My name is David Margrave, I am a guest author on unmitigatedrisk.com. I have worked in the security sphere for 20 years at various U.S. federal agencies, financial institutions, and retailers. My interests include improving the state of client authentication on the Internet, which is an area that saw robust developments in the 1990s, then languished for a number of years as the Internet at large seemed content with reusable passwords and form-based authentication over SSL/TLS, but has received renewed scrutiny because of recent large scale data breaches and the veiled promise from the Federal government to ‘fix this mess or we will fix it for you’.
The Mozilla Persona project is a recent initiative to improve and standardize browser-based authentication. For a long time (over 10 years) the most widely-used form of browser-based authentication has been based on HTML forms. At its most basic level, a user will enter an identifier and reusable password into an HTML form, and submit the form in an HTTPS request to access a protected resource. The server will receive these values, validate them, and typically return state information in an encrypted and encoded HTTP cookie. Subsequent visits to the protected resource will send the cookie in the HTTP request, and the server will decrypt and validate the cookie before returning the protected content. This entire exchange usually takes place over HTTPS, but in many instances the authentication cookie is used over an HTTP connection after initial authentication has completed successfully. There are other forms of HTTP authentication and other previous attempts at standardization, but a quick survey of the largest retailers and financial institutions will show that HTML form-based authentication is still the most common by far.
Assuming that the implementers of these cookie schemes are competent amateur cryptographers and avoided the most glaring mistakes (see this paper by MIT researchers), all of these authentication schemes which rely on HTTP cookies suffer from the same critical flaw: An attacker who obtains the cookie value can impersonate the user. The crucial problem is that HTML form-based authentication schemes have not been capable of managing cryptographic keying material on the client side. More secure schemes such as Kerberos V5 use a ticket in conjunction with an accompanying session key, both of which are stored in a credentials cache. In contrast to flawed cookie-based schemes, in the Kerberos V5 protocol, a service ticket is useless to an adversary without the accompanying service ticket session key. An authentication exchange in Kerberos V5 includes the service ticket, and a value encrypted with the service ticket session key, to prove possession.There are some proprietary or enterprise-level solutions to this situation. For example, Microsoft Internet Explorer and IIS have long had (for over 10 years) the capability to use HTTP Negotiate authentication and to use GSS-API with Kerberos V5 as the underlying mechanism. The Apache web server has had the capability to accept HTTP Negotiate authentication for several years as well, but the adoption of these solutions on the Internet at large has not been widespread. At a high level, the Mozilla Persona project improves this situation by bringing the credentials cache and cryptographic capabilities into the browser, and doing so in a standardized manner. Although the underlying cryptographic algorithms may differ from the Kerberos V5 example, the importance of this project can’t be understated.
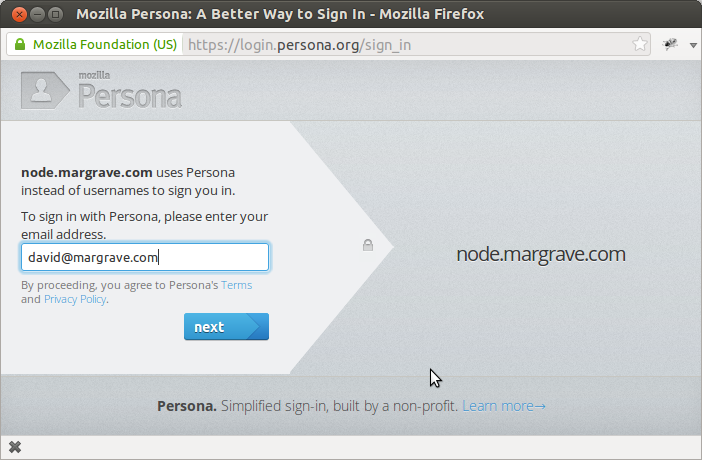
Persona introduces the concept of the Identity Data Provider (IdP). The basic idea is that a domain owner is responsible for vouching for the identity of email addresses in that domain. This could involve whatever scheme the domain owner wishes to implement. If a domain does not implement an IdP, the Persona system will use its own default IdP which uses the email verification scheme that all Internet users are familiar with: you prove your ability to receive email at a particular address. When signing-in to a website which uses Persona authentication, the user will be presented with a dialog window asking for the email address to use.
