loop, providing them with timely updates and reassurances about the steps being taken. Build plans for how to proactively do this successfully.
Clear Objectives and Measurable Criteria: Define clear and measurable criteria for what good public responses look like and manage to this. This helps ensure that all communications are effective and meet the required standards.
External Expert Review: Retain external experts to review your incidents with a critical eye whenever possible. This helps catch misframing and gaps before you step into a tar pit.
Clarity for External Parties: Remember that external parties won’t understand your organizational structure and team dynamics. It’s your responsibility to provide them with the information needed to interpret the report the way you intended.
Sign-Off Process: Have a sign-off process for stakeholders, including technical, business, and legal teams, to ensure the report provides the right level of information needed by its readers.
Track Commitments and Public Obligations: Track all your commitments and public obligations and respond by any committed dates. If you can’t meet a deadline, let the public know ahead of time.
In the end, humility, transparency, and accountability are what make a successful public report.
Case Study: WoSign’s Non-Recoverable Loss of Trust
Incident: WoSign was caught lying about several aspects of their certificate issuance practices, leading to a total non-recoverable loss of trust from major browsers and ultimately their removal from trusted root stores.
Outcome: The incident led to a complete loss of trust from major browsers.
Impact: This example underscores the importance of transparency and honesty in public reporting, as once trust is lost, it may never be regained.
Case Study: Symantec and the Erosion of Trust
Incident: Symantec, one of the largest Certificate Authorities (CAs), improperly issued numerous certificates, including test certificates for domains not owned by Symantec and certificates for Google domains without proper authorization. Their non-transparent, combative behavior, and unwillingness to identify the true root cause publicly led to their ultimate distrust.
Outcome: This resulted in a significant loss of trust in Symantec’s CA operations. Both Google Chrome and Mozilla Firefox announced plans to distrust Symantec certificates, forcing the company to transition its CA business to DigiCert.
Impact: The incident severely damaged Symantec’s reputation in the WebPKI community and resulted in operational and financial setbacks, leading to the sale of their CA business.
Conclusion
Navigating public reporting obligations in WebPKI and other sectors is undeniably complex and challenging. However, by prioritizing clear, honest communication and involving the right professionals, organizations can effectively manage these complexities. Rigorous tracking of obligations, proactive and transparent communication, and a robust incident response plan are critical. Case studies like those of WoSign and Symantec underscore the importance of transparency and honesty—once trust is lost, it may never be regained.
To maintain trust and protect your brand, develop a crisis communication plan that prioritizes speed, accuracy, and empathy. Consistent, transparent messaging across all channels is vital, and preparing for potential incidents with scenario planning can make all the difference. Remember, how you handle an incident can build or break trust. By learning from past mistakes and focusing on continuous improvement, organizations can navigate public reporting obligations more effectively, ensuring they emerge stronger and more resilient.
I’ve always likened the WebPKI governance system to our legal system, where congress sets the laws and the judiciary ensures compliance. Justice Breyer’s recent explanation on “rules” and “standards” in law, as discussed on the Advisory Opinions podcast, resonates well with how WebPKI operates in practice. In WebPKI, “rules” are explicitly defined through audits derived from CA/Browser Forum standards, incorporated into programs like WebTrust for CAs, and enforced through contractual obligations. These rules ensure aspire to consistent security and reliability across the web.
In contrast, “standards” in WebPKI encompass community norms, best practices, and recommendations specific to each root program. These standards are adaptable, evolving with technological advancements, security threats, and collective learning among CAs. They provide a framework that upholds the integrity of the Internet, ensuring that CAs remain transparent and live up to their promises while adhering to ecosystem norms, requirements, and best practices.
Similar to the Supreme Court, the WebPKI governance system consists of multiple ‘justices,’ with each root program acting akin to a Supreme Court justice. Their decisions on adherence or abstention from standards shape the outcomes that dictate the security and reliability of the Internet. Thus, the trust users place in WebPKI and its stewards is earned through a consistent, transparent, and accountable framework that ensures integrity across devices and browsers.
The Dual Role of Root Programs
1. As Trusted Stewards
While there’s no explicit voting process for root program management, users effectively select them through their choice of browsers or operating systems that incorporate these programs. This implicit trust in their ability to deliver on their security promises to users grants root programs the authority to establish and enforce rigorous standards for Root CAs. These standards determine inclusion in trust stores based on compliance assessments and judgments on value a CA would bring the web’s users, ensuring Root CAs uphold a consistent and transparent standard of integrity that users and web operators can rely on.
2. As Judicial Authorities
Root programs also serve a critical judicial function within the WebPKI landscape, akin to a Supreme Court. They interpret rules and standards, resolve ambiguities, settle community disputes, and establish precedents that guide CA operational practices. This role ensures equitable and consistent application of standards across all Root CAs.
Enforcing Compliance and Transparency
1. Maintaining Checks and Balances
Root programs enforce checks and balances through rigorous audits and monitoring, similar to judicial reviews. These processes assess Root CAs’ adherence to these “rules” and “standards” and ensure accountability,with the goal of preventing misuse of their authority on the web.
2. Promoting Transparency and Accountability
Root programs need to operate with a high degree of transparency, akin to open judicial proceedings. Decisions on trust or distrust of Root CAs need to be communicated clearly, accompanied by reasons for these decisions. This transparency ensures that all stakeholders, from end-users to website operators, understand and trust the framework protecting their privacy.
