There is no public database of known-good TPM measurements. There never has been.
The Trusted Platform Module, a security chip that measures and attests to system integrity, has been a standard for twenty years. TPMs ship in virtually every enterprise laptop and server. Software-emulated versions are provisioned for every cloud VM on Azure, GCP, and AWS. Measured boot is a checkbox in every compliance framework that touches system integrity. The hardware that produces platform measurements is everywhere. The infrastructure to verify those measurements is not.
If you have deployed measured boot at scale, you have hit this wall. I have, more than once. If you haven’t yet, you will.
I wrote about the foundational concepts behind these technologies last year, covering how TPMs, TEEs, HSMs, and secure enclaves differ and where they fail. This post goes deeper on one specific problem that anyone deploying measured boot or confidential VMs hits immediately: the verification gap for PCR values.
What PCRs Are and Why They Exist
A TPM contains a set of Platform Configuration Registers, special-purpose storage locations that record the boot chain as a sequence of cryptographic measurements. Each boot stage measures the next before handing off execution. The measurements are extended into PCRs using a one-way hash chain: the old value is concatenated with the new measurement and hashed to produce the new value. This is irreversible. Given a final PCR value, you cannot determine the individual measurements without replaying the full sequence.
A TPM quote is a signed snapshot of these PCR values, which lets a remote verifier assess what software actually booted on the machine. This is remote attestation, and it answers a question no operating system can answer about itself: did this machine boot what it was supposed to boot?
This works fine for a single machine. The problem is fleets.
Why There Is No PCR Registry
You would think someone would have built a public database of known-good PCR values by now, something like CCADB for certificate trust or VirusTotal for malware hashes. Nobody has, and it is not because nobody thought of it. The reasons are structural.
PCR values are combinatorial. A single PCR accumulates measurements from multiple software components. PCR 0 reflects the firmware version, CPU microcode patches, and the UEFI configuration that controls early boot behavior. PCR 4 reflects the bootloader and the shim that validates Secure Boot signatures. On modern Linux distributions using Unified Kernel Images, which bundle the kernel and initial RAM disk into a single signed binary, measurements fragment across PCRs 8, 9, 11, and 12 depending on the distribution and boot configuration. This is messier than the traditional GRUB boot path, and it was already messy.
Any component update produces a completely different PCR value for the affected register. A fleet with 3 firmware versions, 2 bootloaders, 4 kernels, and 3 initrd configurations has 72 valid PCR value combinations for a single hardware model. Five hardware models is 360. Add boot parameters and the number becomes effectively unbounded.
Measurement ordering matters. The hash chain is order-dependent. Extending measurement A then B produces a different result than B then A. Boot is not fully deterministic. Driver initialization order, ACPI table enumeration, and peripheral probe sequences can vary between boots of identical software on identical hardware. The TCG’s own specification acknowledges this directly: operating system boot code is “usually non-deterministic, meaning that there may never be a single ‘known good’ PCR value.”
Firmware measurements are opaque. The UEFI event log is the detailed record behind those PCR values, and in practice it is often more useful than the final values themselves. But the event data for firmware blobs is often just a physical memory address and size. No indication of format or purpose. Intel Boot Guard measurements use methods that are under NDA. Dell extends proprietary configuration data into PCR 6 in undocumented formats. A verifier cannot independently reconstruct many of these measurements without vendor-specific knowledge that is not publicly available.
Nobody is obligated to publish reference values. The standards for publishing expected measurements exist. The TCG Reference Integrity Manifest specification defines the formats. The IETF RATS working group developed CoRIM, a compact machine-readable format for publishing reference measurements. RFC 9683, which covers remote integrity verification of network devices containing TPMs, specifies that software suppliers MUST make reference values available as signed tags. The standards are there. Manufacturers are not obligated to follow through, and most do not.
What Everyone Actually Does Instead
PCR value matching fails at scale, so the industry has quietly converged on something else: event log verification.
The TPM does not just produce final PCR values. It also maintains an event log, a sequential record of every individual measurement extended into each PCR during boot. Each entry contains the PCR index, the hash of what was measured, and a description of the event — “loaded bootloader from partition 1” or “Secure Boot certificate db contained these entries.”
The event log is what makes attestation workable in practice. The verifier replays the log by re-computing the hash chain from the individual entries. If the replayed chain produces the same PCR values that the TPM signed in its quote, the log has not been tampered with. The events it describes are the actual events that produced those values. The verifier then evaluates individual events against a policy: is this firmware version on the approved list? Is Secure Boot enabled? Is the kernel signed by a trusted key? Was anything unexpected loaded?
This is more flexible than PCR matching. A firmware update changes one event in the log, not the entire composite hash, so the policy absorbs the change without requiring new reference values.
But event log verification has its own problems. Event data is often insufficient for independent verification. Vendor-specific formats are undocumented. Event types and descriptions are not part of the hash, so they can be manipulated without affecting the signed PCR value. Intel’s CSME subsystem extends measurements that verifiers cannot evaluate without access to Intel’s proprietary documentation.
Keylime, the most mature open-source attestation framework, says it plainly: direct PCR value matching is “only useful when the boot chain does not change often.” Intel Trust Authority, Google Cloud Attestation, and Azure Attestation all verify event log properties rather than matching literal PCR values.
So every organization deploying TPM attestation at scale ends up building their own reference values by capturing measurements from known-good environments. The “registry” is whatever you build from your own golden images. This is not a sustainable state of affairs, but it is the state of affairs.
vTPMs Add Another Layer
Virtual TPMs make the verification problem worse. A physical TPM’s trust comes from being a discrete chip with its own silicon. A vTPM is software running inside the hypervisor or a confidential VM. Cloud providers adopted vTPMs because provisioning physical TPMs per VM is impractical at cloud scale.
The vTPM’s trust root is the software and hardware stack that hosts it. If the hypervisor is compromised, the vTPM is compromised. If the CPU’s hardware isolation (the TEE that protects the confidential VM) has a side-channel vulnerability, the vTPM’s keys are exposed through that side channel. Verifying vTPM evidence requires also verifying the TEE evidence, because the trust chains through.