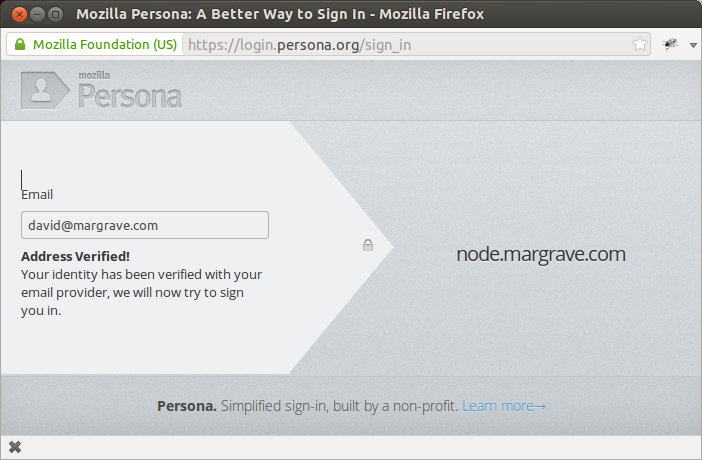
Behind the scenes, the Persona system determines which IdP to use to verify the address. A domain implementing an IdP must publish some metadata (the public key, and provisioning and verification URLs), in JSON format, at the URL https://domain/.well-known/browserid. The server at the URL must have a certificate from a trusted certificate authority, and the returned value must be properly-formatted JSON with certain required metadata information (described here).
The author implemented an IdP at the domain margrave.com as a research exercise, borrowing from the NodeJS browserid-certifier project. This particular IdP was written to accept X.509 client certificates issued by a commercial certificate authority, to extract the email address from the X.509 certificate, and issue a persona certificate with that email address. The .well-known/browserid file for node.margrave.com is shown here:
{
"public-key": {"algorithm":"DS",
"y":"aab45377fa024964a6b3339d107b91887adf85b96649b5b447a7ac7390866c92d88ed101f6525e717c0d703d5fd8727e0d1d8adb60bb80c7123730616c197326f1eed326fdfc136d7594ffce39a05005a433add8d3344813ea89f6e426d8f5b0bc0d3fdb59c8ec7c19583ba7f14d3636713b84c1ebe62a6866e9c2091def5c25aba967670eabc4591ee3f536006ce5c550265d4b2264c5a989abf908763b41014f35eb2949a0b027a1a1054203a3e13eeb1f16ffb171d6942405546a8407c3fb7e73227e432d150834054edc379de8f8988a8e3b102b70fe5b1164a28a4a453310313e00de1aa177f5ac2b73ef31670e16914607ba4196c06e57f7e5209bc7e4",
"p":"d6c4e5045697756c7a312d02c2289c25d40f9954261f7b5876214b6df109c738b76226b199bb7e33f8fc7ac1dcc316e1e7c78973951bfc6ff2e00cc987cd76fcfb0b8c0096b0b460fffac960ca4136c28f4bfb580de47cf7e7934c3985e3b3d943b77f06ef2af3ac3494fc3c6fc49810a63853862a02bb1c824a01b7fc688e4028527a58ad58c9d512922660db5d505bc263af293bc93bcd6d885a157579d7f52952236dd9d06a4fc3bc2247d21f1a70f5848eb0176513537c983f5a36737f01f82b44546e8e7f0fabc457e3de1d9c5dba96965b10a2a0580b0ad0f88179e10066107fb74314a07e6745863bc797b7002ebec0b000a98eb697414709ac17b401",
"q":"b1e370f6472c8754ccd75e99666ec8ef1fd748b748bbbc08503d82ce8055ab3b",
"g":"9a8269ab2e3b733a5242179d8f8ddb17ff93297d9eab00376db211a22b19c854dfa80166df2132cbc51fb224b0904abb22da2c7b7850f782124cb575b116f41ea7c4fc75b1d77525204cd7c23a15999004c23cdeb72359ee74e886a1dde7855ae05fe847447d0a68059002c3819a75dc7dcbb30e39efac36e07e2c404b7ca98b263b25fa314ba93c0625718bd489cea6d04ba4b0b7f156eeb4c56c44b50e4fb5bce9d7ae0d55b379225feb0214a04bed72f33e0664d290e7c840df3e2abb5e48189fa4e90646f1867db289c6560476799f7be8420a6dc01d078de437f280fff2d7ddf1248d56e1a54b933a41629d6c252983c58795105802d30d7bcd819cf6ef"
},
"authentication": "/persona/sign_in.html",
"provisioning": "/persona/provision.html"
}
The public key from the browserid file is the public portion of the key pair used by the IdP to certify users in the domain. The fact that it must be served over a URL protected with a certificate issued from a trusted CA, is how the Persona system builds on the existing trust infrastructure of the Internet, instead of attempting to re-implement their own from scratch, or requiring operators of websites relying on Persona authentication to establish shared secrets out-of-band. The authentication and provisioning URLs are how browsers interact with the IdP.