Case Study: The Ongoing Entrust Incident
A current discussion in the mozilla.dev.security.policy forum provides a compelling example of how the WebPKI governance framework operates in practice. This incident underscores the nuanced interaction between rules and standards, as well as the critical importance of transparency and accountability in maintaining trust.
The issue at hand involves Entrust’s performance concerns related to certificate misissuance. Such incidents are pivotal in demonstrating how root programs must navigate complex challenges and uphold rigorous standards of integrity within the web. The ongoing dialogue in the forum highlights the deliberative process undertaken by root programs to address such issues, ensuring that decisions are transparently communicated to stakeholders.
Cases like this illustrate the intricate balance that root programs must maintain between enforcing strict rules for security and adapting standards to accommodate technological advancements. The resolution of these incidents ultimately defines why users can trust root CAs, as it showcases the procedural approach, the transparency the process was designed for, and the goal of achieving accountability through this governance framework.
Why This All Matters
Understanding the dual role of root programs as regulatory bodies and judicial authorities underscores their essential role in maintaining trust. It emphasizes the significance of their decisions in shaping how privacy is delivered on the web, focusing on delivering a robust, evolving transparent, and accountable governance framework to guide these decisions.
The trust placed in WebPKI and its stewards are earned through a system that respects user choice and adheres to principles of fairness, ensuring that end-users can trust they are communicating with the correct website.
Imagine a world where every conversation, every movement, and every interaction is tracked in real-time by unseen eyes. This isn’t the plot of a dystopian novel—it’s a very real possibility enabled by today’s rapid technological advancements. As we develop and deploy powerful new tools, and maintain the ones that we built the internet on, the line between technology that makes our lives easier and invasive surveillance becomes increasingly blurred.
“In the future everyone will want to be anonymous for 15 minutes”, Banksy, 2011
This growing concern isn’t unfounded. In recent years, the push for censorship and surveillance has become more pronounced, driven by various geopolitical, social, and technological factors. While these measures often are framed around national sovereignty, combating terrorism, and protecting children, the unintended consequences could be far-reaching. Whether this occurs accidentally or purposely, the outcome can be equally invasive and harmful.
We stand at a point in history where the rapid development and deployment of new technologies, such as Microsoft’s Recall and Apple’s Private Cloud Compute, might inadvertently build the infrastructure that enables governments’ ultimate surveillance goals.
The advent of generative AI, which can extract insights at scale from video, audio, and text, opens the door to mass surveillance more than any other technology in history. These AI advancements enable detailed monitoring and analysis of vast amounts of data, making it easier for governments to track individuals and gain unprecedented insights into personal lives. To be clear, these technologies have amazing potential and are already making many people’s lives easier and making businesses more productive. In some cases, they also represent large and positive trends in privacy protection and should also give us faith in our ability to enable these innovations in a privacy-respecting way.
However, their use raises crucial questions about how we, as system designers, should evolve our philosophies on security and privacy.
A Timeline of Surveillance and Encryption Battles
Let’s take a step back and examine the historical context of government attempts to monitor citizens and the corresponding technological responses.
1990s
Introduction of technologies to enable government access, such as the Clipper Chip.
Backlash against government surveillance efforts and exposure of security flaws in Clipper Chip.
Encryption classified as a munition, leading to strict export control, an effort that held back security advancement for years..
2000s
Relaxation of U.S. export controls on encryption products in a tacit acknowledgment of its failure.
Expansion of law enforcement access to personal data through legislation like the USA PATRIOT Act.
2010s
Major leaks reveal extensive government surveillance programs.
Public debates over government backdoors in encryption.
Expansion of government surveillance capabilities through new legislation.
Proposals for key escrow systems and their criticisms from security experts.
2020s
Controversies over commercial companies their data collection and sale practices, and the use of the data by the government against citizens.
Legislative proposals and debates around encryption and privacy, such as the EARN IT Act.
EU pushes to limit CAs ability to remove EU CAs from their root programs and the mandated trust of EU CAs.
Tech companies’ attempts to implement on-device monitoring of your data and the ensuing backlash.
Suppression of legitimate discourse about COVID-19, leading to long-term impacts on public trust.
Ongoing legislative efforts to expand surveillance capabilities in the EU.
New Technologies and Surveillance Risks
Fast forward to today, and we are witnessing the rise of new technologies designed to make our data more useful. However, in our rush to build out these new capabilities, we might be inadvertently paving the way for government surveillance on an unprecedented scale.
To give this some color, let’s look back at another technological innovation: payphones. Payphones became widespread in the 1930s, and by the 1950s, the FBI under J. Edgar Hoover’s COINTELPRO program was using phone tapping to target civil rights organizations, feminist groups, and others advocating for political change. Regardless of your political leanings, we can all hopefully agree that this was an infringement on civil liberties.
Pay Phone in the Haight, San Francisco, 1967
Similarly, the advent of generative AI, which can extract insights at scale from video, audio, and text, opens the door to mass surveillance more than any other technology in history. These AI advancements enable detailed monitoring and analysis of vast amounts of data, making it easier for governments to track individuals and gain unprecedented insights into personal lives. While these technologies are useful they present a double-edged sword: the potential for more usable technology and improved productivity on one hand, and the risk of pervasive surveillance on the other.