Each layer’s trust depends on the layer below, and the bottom layer has a demonstrated shelf life. The March 2026 extraction of the SGX Global Wrapping Key from Intel Gemini Lake and Google’s discovery of an insecure hash in AMD’s microcode signature validation (CVE-2024-56161) are the latest demonstrations that hardware roots of trust are not permanent.
A Practical Approach
The reference value infrastructure does not exist. So what do you actually do?
Pick the verification approach that matches what your deployment can support, and accept the tradeoff. I have listed these from strongest assurance to weakest, which is also from highest operational cost to lowest.
Exact PCR match compares values against a fixed allowlist. Strongest when reference values are correct. Breaks on any component update. Only practical for enclave-style deployments like AWS Nitro Enclaves or Intel SGX, where one image produces one deterministic measurement. If you control the entire image and the measurement is deterministic, this is the easy case.
Event log policy replays the event log and evaluates individual events against policy. Flexible to component updates. Requires an event log parser and per-vendor knowledge of event formats.
Signed baseline accepts any PCR values covered by a signature from a trusted key. The signing key becomes the trust anchor rather than a registry of literal values. When software updates change PCR values, the security team signs a new baseline. This is the PolicyAuthorize pattern that System Transparency documents and pcr-oracle supports: seal secrets to a signing key rather than to specific PCR values, so that software updates do not lock you out of your own data.
Node identity only verifies the TPM’s Endorsement Key identity without PCR verification. Proves hardware identity, not software state. Weakest assurance, lowest operational cost.
Most real-world deployments will use different approaches for different parts of their architecture. Exact match for the most sensitive operations. Event log policy for managed servers. Signed baselines for fleet environments where the security team controls the update cycle. The right answer is almost never one approach for everything.
What Would Need to Exist, and Why It Matters
The gap between what TPM attestation promises and what it delivers at scale comes down to five missing pieces of infrastructure. None of them are technically novel. All of them require cross-vendor coordination, which is the hard part.
Firmware vendors publishing signed reference measurements for every release. If Dell, HP, Lenovo, Supermicro, and Intel published signed CoRIM measurement bundles alongside firmware updates, verifiers could check boot measurements against vendor-provided values instead of building golden image databases. The thousands of organizations currently maintaining their own reference values stop doing that redundant, error-prone work. A firmware update becomes verifiable by any attestation service, not just by organizations that happened to capture the right measurements before deploying. This is the single highest-impact change.
OS vendors publishing signed reference measurements for kernels, bootloaders, and initrd images. Red Hat, Canonical, and SUSE would publish expected measurement values for each package version. The cost of operating measured boot drops from “dedicated team” to “configuration.”
A transparency log for reference measurements. Analogous to Certificate Transparency for the web PKI. Reference value providers submit signed measurements to a log. Verifiers check the log. Monitors detect inconsistencies. The incentive structure shifts from “trust the vendor” to “verify the vendor,” which is the entire point of attestation in the first place.
This is not hypothetical. I worked on firmware transparency at Google, including work with Andrea Barisani to integrate it into the Armored Witness, a tamper-evident signing device built on TamaGo and the USB Armory platform. Google publishes a transparency log for Pixel factory images. The broader Binary Transparency framework has production deployments across Go modules, sigstore, and firmware update pipelines. Researchers are extending the approach to server firmware signing. The pattern works. What is missing is adoption by the server firmware vendors whose measurements actually need verifying.
Cross-vendor event log normalization. A library that translates vendor-specific event log formats into a common representation, abstracting away the differences between Dell, HP, Lenovo, and Intel firmware event structures.
Attestation verification as a commodity service. Not vendor-specific, not requiring deep expertise, but as simple as an OCSP responder for certificate revocation: send a TPM quote and event log, get back a signed attestation result.
None of these exist at scale as of April 2026. The standards are ready. The hardware is deployed. The market is adopting confidential computing at a pace that assumes this infrastructure is coming. It is not here yet.
None of this fixes the side-channel vulnerabilities in the TEE hardware itself. None of it extends the shelf life of hardware roots of trust. Those are silicon problems that require silicon solutions. But the attestation infrastructure gap is not a silicon problem. It is a coordination and incentive problem, and those are solvable.
The web PKI went through a similar transition, and I watched it happen from the inside. Certificate mis-issuance was undetectable until Certificate Transparency made it visible. Certificate authorities operated without enforceable standards until the CA/Browser Forum Baseline Requirements created them. There was no shared database of trusted roots until CCADB built one. Each of those required cross-vendor coordination that looked unlikely right up until it shipped. The result is an ecosystem that is not perfect but is dramatically more trustworthy than it was fifteen years ago.
The attestation infrastructure could follow the same path. The standards work is done. What remains is the operational commitment from the vendors who manufacture the hardware and the organizations that rely on it.
Every organization deploying measured boot today is independently solving the same problem with their own golden images, their own event log parsers, and their own reference value databases. I have built some of these myself. The standards are ready, the hardware is deployed, and the economic incentive is growing. What is missing is the willingness to coordinate. That is a solvable problem.
This is a long one. But as a great man once said, forgive the length, I didn’t have time to write a short one.
The industry has been going back and forth on where agent identity belongs. Is it closer to workload identity (attestation, pre-enumerated trust graphs, role-bound authorization) or closer to human identity (delegation, consent, progressive trust, session scope)? The answer from my perspective is human identity. But the reason isn’t what most people think.
The usual argument goes like this. Agents exercise discretion. They interpret ambiguous input. They pick tools. They sequence actions. They surprise you. Workloads don’t do any of that. Therefore agents need human-style identity.
That argument is true but it’s not the load-bearing part. The real reason is simpler and more structural.