In the Certificate-based IdP implemented at margrave.com, the page located at /persona/provision.html includes some javascript which does the following things: calls an AJAX API to get the email address from the certificate, receives the email address that the user entered in the Persona login dialog via a javascript callback, validates that they match, and calls another AJAX API to issue the certificate. Note that the email address comparison performed in client-side javascript is purely for UI and troubleshooting purposes, the actual issuance of the Persona certificate uses the email address from the X.509 certificate (if the provisioning process progresses to that point), irrespective of what username was entered in the Persona login dialog. The client-side validation of the email address is to provide the ability to troubleshoot scenarios where a user may choose the wrong certificate from the browser certificate dialog box, etc. The client-side provisioning source code is shown below (ancillary AJAX error handling code is omitted).
function provision() {
// Get the email from the cert by visiting a URL that requires client cert auth and returns our cert's email in a json response.
// This is not strictly necessary, since the server will only issue persona certificates for the email address from the X.509 certificate,
// but it is useful for troubleshooting, helping the user avoid choosing the wrong certificate from the browser dialog, etc.
getEmailFromCert(function(emailFromCert) {
if (emailFromCert) {
navigator.id.beginProvisioning(function(emailFromPersona, certDuration) {
if (emailFromPersona===emailFromCert) {
navigator.id.genKeyPair(function(publicKey) {
// generateServerSide makes an AJAX call to a URL that also requires client cert auth
generateServerSide(publicKey, certDuration, function (certificate) {
if (navigator.id && navigator.id.registerCertificate) {
//alert('registering certificate: ' + certificate);
navigator.id.registerCertificate(certificate);
}
});
});
} else {
navigator.id.raiseProvisioningFailure('user is not authenticated as target user');
}
});
} else {
navigator.id.raiseProvisioningFailure('user does not have a valid X.509 certificate');
}
});
}
function generateServerSide(pubkey, duration, cb) {
$.ajax({
// Note that this URL requires SSL client certificate authentication,
// and performs its own authorization on the email address from the certificate,
// (for example, based on issuing CA or email address domain),
// and so does not need the email address as an explicit input parameter
url: "https://node.margrave.com/cert_key",
type: "POST",
global: false,
data: {pubkey: pubkey,
duration: duration},
dataType: "json",
success: function(response) {
if (response.success && response.certificate) {
cb(response.certificate);
}
}
});
return false;
}
function getEmailFromCert(cb) {
$.ajax({
// Note that this URL requires SSL client certificate authentication,
// and performs its own authorization on the email address from the certificate.
url: "https://node.margrave.com/email",
type: "POST",
global: false,
dataType: "json",
success: function(response) {
cb(response.email);
}
});}
The other portion of a Persona IdP, the authentication URL, turned out not to be necessary in this case, because the authentication is implicit in the use of X.509 client certificate-authenticated AJAX calls. Once the Persona certificate has been provisioned, the user is able to access the protected resource. If things don’t work as expected, the error messages do not seem to bubble up to the UI dialog, and I had to resort to tracing XHR calls with Firebug to determine what went wrong. In one case, it was a clock skew error that was corrected by installing ntpd on my IdP server. In another case, one of my IdP AJAX calls may return an error but this error gets masked by a vague UI message. It may be helpful to standardize HTTP return code and JSON field names to return descriptive error text to the Persona UI.
In its current form, this concept could be useful for enterprises, but not really for the Internet at large, since it requires a) that you have a client cert and b) that the IDP for your email domain is certificate-aware. However, If the persona-default IDP were certificate-aware, or CAs were persona-aware, then there are some interesting possibilities.
- The persona default IDP could skip the verification email if a trusted X.509 client certificate is provided. Possession of a certificate from a trusted CA implies the email address has already been verified, at a minimum. The Persona system already accepts CA’s trust when retrieving .well-known/browserid, this idea extends CA trust to clients.
- Going the other direction: If a CA were to accept a persona certificate from either a domain’s IDP or from the persona-default IDP, and using that to issue X.509 client certificates, or as one part of the client certificate enrollment process (higher assurance certificates may verify more information than email, such as state-issued identification). This idea seems promising because the email verification scheme is the wheel that everyone on the Internet has reimplemented, in many cases with security flaws.