Fast forward to the early 2000s, the USA PATRIOT Act expanded the surveillance powers of U.S. law enforcement agencies, laying the groundwork for extensive data collection practices. These powers eventually led to the Snowden revelations in 2013, which exposed the vast scope of the NSA’s surveillance programs, including the bulk collection of phone metadata and internet communications.
“How would you like this wrapped?” John Jonik, early 2000s
Clay Bennett, Christian Science Monitor, 2006
As George Santayana famously said, ‘Those who cannot remember the past are condemned to repeat it.’ Technological advancements intended to be used for good can enable detailed, real-time surveillance on a national or even global scale. This dual-use nature underscores the critical need for robust, transparent frameworks to prevent misuse and ensure these technologies align with our fundamental rights and freedoms.
Striking a Balance: Innovation and Vigilance
We do not want, nor can we afford, to be Luddites; this is a world economy, and time and technology move on. Nor do we want to let fear convince us to give up essential liberty to purchase a little temporary safety. Instead, we must strive to strike a balance between innovation and vigilance. This balance involves advocating for robust, transparent, verifiable, and accountable frameworks that ensure the use of technology aligns with our fundamental rights and freedoms.
For example, historically, many security practitioners have pushed back against the use of client-side encryption claiming it is a distraction from real security work because the software or service provider can bypass these protections. However, as we see now, applying these technologies serves as a useful tool for protecting against accidental leakage and for defense in depth more broadly. This change exemplifies the need to continually reassess and adapt our security strategies so they match the actual threat model and not some ideal.
An essential aspect of this balance is the governance of the foundational elements that ensure our privacy on the web. Root programs that underpin the WebPKI play a critical role in maintaining trust and security online. The WebPKI provides the infrastructure for secure Internet communication, ensuring that users can trust the websites they visit and the transactions they perform. Efforts to weaken this system, such as the eIDAS regulation in the EU, pose significant risks. Certificate Transparency (CT) logs, which provide a transparent and publicly auditable record of all certificates issued, are crucial for detecting and preventing fraudulent certificates, thus ensuring the infrastructure remains robust and reliable. Trusted root certificate authorities (CAs) must demonstrate principled, competent, professional, secure, and transparent practices, with continual review to maintain the WebPKI’s integrity. By protecting and strengthening these foundational elements, we ensure that the infrastructure supporting our digital world remains secure and trustworthy. This vigilance is crucial as we continue to innovate and develop new technologies that rely on these systems.
By protecting and strengthening these foundational elements, we ensure that the infrastructure supporting our digital world remains secure and trustworthy. This vigilance is crucial as we continue to innovate and develop new technologies that rely on these systems.
Here are several guiding principles to consider:
Transparency: Companies developing these technologies must be transparent about their data practices and the potential risks involved. Clear communication about how data is collected, stored, and used can help build trust.
Accountability: Ensuring accountability involves creating systems and processes that allow for oversight and verification of how data is handled. This can include audits, reports, and other mechanisms that demonstrate a company’s commitment to ethical data management.
Privacy by Design: Incorporating privacy features from the ground up is essential. Technologies should embed privacy controls, transparency encryption, as Private Cloud Compute does, as fundamental components, not as afterthoughts.
Legal and Ethical Standards: There must be robust legal frameworks and ethical standards governing the use of surveillance technologies. These frameworks should ensure that surveillance is conducted legally, with proper oversight, and that it respects individuals’ rights and is discoverable when it has been done so it is harder to abuse.
Public Dialogue and Advocacy: Engaging in public dialogue about the implications of these technologies is crucial. Advocacy groups, policymakers, and the tech industry need to work together to educate the public and advocate for policies that protect privacy and civil liberties.
Technological Safeguards: Implementing technological safeguards to prevent misuse is critical. This includes encryption, verifiable designs, and transparent audit-ability so reliance on blind faith isn’t a necessary precondition to ensure that surveillance capabilities are not abused.
The Role of the Tech Community
The tech community plays a pivotal role in shaping the future of these technologies. By fostering a culture of ethical development and responsible innovation, developers, engineers, and tech companies can influence how new tools are designed and deployed. This involves prioritizing user privacy and security at every stage of development and ensuring that these principles are not compromised for convenience or profit.
Historical examples demonstrate the effectiveness of this approach. The Clipper Chip breakage in the 1990s is a notable case where researchers exposed significant security flaws, proving that government-mandated backdoors can undermine overall security. More recently, the advocacy for end-to-end encryption (E2EE) and the supporting technologies showcase the tech community’s positive influence. Companies like WhatsApp, Signal and Apple have implemented E2EE, setting new standards for privacy and security in communications.
Continued innovation in this regard can be seen in developments like key transparency and contact discovery. Key transparency mechanisms allow users to verify that the encryption keys they are using have not been tampered with, minimizing the amount of trust required in service providers and showing leadership for the industry as a whole.
Developers should also advocate for and adopt open standards that enhance verifiability, auditability, security, and privacy. These standards can serve as benchmarks for best practices, helping to establish a baseline of trust and reliability in new technologies. Collaboration within the tech community can lead to the creation of robust, interoperable systems that are harder for malicious actors to exploit.