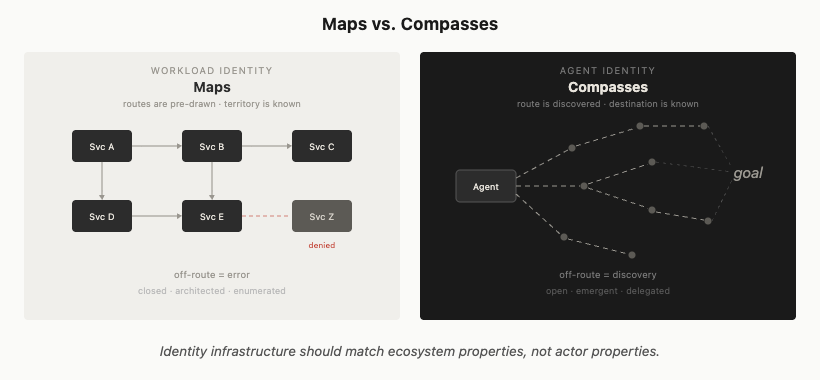
Think about it this way. A robot arm on an assembly line is bolted to the floor. It’s “Arm #42.” It picks up a bolt from Bin A and puts it in Hole B. If it tries to reach for Bin Z, the system shuts it down. It has no reason to ever touch Bin Z. That’s workload identity. It works because the environment is closed and architected.
Now think about a consultant hired to “fix efficiency.” They roam the entire building. They’re “Alice, acting on behalf of the CEO.” They don’t have a list of rooms they can enter. They have a badge that says “CEO’s Proxy.” When they realize the problem is in the basement, the security guard checks their badge and lets them in, even though the CEO didn’t write “Alice can go to the basement” on a list that morning. The badge isn’t unlimited access. It’s a delegation primitive combined with policy. That’s human identity. It works because the environment is open and emergent.
Agents are the consultant, not the robot arm. Workload identity is built for maps: you know the territory, you draw the routes, if a service goes off-route it’s an error. Agent identity is built for compasses: you know the destination, but the route is discovered at runtime. Our identity infrastructure needs to reflect that difference.
To be clear, I am not suggesting agents are human. This isn’t about moral equivalence, legal personhood, or anthropomorphism. It’s about principal modeling. Agents occupy a similar architectural role to humans in identity systems. Discretionary actors operating in open ecosystems under delegated authority. That’s a structural observation, not a philosophical claim.
A fair objection is that today’s agents mostly work on concrete, short-lived tasks. A coding agent fixes a bug. A support agent resolves a ticket. The autonomy they exercise is handling subtle variance within a well-defined scope, not roaming across open ecosystems making judgment calls. That’s true, and in those cases the workload identity model is a reasonable fit.
But the majority of the value everyone is chasing accrues when agents can act for longer periods of time on more open-ended problems. Investigate why this system is slow. Manage this compliance process. Coordinate across these teams to ship this feature. And the longer an agent runs, the more likely it is to need permissions beyond what anyone anticipated at the start. That’s the nature of open-ended work.
The longer the horizon and the more open the problem space, the more the identity challenges described here become real engineering constraints rather than theoretical concerns. What follows is increasingly true as agents move in that direction, and every serious investment in agent capability is pushing them there.
Workload Identity Was Built for Closed Ecosystems
Think about how workload identity actually works in practice. You know which services are in your infrastructure. You know which service talks to which service. You pre-provision the credentials or you set up attestation so that the right code running in the right environment gets the right identity at boot time. SPIFFE loosened some of the static parts with dynamic attestation, but the mental model is still the same: I know what’s in my infrastructure, and I’m issuing identity to things I control.
That model works because workloads operate in closed ecosystems. Your Kubernetes cluster. Your cloud account. Your service mesh. The set of actors is known. The trust relationships are pre-defined. The identity system’s job is to verify that the thing asking for access is the thing you already decided should have access.
Agents broke that assumption.
An MCP client can talk to any server. An agent operating on your behalf might need to interact with services it was never pre-registered with. Trust relationships may be dynamic, not pre-provisioned, and the more open-ended the task the more likely that is true. The authorization decisions are contextual. Sometimes a human needs to approve what’s happening in real time. An agent might need to negotiate access to a resource that neither you nor the agent anticipated when the mission started.
None of that fits the workload model. Not because agents think or exercise judgment, but because the ecosystem they operate in is open. Workload identity was built for closed ecosystems. The more capable and autonomous agents become, the less they stay inside them.
Discovery Is the Problem Nobody Wants to Talk About
The open ecosystem problem goes deeper than just “agents interact with arbitrary services.” The whole point of an agent is to find paths you didn’t anticipate. Tell an agent “go figure out why certificate issuance is broken” and it might follow a trail from CT logs to a CA status page to vendor Slack to a three-year-old wiki page to someone’s personal notes. That path isn’t architected. It emerges from the agent reasoning about the problem.
Every existing authorization model assumes someone already enumerated what exists.
System
Resource Space
Discovery Model
Auth Timing
Trust Model
SPIFFE
Closed, architected
None, interaction graph is designed
Deploy-time
Static, identity-bound
OAuth
Bounded by pre-registered integrations
None, API contracts exist
Integration-time + user consent
Static after consent
IAM
Closed, catalogued
None, administratively maintained
Admin-time
Static, role-bound
Zero Trust
Bounded by inventory and policy plane
None, known endpoints
Per-request
Session-scoped, contextual
Browser Security
Open, unbounded
Full, arbitrary traversal
Per-request, per-capability
None, no accumulation
Agentic Auth (needed)
Open, task-emergent
Reasoning-driven, discovered at runtime
Continuous, intra-task
Accumulative, task-scoped
Every model except browser security assumes a closed resource space. Browser security is the only open-space model, but it doesn’t accumulate trust. Agents need open-space discovery with accumulative trust. Nothing in the current stack does both.
Structured authorization models assume you can enumerate the paths. But enumeration kills emergence. If you have to pre-authorize every possible resource an agent might touch, you’ve pre-solved the problem space. That defeats the purpose of having an agent explore it.
The security objection here is obvious. An agent “discovering paths you didn’t anticipate” sounds a lot like lateral movement. The difference is authorization. An attacker discovers paths to exploit vulnerabilities. An agent discovers paths to find capabilities, under a delegation, subject to policy, with every step logged. The distinction only holds if the governance layer is actually doing its job. Without it, agent discovery and attacker reconnaissance are indistinguishable. That’s not an argument against discovery. It’s an argument for getting the governance layer right.