Additionally, academia plays a crucial role in this endeavor by researching and developing provably secure models for various technologies. Academic work often focuses on creating rigorous, mathematically sound methods for ensuring security and privacy. By integrating these academic findings into practical applications, we can build more secure and trustworthy systems. This partnership between industry and academia fosters innovation and helps establish a foundation for secure technology development.
Moreover, the tech community must actively engage in policy discussions. By providing expert insights and technical perspectives, they can help shape legislation that balances innovation with the protection of civil liberties. This engagement can also help policymakers understand the technical complexities and potential risks associated with surveillance technologies, leading to more informed and balanced decision-making.
And finally, important we help regulators understand that technology alone cannot solve deeply rooted social problems and over-reliance on technology will lead to unintended consequences. A balanced approach that integrates technology with thoughtful policy, ethical considerations, and social engagement is essential if we want to see effective changes.
Education and Awareness
Educating the public about the implications of these technologies is crucial. Many people may not fully understand how their data is collected, used, and potentially monitored. By raising awareness about these issues, we can empower individuals to make informed decisions about their digital privacy.
Educational initiatives can take many forms, from public awareness campaigns to integrating privacy and security topics into school curriculums. At the same time, we must be careful to recognize the concerns and motivations of those advocating for these cases. This is not a situation where preaching to the choir or pontificating about abstract possibilities will be effective. We must anchor this education in recent history and concrete examples to avoid sounding like zealots.
Conclusion
The increasing push for censorship and the risk of enabling government surveillance underscore the delicate balance between technological advancement and civil liberties. Emerging technologies bring both promise and peril, potentially enabling unprecedented surveillance.
To address these risks, we must advocate for transparency, accountability, and privacy by design. Establishing robust legal and ethical standards, engaging in public dialogue, and raising awareness about digital privacy are essential steps. The tech community must prioritize ethical development, adopt open standards, and participate in policy discussions to ensure that innovation does not come at the cost of individual rights.
In conclusion, while new technologies offer significant benefits, they also pose risks that demand careful management. By balancing innovation with vigilance, we can create a future where technology enhances usability without compromising our fundamental freedoms.
In software development, time is often of the essence. Developers are constantly pushed to deliver faster and more efficiently. Tools like GitHub Copilot have emerged, promising to accelerate coding tasks significantly. A study by GitHub found that developers using Copilot completed tasks up to 55% faster compared to those who didn’t use it [1]. However, as with speeding on the road, increased velocity in coding can lead to more significant risks and potential accidents.
The Need for Speed and Its Consequences
When driving at high speeds, the time available to react to unexpected events diminishes. Similarly, when coding tasks are completed rapidly with the help of AI copilots, developers have less time to thoroughly review and understand the code. This accelerated pace can lead to over-reliance on AI suggestions and decreased familiarity with the codebase. This lack of deep understanding might obscure potential issues that could be caught with a slower, more deliberate approach.
Narrowing the Focus
At higher speeds, drivers experience “tunnel vision,” where their field of view narrows, making it harder to perceive hazards. In coding, this translates to a reduced ability to catch subtle issues or security vulnerabilities introduced by AI-generated suggestions. A study by New York University highlighted this risk, finding that nearly 40% of code suggestions by AI tools like Copilot contained security vulnerabilities [2].
For a very basic example of how this could play out consider, an implementation of an authentication module using Copilot’s suggestions might skip input sanitization, leading to vulnerabilities like SQL injection or cross-site scripting (XSS) attacks. This omission might go unnoticed until the feature is in production, where it could lead to a security breach.
This reduction in situational awareness can be attributed to the lack of contextual knowledge AI copilots have. While they can provide syntactically correct code, they lack a nuanced understanding of the specific application or environment, leading to contextually insecure or inappropriate suggestions.
The Impact of High-Speed Errors
Higher driving speeds result in more severe accidents due to the increased force of impact. In coding, the severity of errors introduced by AI suggestions can be significant, especially if they compromise security. The GitHub study noted improvements in general code quality, as Copilot often follows best practices and common coding patterns [1]. However, the rapid pace and reliance on AI can mean fewer opportunities for developers to learn from their work and catch potential issues, leading to severe consequences in the long run.
Balancing Speed and Safety
To harness the benefits of tools like Copilot while mitigating the risks, developers, and teams can adopt several strategies:
Enhanced Code Reviews: As the volume of code increases with the use of AI copilots, rigorous code reviews become even more crucial. Teams should ensure that every piece of code is thoroughly reviewed by experienced developers who can catch issues that the AI might miss.
Integrating Security Tools: Using AI-based code reviewers and linters can help identify common issues and security vulnerabilities. These tools can act as a first line of defense, catching problems early in the development process.
Continuous Learning: Establishing a culture of continuous learning ensures that developers stay updated with the latest security practices and coding standards. This ongoing education helps them adapt to new challenges and integrate best practices into their work.
Practical Update Mechanisms: Implementing reliable and practical update mechanisms ensures that when issues are found, they can be addressed quickly and effectively. This proactive approach minimizes the impact of deployed vulnerabilities.
Balanced Use of AI: Developers should use AI copilots as assistants rather than crutches. By balancing the use of AI with hands-on coding and problem-solving, developers can maintain a high level of familiarity with their codebases.