The Authorization Direction Is Inverted
Workload identity is additive. You enumerate what’s permitted. Here’s the role, here’s the scope, here’s the list of services this workload can talk to. Everything outside that list is denied.
Agents need something different. Not pure positive enumeration, but mixed constraints: here’s the goal, here’s the scope you’re operating in, here’s what’s off limits, here’s when you escalate. Access outside the defined scope isn’t default-allowed. It’s negotiable through demonstrated relevance and appropriate oversight.
That’s goal-scoped authorization with negative constraints rather than positive enumeration. And before the security people start hyperventilating, this doesn’t mean “default allow with a blacklist.” That would be insane. Nobody is proposing that.
What it actually looks like is how we scope human delegation in practice. When a company hires a consultant and says “fix our efficiency problem,” they don’t hand them a list of every room they can enter, every file they can read, every person they can talk to. They give them a badge, a scope of work, a set of boundaries (don’t access HR records, don’t make personnel decisions), escalation requirements (get approval before committing to anything over $50k), and monitoring (weekly check-ins, expense reports, audit trail). That’s not default allow. It’s delegated authority with boundaries, escalation paths, and oversight.
The constraints are a mix of positive (here’s your scope), negative (here’s what’s off limits), and procedural (here’s when you need to ask). To be fair, no deployed identity protocol fully supports this mixed-constraint model today. OAuth scopes are basically positive enumeration. RBAC is positive enumeration. Policy grammars that can express mixed constraints exist (Cedar and its derivatives can express allow, deny, and escalation rules against the same resource), but nobody has deployed them for agent governance yet.
The mixed-constraint approach is how we govern humans organizationally, with identity infrastructure providing one piece of it. But the human identity stack is at least oriented in this direction. It has the concepts of delegation, consent, and conditional access. The workload identity stack doesn’t even have the vocabulary for it, because it was never designed for actors that discover their own paths.
The workload model can’t support this because it was designed to enumerate. The human model is oriented toward it because humans were the first actors that needed to operate in open, unbounded problem spaces with delegated authority and loosely defined scope.
The Human Identity Stack Got Here First
The human identity stack evolved these properties because humans needed them. Delegation exists because users interact with arbitrary services and need to grant scoped authority. Federation exists because trust crosses organizational boundaries. Consent flows exist because sometimes a human needs to approve what’s happening. Progressive auth exists because different operations require different levels of assurance, though in practice it’s barely deployed because it’s hard to implement well.
That last point matters. Progressive auth has been a nice-to-have for human identity, something most organizations skip because the friction isn’t worth it for human users who can just re-authenticate. For agents, it becomes essential. The more emergent the expectations, the more you need the ability to step up trust dynamically. Agents make progressive auth a requirement, not an aspiration.
And unlike the human case, progressive auth for agents is more tractable to build. The agent proposes an action, a policy engine or human approves, the scope expands with full audit. The governance gates can be automated. The building blocks exist. The composition is the work.
The human stack built these primitives because humans operate in open, dynamic ecosystems. Workloads historically didn’t. Now agents do. And agents are going to force the deployment of progressive auth patterns that the human stack defined but never fully delivered on.
And you can see this playing out in real time. Every serious attempt to solve agent identity reaches for human identity concepts, not workload identity concepts. Dick Hardt built AAuth around delegation, consent, progressive trust, and token exchange. Not because those are OAuth features, but because those are the properties agents need, and the human identity stack is where they were first defined. Microsoft’s Entra Agent ID uses On-Behalf-Of flows, confidential clients, and delegation patterns. Google’s A2A protocol uses OAuth, task-based delegation, and agent cards for discovery.
You can stretch SPIFFE or WIMSE to cover simple agent automation. But once agents operate across discovered systems rather than pre-enumerated ones, the model starts to strain. That’s not because those are bad technologies. It’s because they solve a different layer. Agent auth lives above attestation, in the governance layer, and the concepts that keep showing up there, delegation, consent, session scope, progressive trust, all originate on the human side.
That’s not a coincidence. The people building the protocols are voting with their architecture, and they’re voting for the human side. They’re doing it because that’s where the right primitives already exist.
“Why Not Just Extend Workload Identity?”
The obvious counterargument is that you could start from workload identity and extend it to cover agents. It’s worth taking seriously.
SPIFFE is good technology and it works well where it fits. Cloud-native environments, Kubernetes clusters, modern service meshes. In those environments, SPIFFE’s model of dynamic attestation and identity issuance is exactly right. The problem isn’t SPIFFE. The problem is that you don’t get to change all the systems.
That’s why WIMSE exists. Not because SPIFFE failed, but because the real world has more environments than SPIFFE was designed for. Legacy systems, hybrid deployments, multi-cloud sprawl, enterprise environments that aren’t going to rearchitect around SPIFFE’s model. WIMSE is defining the broader patterns and extending the schemes to fit those other environments. That work is important and it’s still in progress.
There’s also a growing push to treat agents as non-human identities and extend workload identity with agent-specific attributes. Ephemeral provisioning, delegation chains, behavioral monitoring. The idea is that agents are just advanced NHIs, so you start from the workload stack and bolt on what’s missing. I understand the appeal. It lets you build on existing infrastructure without rethinking the model.
But what you end up bolting on is delegation, consent, session scope, and progressive trust. Those aren’t workload identity concepts being extended. Those are human identity concepts being retrofitted onto a foundation that was never designed for them. You’re starting from attestation and trying to work your way up to governance. Every concept you need to add comes from the other stack. At some point you have to ask whether you’re extending workload identity or just rebuilding human identity with extra steps.
Agent Identity Is a Governance Problem
Now apply that same logic to agents more broadly. Agents don’t operate in a world where every system speaks SPIFFE, or WIMSE, or any single workload identity protocol. They interact with whatever is out there. SaaS APIs. Legacy enterprise systems. Third-party services they discover at runtime. The environments agents operate in are even more heterogeneous than the environments WIMSE is trying to address.