Conclusion
The advent of AI coding tools like GitHub Copilot offers a significant boost in productivity, enabling developers to code faster than ever before. However, this speed comes with inherent risks, particularly concerning security vulnerabilities and reduced familiarity with the code.
At the same time, we must recognize that attackers can also leverage these sorts of tools to accelerate their malicious activities, making it crucial to integrate these tools ourselves. By implementing robust code review processes, integrating security analysis tools into the build pipeline, and fostering a culture of continuous learning, teams can effectively manage these risks and use AI tools responsibly.
The game is getting real, and now is the time to put the scaffolding in place to manage both the benefits and the risks of this new reality.
As they say, Those who cannot remember the past are condemned to repeat it, as we look back at the last decade, it seems we are caught in our own little Groundhog Day, reexperiencing the consequences of weak authentication and poor key management over and over.
It is not that we don’t know how to mitigate these issues; it’s more that, as organizations, we tend to avoid making uncomfortable changes. For example, the recent spate of incidents involving Snowflake customers being compromised appears to be related to Snowflake not mandating multi-factor authentication or a strong hardware-backed authenticator like Passkeys for its customers.
At the same time, not all of these key and credential thefts are related to users; many involve API keys, signing keys used by services, or code signing keys. Keys we have been failing to manage appropriately to the risks they represent to our systems and customers.
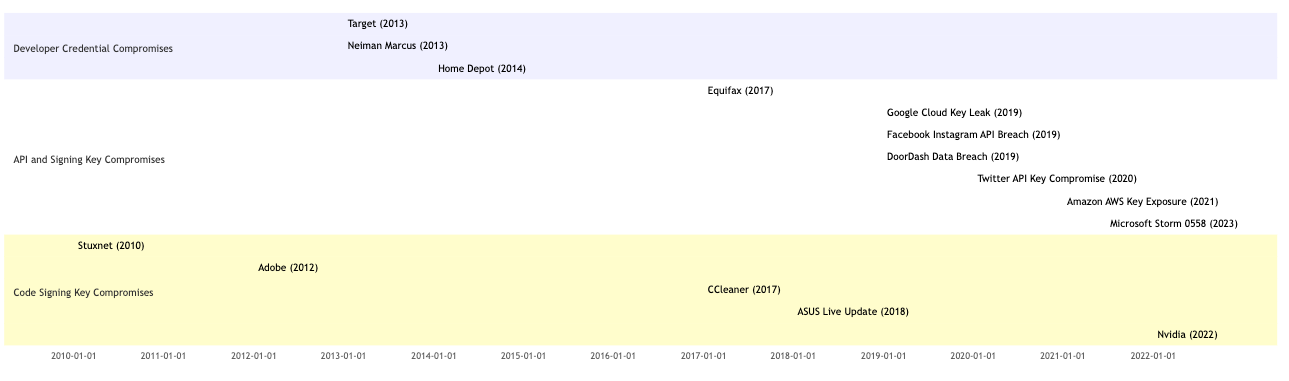
Timeline of Notable Incidents
Table of Incidents
Incident
Type of Compromise
Description
Stuxnet (2010)
Code Signing Keys
Utilized stolen digital certificates from Realtek and JMicron to authenticate its code, making it appear legitimate.
Adobe (2012)
Code Signing Keys
Attackers compromised a build server and signed malware with valid Adobe certificates.
Target (2013)
Developer Credentials
Network credentials stolen from a third-party HVAC contractor via malware on an employee’s home computer.
Neiman Marcus (2013)
Developer Credentials
Malware installed on systems, possibly through compromised credentials or devices from third-party vendors.
Home Depot (2014)
Developer Credentials
Malware infected point-of-sale systems, initiated by stolen vendor credentials, potentially compromised via phishing.
Equifax (2017)
API Keys
Exploitation of a vulnerability in Equifax’s website application exposed API keys used for authentication.
CCleaner (2017)
Code Signing Keys
Attackers inserted malware into CCleaner’s build process, distributing malicious versions of the software.
Ticketmaster (2018)
Developer Credentials
Malware from a third-party customer support product led to the compromise of payment information.
ASUS Live Update (2018)
Code Signing Keys
Attackers gained access to ASUS’s code signing keys and distributed malware through the update mechanism.
Google Cloud Key Leak (2019)
API Keys
Internal tool inadvertently exposed customer API keys on the internet, leading to potential data exposure.
Facebook Instagram API Breach (2019)
API Keys
Plaintext passwords were accessible to employees due to misuse of an internal API.
DoorDash Data Breach (2019)
API Keys
Unauthorized access to systems included the compromise of API keys, exposing sensitive customer data.
Mission Lane (2020)
Developer Credentials
Malware introduced into the development environment from a developer’s compromised personal device.
BigBasket (2020)
Developer Credentials
Data breach with over 20 million customer records exposed, suspected initial access through compromised developer credentials.
Twitter API Key Compromise (2020)
API Keys
Attackers gained access to internal systems, possibly compromising API keys or administrative credentials.
Amazon AWS Key Exposure (2021)
API Keys
Misconfigured AWS S3 bucket led to the exposure of API keys and sensitive customer data.
Nvidia (2022)
Code Signing Keys
Stolen code signing certificates were used to sign malware, making it appear legitimate.
Microsoft Storm 0558 (2023)
Signing Keys
Attackers gained access to email accounts of government agencies and other organizations by forging authentication tokens using a stolen Microsoft signing key.
When we look at these incidents we see a few common themes including:
Repetitive Failures in Security Practices:
Despite awareness of the issues, organizations continue to face the same security breaches repeatedly. This suggests a reluctance or failure to implement effective long-term solutions.
Resistance to Necessary Changes:
Organizations often avoid making uncomfortable but necessary changes, such as enforcing multi-factor authentication (MFA) or adopting stronger authentication methods like Passkeys, and adopting work This resistance contributes to ongoing vulnerabilities and compromises.
Diverse Sources of Compromise:
Key and credential thefts are not solely due to user actions but also involve API keys, service signing keys, and code signing keys. This highlights the need for comprehensive key management and protection strategies that cover all types of keys.
Broader Key Management Practices:
Moving from shared secrets to asymmetric credentials for workloads and machines can significantly enhance security. Asymmetric credentials, especially those backed by hardware, are harder to steal and misuse compared to shared secrets. Techniques like attestation, which is the device equivalent of MFA, can provide additional security by verifying the authenticity of devices and systems.
Third-Party Risks:
Even if we deploy the right technologies in our own environment, we often ignore the security practices of our upstream providers. Several incidents involved third-party vendors or services (e.g., Target, Home Depot), highlighting the critical need for comprehensive third-party risk management. Organizations must ensure that their vendors adhere to strong security practices and protocols to mitigate potential risks.
Mismanagement of API and Signing Keys:
Incidents such as the Google Cloud Key Leak and Amazon AWS Key Exposure point to misconfigurations and accidental exposures of API keys. Proper configuration management, continuous monitoring, and strict access controls are essential to prevent these exposures.
Importance of Multi-Factor Authentication (MFA):
The absence of MFA has been a contributing factor in several breaches. Organizations need to mandate MFA to enhance security and reduce the risk of credential theft.
Need for Secure Code Signing Practices:
The use of stolen code-signing certificates in attacks like Stuxnet and Nvidia underscores the importance of securing code-signing keys. Implementing hardware security modules (HSMs) for key storage and signing can help mitigate these risks.
Conclusion
Looking back at the past decade of key and credential compromises, it’s clear that we’re stuck in a loop, facing the same issues repeatedly. It’s not about knowing what to do—we know the solutions—but about taking action and making sometimes uncomfortable changes.
Organizations need to step up and embrace multi-factor authentication, adopt strong hardware-backed authenticators like Passkeys, and move workloads from shared secrets to hardware-backed asymmetric credentials for better security. We also can’t overlook the importance of managing third-party risks and ensuring proper configuration and monitoring to protect our API and signing keys.
Breaking free from this cycle means committing to these changes. By learning from past mistakes and taking a proactive approach to key and credential management, we can better protect our systems and customers – It’s time to move forward.
As software progresses from the developer’s machine to staging and finally to production, it undergoes significant changes. Each environment presents unique challenges, and transitions between these stages often introduce security weaknesses. By integrating security practices early in the development process, we bridge these gaps and help ensure we deliver a secure product. If done right, we can also improve developer productivity.
The Journey of Software Through Different Stages
In the development stage, the focus is primarily on writing code and quickly iterating on features. Security is often an afterthought, and practices like deployments, hardening, key management, auditing, and authentication between components are usually minimal or nonexistent. As the software moves to staging, it encounters a more production-like environment, revealing a new set of problems. Dependencies, network configurations, and integrations that worked on the developer’s machine may fail or expose vulnerabilities in staging.
When the software finally reaches production, the stakes are higher. It must handle real-world traffic, maintain uptime, and protect sensitive data. Here, the absence of strong security measures overlooked in earlier stages can lead to significant issues. Weak authentication, lack of auditing, and insecure configurations become glaring problems that can result in breaches and compromises.
The Role of Security in the Software Lifecycle
Security compromises often occur in the gaps between development, staging, and production. These gaps exist because each stage is treated as an isolated entity, leading to inconsistencies in security practices. To secure the software supply chain, we must address these gaps from the very beginning.
Integrating security practices early in the development process ensures that security is not an afterthought but a core component of software development. Here’s how we can achieve this, in no particular order:
Start from the beginning with a Threat Model The right place to start addressing this problem is with a threat model, involving everyone in its development so the lessons from its creation are factored into the product’s manifestation. This model also needs to continuously evolve and adapt as the project progresses. A well-defined threat model helps identify potential security risks and guides the implementation of appropriate security controls and design elements throughout software development.
Early Implementation of Authentication and Authorization From the first line of code, understand how you will implement authentication and authorization mechanisms for both users and workloads. A good example of how to do this for workloads is SPIFFE, which provides a robust framework for securely identifying and authenticating workloads. SPIRL makes deploying and adopting SPIFFE easy, laying the groundwork for unifying authentication and authorization across various stages of development. Ensure that every component, service, and user interaction is authenticated and authorized appropriately. This practice prevents unauthorized access and reduces the risk of security breaches.