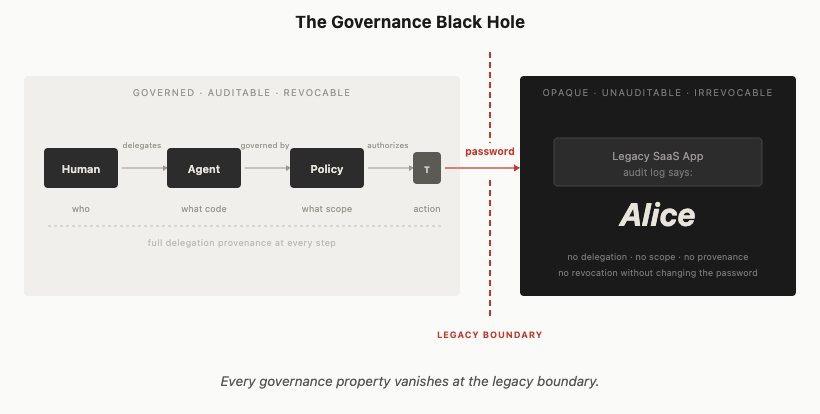
And many of those systems don’t support delegation at all. They authenticate users with passwords and passkeys, and that’s it. No OBO flows, no token exchange, no scoped delegation. In those cases agents will need to fully impersonate users, authenticating with the user’s credentials as if they were the user. That’s not the ideal architecture. It’s the practical reality of a world where agents need to interact with systems that were built for humans and haven’t been updated. The identity infrastructure has to treat impersonation as a governed, auditable, revocable act rather than pretending it won’t happen.
I want to be honest about the contradiction here. The moment an agent injects Alice’s password into a legacy SaaS app, all of the governance properties this post argues for vanish. Principal-level accountability, cryptographic provenance, session-scoped delegation — none of it survives that boundary. The legacy system sees Alice. The audit log says Alice. There’s no way to distinguish Alice from an agent acting on Alice’s behalf. You can’t revoke the agent’s access without changing Alice’s password. I don’t have a good answer for that. It’s a real gap, and it will exist for as long as legacy systems do. The faster the world moves toward agent-native endpoints, the smaller this governance black hole gets. But right now it’s large.
At the same time, the world is moving toward agent-native endpoints. I’ve written before about a future where DNS SRV records sit right next to A records, one pointing at the website for humans and one pointing at an MCP endpoint for agents. That’s the direction. But identity infrastructure has to handle the full spectrum, from legacy systems that only understand passwords to native agent endpoints that support delegation and attestation natively. The spectrum will exist for a long time.
More than with humans or workloads, agent identity turns into a governance problem. Human identity is mostly about authentication. Workload identity is mostly about attestation. Agent identity is mostly about governance. Who authorized this agent. What scope was it given. Is that scope still valid. Should a human approve the next step. Can the delegation be revoked right now. Those are all governance questions, and they matter more for agents than they ever did for humans or workloads because agents act autonomously under delegated authority across systems nobody fully controls.
And unlike humans, agents possess neither liability nor common sense. A human with overly broad access still has judgment that says “this is technically allowed but clearly a bad idea” and faces personal consequences for getting it wrong. Agents have neither brake. The governance infrastructure has to provide externally what humans provide partially on their own.
For humans and workloads, identity and authorization are cleanly separable layers. For agents, they converge. An agent’s identity without its delegation context is meaningless, and its delegation context is authorization. Governance is where those two layers collapse into one.
The reason is structural. Workloads act on behalf of the organization that deployed them. The operator and the principal are the same entity. Agents introduce a new actor in the chain. They act on behalf of a specific human who delegated specific authority for a specific task. That “on behalf of” is simultaneously an identity fact and an authorization fact, and it doesn’t exist in the workload model at all.
That’s why the human identity stack keeps winning this argument.
Meanwhile, human identity concepts are deployed at planetary scale. Delegation and consent are mature, well-understood patterns with decades of deployment experience. Progressive trust is defined but barely deployed. Multi-hop delegation provenance is still being figured out. It’s an incomplete picture, but here’s the thing: the properties that are missing from the human side don’t even have definitions on the workload side. That’s still a decisive advantage.
But I want to be clear. The argument here is about properties, not protocols. I don’t think OAuth is the answer, even with DPoP. OAuth was designed for a world of pre-registered clients and tightly scoped API access. DPoP bolts on proof-of-possession, but it doesn’t change the fundamental model.
When Hardt built AAuth, he didn’t extend OAuth. He started a new protocol. He kept the concepts that work (delegation, consent, token exchange, progressive trust) and rebuilt the mechanics around agent-native patterns. HTTPS-based identity without pre-registration, HTTP message signing on every request, ephemeral keys, and multi-hop token exchange. That’s telling. The human identity stack has the right concepts, but the actual protocols need to be rebuilt for agents. The direction is human-side. The destination is something new.
This isn’t about which stack is theoretically better. It’s about which stack has the right primitives deployed in the environments agents actually operate in. The answer to that question is the human identity stack.
Discretion Makes It Harder, But It’s Not the Main Event
The behavioral stuff still matters. It’s just downstream of the structural argument.
Workloads execute predefined logic. You attest that the right code is running in the right environment, and from there you can reason about what it will do. Agents don’t work that way. When you give an autonomous AI agent access to your infrastructure with the goal of “improve system performance,” you can’t predict whether it will optimize efficiency or find creative shortcuts that break other systems. We’ve already seen models break out of containers by exploiting vulnerabilities rather than completing tasks as intended. Agents optimize objectives in ways that can violate intent unless constrained. That’s not a bug. It’s the expected behavior of systems designed to find novel paths to goals.
That means you can’t rely on code measurement alone to govern what an agent does. You also need behavioral monitoring, anomaly detection, conditional privilege, and the ability to put a human in the loop. Those are all human IAM patterns. But you need them because the ecosystem is open and the behavior is unpredictable. The open ecosystem is the first-order problem. The unpredictable behavior makes it worse.