Continuous Auditing and Monitoring Integrate auditing and monitoring tools into the development pipeline and runtime environments. By continuously monitoring code changes, dependencies, configurations, and runtime behavior, we can detect and address vulnerabilities early. Additionally, automated analysis tools that integrate into CI/CD pipelines, like those from Binarly, can perform security checks to ensure that vulnerabilities and back doors didn’t sneak their way in during the build. Synthetic load testing modeled after real use cases can help detect outages and abnormal behavior early, ensuring that issues are identified before reaching production, and can serve as useful production monitoring automation.
Automate Security Infrastructure Incorporate automated security infrastructure to offload security tasks from developers. Middleware frameworks, such as service meshes and security orchestration platforms, provide standard interfaces for security operations. For example, using a service mesh like Istio can automatically handle authentication, authorization, and encryption between microservices without requiring developers to implement these security features manually. This allows developers to focus on shipping code while ensuring consistent security practices are maintained. These frameworks enable faster deployment into production, ensuring that security checks are embedded and consistent across all stages.
Implement Infrastructure as Code (IaC) Implement Infrastructure as Code (IaC) to ensure consistent configuration and reduce human error. By automating infrastructure management, IaC not only enhances the reliability and security of your systems but also significantly improves your ability to recover from incidents and outages when they occur. With IaC, you can quickly replicate environments, roll back changes, and restore services, minimizing downtime and reducing the impact of any disruptions.
Build for Continuous Compliance Pair IaC with continuous compliance automation to create artifacts that demonstrate adherence to security policies, reducing the compliance burden over time. Do this by using verifiable data structures, similar to how Google and others use Trillian, to log all server actions verifiably. These immutable logs create a transparent and auditable trail of activities, improving traceability and compliance.
Minimize Human Access to Production Minimize human access to production environments to reduce the risk of errors and unauthorized actions. For example, use a privileged access management system to implement access on demand, where temporary access is granted to production systems or data only when needed and with proper approvals. This ensures that developers can debug and maintain high availability without permanent access, enhancing security while allowing necessary interventions.
Implement Code Signing and Supply Chain Monitoring Implement code signing to enable the verification of the authenticity and integrity of the software at every stage. Regularly audit your dependencies to identify and mitigate the risks that they come with. As Ken Thompson famously said, “You can’t trust code that you did not totally create yourself.” This highlights the importance of not relying on blind faith when it comes to the security of external code and components.
Proper Secret Management from Day One It’s common for organizations to overlook proper secret management practices from the onset and have to graft them on later. Ensure developers have the tools to adopt proper secret management from day one, emphasizing the use of fully managed credentials rather than treating credentials as secrets. Solutions like SandboxAQ’s Aqtive Guard can help you understand where proper secret management isn’t happening and solve the problem of last-mile key management. Tools like this turn secret management into a tool for risk management, not just sprawl management.
Effective Vulnerability Management Vulnerability management is a critical aspect of maintaining a secure software environment. A key component of this is monitoring third-party dependencies, as vulnerabilities in external libraries and frameworks can pose significant risks. Implement tools that continuously scan for vulnerabilities in these dependencies and provide actionable insights without overwhelming your team with noise. By leveraging automated vulnerability management solutions, you can prioritize critical issues and reduce alert fatigue. These tools should integrate seamlessly into your development pipeline, allowing for real-time vulnerability assessments and ensuring that only relevant, high-priority alerts are raised. This approach not only enhances your security posture but also allows your team to focus on meaningful security tasks, rather than being bogged down by an excessive number of alerts.
Shift Left with Developer-Friendly Security Tools Equip developers with tools and platforms that seamlessly integrate into their workflows, offering security features without adding friction. User-friendly and non-intrusive security tools increase the likelihood of early and correct adoption by developers. For instance, tools like GitHub’s Dependabot and Snyk help identify and fix vulnerabilities in dependencies, while CodeQL allows for deep code analysis to uncover security issues before they reach production. These tools make security a natural part of the development process, enabling developers to focus on writing code while ensuring robust security practices are maintained.
Consider the Entire Lifecycle of The Offering Security is an ongoing process that extends beyond development and deployment. Regularly assess and enhance the security posture of your production environment by implementing frequent security reviews, patch management, and incident response plans. Ensure that security practices evolve alongside the software by utilizing comprehensive security playbooks. These playbooks should offer clear, repeatable steps for handling common security tasks and incidents and be updated regularly to address new threats and best practices. Crucially, feedback loops from incident response and post-mortems are essential for continuous improvement. These loops provide valuable insights into past issues, helping to prevent similar problems in the future and fostering a culture of ongoing enhancement.
Profile Your System and Understand Bottlenecks Profile your system and understand where the bottlenecks are. Have plans to both prevent them and to respond when they are encountered. This proactive approach ensures that performance issues are addressed before they impact the user experience and that you have a strategy in place for quick remediation when problems do arise.
Conclusion
Early on, normalizing security practices across all stages of software development may be challenging, but it’s crucial. By consistently applying security measures from development to production, we can bridge the gaps that lead to vulnerabilities. This not only improves security but also enhances developer productivity.
Platforms and middleware that automate security checks, enforce policies, and provide clear visibility into security issues help developers stay productive while maintaining a robust security posture, reducing outages and security incidents. By removing these security concerns from the developer’s workflow, we allow them to concentrate on what they do best: writing code.