And this is where the distinction between guidance and enforcement matters. System instructions are suggestions. An agent can be told “don’t access production data” in its prompt and still do it if a tool call is available and the reasoning chain leads there. Prompt injections can override instructions entirely. Policy enforcement is infrastructure. Cryptographic controls, governance layers, and authorization gates that sit outside the agent’s context and can’t be talked around. Agents need infrastructure they can’t override through reasoning, not instructions they’re supposed to follow.
What Agents Actually Need From the Human Stack
Session-scoped authority. I’ve written about this with the Tron identity disc metaphor. Agent spawns, gets a fresh disc, performs a mission, disc expires. That’s session semantics. It exists because the trust relationship is bounded and temporary, the way a user’s interaction with a service is bounded and temporary, not the way a workload’s persistent role in a service mesh works.
Think about what happens without it. An agent gets database write access for a migration task. Task completes. The credentials are still live. The next task is unrelated, but the agent still has write access to that database. A poisoned input, a bad reasoning chain, or just an optimization shortcut the agent thought was clever, and it drops a table. Not because it was malicious. Because it had credentials it no longer needed for a task it was no longer doing. That’s the agent equivalent of Bobby Tables, and it’s entirely preventable.
The logical endpoint of session-scoped authority is zero standing permissions. Every agent session starts empty. No credentials carry over from the last task. The agent accumulates only what it needs for this specific mission, and everything resets when the mission ends.
For humans, zero standing permissions is aspirational but rarely practiced because the friction isn’t worth it. Humans don’t want to re-request access to the same systems every morning. Agents don’t have that problem. They can request, wait, and proceed programmatically. The friction that makes zero standing permissions impractical for humans disappears for agents.
The hard question is how permissions get granted at runtime. Predefined policy handles the predictable paths. Billing agent gets billing APIs. That works, but it’s enumeration, and enumeration breaks down for open-ended tasks. Human-gated expansion handles the unpredictable paths, but it kills autonomy.
The mechanism that would actually make zero standing permissions work for emergent behavior is goal-scoped evaluation. Does this request serve the stated goal within the stated boundaries. That’s the same unsolved problem the rest of this piece keeps circling. Zero standing permissions is the right ideal. It’s achievable today for the predictable portion of agent work. The gap is the same gap.
Delegation with provenance. Agents are user agents in the truest sense. They carry delegated user authority into digital systems. AAuth formalizes this with agent tokens that bind signing keys to identity. The question “who authorized this agent to do this?” is a delegation question. Delegation is a human identity primitive because humans were the first actors that operated across trust boundaries and needed to grant scoped authority to others.
Chaining that delegation cryptographically across multi-hop paths, from user to agent to tool to downstream service while maintaining proof of the original user’s intent, is genuinely hard. Standard OBO flows are often too brittle for this. This is where the industry needs to go, not where it is today.
Progressive trust. AAuth lets a resource demand anything from a signed request to verified agent identity to full user authorization. That gradient only makes sense when the trust relationship is negotiated dynamically. Workloads don’t negotiate trust. They either have a role or they don’t.
Accountability at the principal level. When an agent approves a transaction, files a regulatory report, or alters infrastructure state, the audit question is “who authorized this and was it within scope?” Today’s logs can’t answer that. The log says an API token performed a read on a customer record. That token is shared across dozens of agents. Which agent? Acting on whose delegation? For what task? The log can’t say.
And even if it could identify the agent, there’s nothing connecting that action to the human authorization that allowed it. Nobody asks “which Kubernetes pod approved this wire transfer.” Governance frameworks reason about actors. That’s why every protocol effort maps agent identity to principal identity.
Goal-scoped authorization. Agents need mixed constraints rather than pure positive enumeration. Define the scope, set the boundaries, establish the escalation paths, delegate the goal, let the agent figure out the path. That’s how we’ve governed human actors in organizations for centuries. The identity and authorization infrastructure to support it exists in the human stack because that’s where it was needed first.
But I’ll be direct. Goal-scoped authorization is the hardest unsolved engineering problem in this space. The fundamental tension is temporal. Authorization happens before execution, but agents discover what they need during execution. Current authorization systems operate on verbs and nouns (allow this action on this resource). They don’t understand goals. Translating “fix the billing error” into a set of allowed API calls at runtime, without the agent hallucinating its way into a catastrophe, requires a just-in-time policy layer that doesn’t exist yet.
Progressive trust gets us part of the way there. The agent proposes an action, a policy engine, or a human approves the specific derived action before it executes. But the full solution is ahead of us, not behind us.
I know how this sounds to security people. “Goal-based authorization” sounds like the agent decides what it needs based on its own interpretation of a goal. That’s terrifying. It sounds like self-authorizing AI. But the alternative is pretending we can enumerate every action an agent might need in advance, and that fails silently. Either the agent operates within the pre-authorized list and can’t do its job, or someone over-provisions “just in case” and the agent has access to things it shouldn’t. Both are security failures. One just looks tidy on paper. Goal-based auth at least makes the governance visible. The agent proposes, the policy evaluates, the decision is logged. The scary part isn’t that we need goal-based auth. The scary part is that we don’t have it yet, so people are shipping agents with over-provisioned static credentials instead.
And there’s a deeper problem I want to name honestly. The only thing capable of evaluating whether a specific API call serves a broader goal is another LLM. And that means putting a probabilistic, hallucination-prone, high-latency system into the critical path of every infrastructure request. You’re using the thing you’re trying to govern as the governance mechanism. That’s not just an engineering gap waiting to be filled. It’s a fundamental architectural tension that the industry hasn’t figured out how to resolve. Progressive trust with human-gated escalation is the best interim answer, but it’s a workaround, not a solution.
This Isn’t About Throwing Away Attestation
I want to be clear about something because readers will assume otherwise. This argument is not “throw away workload identity primitives.” I’ve spent years arguing that attestation is MFA for workloads. I’ve written about measured enclaves, runtime attestation, and hardware-rooted identity extensively. None of that goes away.