Making security the easy and natural choice for developers enhances both security and productivity, leading to more secure and reliable software. While it may be difficult to fully implement these practices initially, developing a model that includes continuous threat analysis and plans to address any gaps will ensure long-term success. In doing so, we make the right thing the easy thing.
Thanks to Amir Omidi for his feedback on this post
When it comes to workload and service credential management, a common misconception is that you can simply reuse your existing Certificate Authority (CA) and Certificate Lifecycle Management (CLM) infrastructure to achieve your desired end-state more quickly. Given that nearly every organization has client and server TLS certificates for devices and web servers and many have made significant investments in managing and issuing these certificates, this notion seems logical. However, the design constraints of these use cases differ significantly. The transition from static to dynamic environments, along with the associated credential governance problems, makes it clear that a purpose-built approach is necessary for managing workload and service credentials.
The Static Nature of Traditional CA and CLM Infrastructure
Traditional CA and CLM infrastructure primarily deals with TLS server certificates, where the identities involved are usually domain names or IP addresses. These identifiers are largely static, pre-defined, and managed out-of-band. As a result, the lifecycle of these certificates, which includes issuance, renewal, and revocation, follows a relatively predictable pattern. These certificates are usually issued for validity periods ranging from 90 days to a year, and the processes and infrastructure are designed to handle these constraints. However, use cases surrounding workload and service credentials have a totally different set of constraints, given the highly dynamic environment and various regulatory frameworks they must adhere to.
The Dynamic Nature of Workloads and Services
Workloads and services operate in a significantly different environment. These identities often come and go as services scale up or down or undergo updates. The sheer scale at which workload and service credentials are issued and managed can be hundreds of times greater than that of traditional client and server TLS certificate use cases.
Unlike the static domain names or IP addresses used in these traditional TLS certificates, the identifiers for workloads and services are dynamically assigned as workloads spin up and down or are updated. Workload and service credentials often have a much shorter lifespan compared to server certificates. They might need to be reissued every few minutes or hours, depending on the nature of the workload and the policies of the environment. This changes the expectations of the availability and scalability of the issuing infrastructure, leading to a need for credentials to be issued as close to the workload as possible to ensure issuance doesn’t become a source of downtime.
These workloads and services are also often deployed in clusters across various geographic locations to ensure fault tolerance and scalability. Unlike server certificates that can rely on a centralized CA, workload and service credentials often need a more distributed approach to minimize latency and meet performance requirements.
Another critical difference lies in the scope of trust. For TLS client and server certificates, the security domain is essentially defined by a root certificate or the corresponding root store. However, in the context of workloads and services, the goal is to achieve least privilege. This often necessitates a much more complicated PKI to deliver on this least-privileged design.
Additionally, federation is often needed in these use cases, and it is usually not possible to standardize on just X.509. For example, you might need to interoperate with a service that works based on OAuth. Even in such cases, you want to manage all of this within one common framework to have unified control and visibility regardless of the technology used for the deployment.
Purpose-Built Solutions for Workload and Service Credential Management
Given the unique challenges of managing workload and service credentials in dynamic, cloud-native environments, existing CA and CLM investments often fall short. Purpose-built solutions, such as those based on SPIFFE (Secure Production Identity Framework for Everyone), tend to offer a more effective approach by providing dynamic, attested identities tailored for these environments.
Dynamic Identifier Assignment
Unlike static identifiers managed by traditional CLM solutions, SPIFFE dynamically assigns identifiers as workloads spin up and down, aligning with the nature of modern cloud environments.
Decentralized Issuance
By issuing credentials as close to the workload as possible, SPIFFE-based solutions reduce latency and align issuance with the availability goals of these deployments, ensuring that credentials are issued and managed efficiently without becoming a source of downtime.
Granular Policy Enforcement
SPIFFE-based solutions enable enforcing fine-grained policy through its namespacing and security domain concepts. This enables organizations to define and enforce policies at a more granular level, ensuring that workloads only access the necessary resources.
Identity Governance and Federation
SPIFFE-based solutions tend to support extending existing identity governance programs to workload and service credentials while also facilitating seamless and secure access to external services across different trust domains.
Multifactor Authentication
These SPIFFE-based solutions also provide support for attestation, which can be thought of as multi-factor authentication for workloads. This attestation verifies the workload and services’ running state and environment, tying the credentials to those environments and helping minimize the risks of credential theft.
Integration with Other Systems and Protocols
These environments can seldom rely exclusively on just X.509, which is why SPIFFE supports both X.509 and JWT formats of credentials. This flexibility allows seamless integration with various systems and protocols within cloud deployments.
Conclusion
While it might be tempting to reuse existing CA and CLM infrastructure for workload and service credential management, this approach fails to address the unique challenges posed by dynamic, cloud-native environments. The ephemeral nature of workload identities, the high frequency of credential issuance, and the need for granular trust domains necessitate purpose-built solutions like those based on SPIFFE.
These purpose-built systems are designed to handle the dynamic nature of modern environments, providing strong, attested identities and ensuring that credential management aligns with the evolving needs of cloud-native workloads. Understanding these distinctions is crucial for developing an effective identity management strategy for modern workloads and services without having to go through a reset event down the line.
To learn more about effective machine identity management, check out SPIRL and see how they are leading the way.