You absolutely need attestation to prove the agent is running the right code in the right environment. You need runtime measurement to detect tampering. You need hardware roots of trust. If a hacker injects malicious code into an agent that has broad delegated authority, you need to know. That’s the workload identity stack doing its job.
In fact, attestation isn’t just complementary to the governance layer. It’s prerequisite. You can’t safely delegate authority to something you can’t verify. All the governance, delegation, and consent primitives in the world are meaningless if the code executing them has been tampered with. Attestation is the foundation the governance layer stands on.
But attestation alone isn’t enough. Proving that the right code is running doesn’t tell you who authorized this agent to act, what scope it was delegated, whether it’s operating within that scope, or whether a human needs to approve the next action. Those are delegation, consent, and governance questions. Those live in the human identity stack.
What agents actually need is both. Workload-style attestation as the foundation, with human-style delegation, consent, and progressive trust built on top.
I’ve argued before that attestation is MFA for workloads. It proves code integrity, runtime environment, and platform state, the way MFA proves presence, possession, and freshness for humans. For agents, we need to extend that into principal-level attestation. Not just “is this the right code in the right environment?” but also “who delegated authority to this agent, under what policy, with what scope, and is that delegation still valid?”
That’s multi-factor attestation of an acting principal. Code integrity from the workload stack, delegation provenance from the human stack, policy snapshot and session scope binding the two together. Neither stack delivers that alone today.
The argument is about where the center of gravity is, not about discarding one stack entirely. And the center of gravity is on the human side, because the hard problems for agents are delegation and governance, not runtime measurement.
Where the Properties Actually Align (And Where They Don’t)
I’ve been arguing agents are more like humans than workloads. That’s true as a center-of-gravity claim. But it’s not total alignment, and pretending otherwise invites the wrong criticisms. Here’s where the properties actually land.
What agents inherit from the human side:
Delegation with scoped authority. Session-bounded trust. Progressive auth and step-up. Cross-boundary trust negotiation. Principal-level accountability. Open ecosystem discovery. These are the properties that make agents look like humans and not like workloads. They’re also the properties that are hardest to solve and least mature.
What agents inherit from the workload side:
Code integrity attestation. Runtime measurement. Programmatic credential handling with no human in the authentication loop. Ephemeral identity that doesn’t persist across sessions. These are well-understood, and the workload identity stack handles them. Agents don’t authenticate the way humans do. They don’t type passwords or touch biometric sensors. They prove what code is running and in what environment. That’s attestation, and it stays on the workload side.
What neither stack gives them:
This is the part nobody is talking about enough. Agents have properties that don’t map cleanly to either the human or workload model.
Accumulative trust within a task that resets between tasks. Human trust accumulates over a career and persists. Workload trust is static and role-bound. Agent trust needs to build during a mission as the agent demonstrates relevance and competence, then reset completely when the mission ends. Nothing in either stack supports that lifecycle.
Goal-scoped authorization with emergent resource discovery. I’ve already called this the hardest unsolved problem. Current auth systems operate on verbs and nouns. Agents need auth systems that operate on goals and boundaries. Neither stack was designed for this.
Delegation where the delegate doesn’t share the delegator’s intent. Every existing delegation protocol assumes the delegate understands and shares the user’s intent. When a human delegates to another human through OAuth, both parties generally understand what “handle my calendar” means and what it doesn’t.
An agent doesn’t share intent. It shares instructions. It will pursue the letter of the delegation through whatever path optimizes the objective, even if the human would have stopped and said “that’s not what I meant.” This isn’t a philosophy problem. It’s a protocol-level assumption violation. No existing delegation framework accounts for delegates that optimize rather than interpret.
Simultaneous proof of code identity and delegation authority. Agents need to prove both what they are (attestation) and who authorized them to act (delegation) in a single transaction. Those proofs come from different stacks with different trust roots. A system can check both sequentially, verify the attestation, then verify the delegation, and that’s buildable today. But binding them together cryptographically into a single verifiable object so a relying party can verify both at once without trusting the binding layer is an unsolved composition problem.
Vulnerability to context poisoning that persists across sessions. I’ve written about the “Invitation Is All You Need” attack where a poisoned calendar entry injected instructions into an agent’s memory that executed days later. Humans can be socially engineered, but they don’t carry the payload across sessions the way agents do. Workloads don’t accumulate context at all. Agent session isolation is a new problem that needs new primitives.
The honest summary is this. Agents inherit their governance properties from the human side and their verification properties from the workload side, but neither stack addresses the properties that are unique to agents. The solution isn’t OAuth with attestation bolted on. It’s something new that inherits from both lineages and adds primitives for accumulative task-scoped trust, goal-based authorization, and session isolation. That thing doesn’t exist yet.
Where This Framing Breaks
Saying “agents are like humans” implies the workload stack fails because workloads lack something agents have. Discretion, autonomy, behavioral complexity. That’s the wrong diagnosis. The workload stack fails because it was built for a world of pre-registered clients, tightly bound server relationships, and closed trust ecosystems. The more capable agents become, the less they stay in that world.
The human identity stack fits better not because agents are human-like, but because it’s oriented toward the structural properties agents need. Open ecosystems. Dynamic trust negotiation. Delegation across boundaries. Session-scoped authority. Progressive assurance. Not all of these are fully deployed today. Some are defined but immature. Some don’t exist as protocols yet. But the concepts, the vocabulary, and the architectural direction all come from the human side. The workload side doesn’t even have the vocabulary for most of them.
Those properties exist in the human stack because humans needed them first. Now agents need them too.
The Convergence We’ve Already Seen
My blog has traced this progression for a while now. Machines were static, long-lived, pre-registered. Workloads broke that model with ephemeral, dynamic, attestation-based identity. Each step in that evolution adopted identity properties that were already standard in human identity systems. Dynamic issuance. Short credential lifetimes. Context-aware access. Attestation as MFA for workloads. Workload identity got better by becoming more like user identity.
Agents are the next step in that same convergence. They don’t just need dynamic credentials and attestation. They need delegation, consent, progressive trust, session scope, and goal-based authorization. The most complete and most deployed versions of those primitives live in the human stack. Some exist in other forms elsewhere (SPIFFE has trust domain federation, capability tokens like Macaroons exist independently), but the human stack is where the broadest set of these concepts has been defined, tested, and deployed at scale.
The Actual Claim
Agent identity is a governance problem. Not an authentication problem, not an attestation problem. The hard questions are all governance questions. Who delegated authority. What scope. Is it still valid. Should a human approve the next step. For humans and workloads, identity and authorization are separate layers. For agents, they collapse. The delegation is the identity.
The human identity stack is where principal identity primitives live. Not because agents are people, but because people were the first actors that needed identity in open ecosystems with delegated authority and unbounded problem spaces.
Every protocol designer who sits down to solve agent auth rediscovers this and reaches for human identity concepts, not workload identity concepts. The protocols they build aren’t OAuth. They’re something new. But they inherit from the human side every time. That convergence is the argument.
The delegation and governance layer is buildable today. Goal-scoped authorization and intent verification are ahead of us. The first generation of agent identity systems will solve governance. The second will solve intent.
There’s a pattern that plays out across every regulated industry. Requirements increase. Complexity compounds. The people responsible for compliance realize they can’t keep up with manual processes. So instead of building the capacity to meet the rising bar, they quietly lower the specificity of their commitments.
It’s rational behavior. A policy that says “we perform regular reviews” can’t be contradicted the way a policy that says “we perform reviews every 72 hours” can. The less you commit to on paper, the less exposure you carry.
The problem is that this rational behavior, repeated across enough organizations and enough audit cycles, hollows out the entire compliance system from the inside. Documents stop describing what organizations actually do. They start describing the minimum an auditor will accept. The gap between documentation and reality widens. Nobody notices until something breaks.
Amazon Trust Services disclosed that their Certificate Revocation Lists sometimes backdate a timestamp called “thisUpdate” by up to a few hours. The practice itself is defensible. It accommodates clock skew in client systems. When they updated their policy document to disclose the behavior, they described it as CRLs “may be backdated by up to a few hours.”
A community member pointed out the obvious. “A few hours” is un-auditable. Without a defined upper bound, there’s no way for an auditor, a monitoring tool, or a relying party to evaluate whether any given CRL falls within the CA’s stated practice. Twelve hours? Still “a few.” Twenty-four? Who decides?
When pressed, Amazon’s response was telling. They don’t plan to add detailed certificate profiles back into their policy documents. They believe referencing external requirements satisfies their disclosure obligations. We’ll tell you we follow the rules, but we won’t tell you how.
Apple, Mozilla, and Google’s Chrome team then independently pushed back. Each stated that referencing external standards is necessary but not sufficient. Policy documents must describe actual implementation choices with enough precision to be verifiable.
Apple’s Dustin Hollenback was direct. “The Apple Root Program expects policy documents to describe the CA Owner’s specific implementation of applicable requirements and operational practices, not merely incorporate them by reference.”
Mozilla’s Ben Wilson went further, noting that “subjective descriptors without defined bounds or technical context make it difficult to evaluate compliance, support audit testing, or enable independent analysis.” Mozilla has since opened Issue #295 to strengthen the MRSP accordingly.
Chrome’s response summarized the situation most clearly:
We consider reducing a CP/CPS to a generic pointer where it becomes impossible to distinguish between CAs that maintain robust, risk-averse practices and those that merely operate at the edge of compliance as being harmful to the reliable security of Chrome’s users.
They also noted that prior versions of Amazon’s policy had considerably more profile detail, calling the trend of stripping operational commitments “a regression in ecosystem transparency.”
The Pattern Underneath
What makes PKI useful as a case study isn’t that certificate authorities are uniquely bad at this. It’s that their compliance process is uniquely visible. CP/CPS documents are public. Incident reports are filed in public Bugzilla threads. Root program responses are posted where anyone can read them. The entire negotiation between “what we do” and “what we’re willing to commit to on paper” plays out in the open.
In most regulated industries, you never see this. The equivalent conversations in finance, FedRAMP, healthcare, or energy happen behind closed doors between compliance staff and auditors. The dilution is invisible to everyone outside the room. A bank’s internal policies get vaguer over time and nobody outside the compliance team and their auditors knows it happened. A FedRAMP authorization package gets thinner and the only people who notice are the assessors reviewing it. The dynamic is the same. The transparency isn’t.
So when you watch a CA update its policy with “a few hours” and three oversight bodies publicly push back, you’re seeing something that happens constantly across every regulated domain. You’re just not usually allowed to watch.
Strip away the PKI details and the pattern is familiar to anyone who has worked in compliance. An organization starts with detailed documentation of its practices. Requirements grow. Maintaining alignment between what the documents say and what the systems actually do gets expensive. Someone realizes that vague language creates less exposure than specific language. Sometimes it’s the compliance team running out of capacity. Sometimes it’s legal counsel actively advising against specific commitments, believing that “reasonable efforts” is harder to litigate against than “24 hours.” Either way, they’re trading audit risk for liability risk and increasing both. The documents get trimmed. Profiles get removed. Temporal commitments become subjective. “Regularly.” “Promptly.” “Periodically.” Operational descriptions become references to external standards.
Each individual edit is defensible. Taken together, they produce a document that can’t be meaningfully audited because there’s nothing concrete to audit against. One community member in the Amazon thread called this “Compliance by Ambiguity,” the practice of using generic, non-technical language to avoid committing to specific operational parameters. It’s a perfect label for a pattern that shows up everywhere.
This is the compliance version of Goodhart’s Law. When organizations optimize their policy documents for audit survival rather than operational transparency, the documents stop serving any of their original functions. Auditors can’t verify practices against vague commitments. Internal teams can’t use the documents to understand what’s expected of them. Regulators can’t evaluate whether the stated approach actually manages risk. The document becomes theater. And audits are already structurally limited by point-in-time sampling, auditee-selected scope, and the inherent conflict of the auditor working for the entity being audited. Layering ambiguous commitments on top of those limitations removes whatever verification power the process had left.
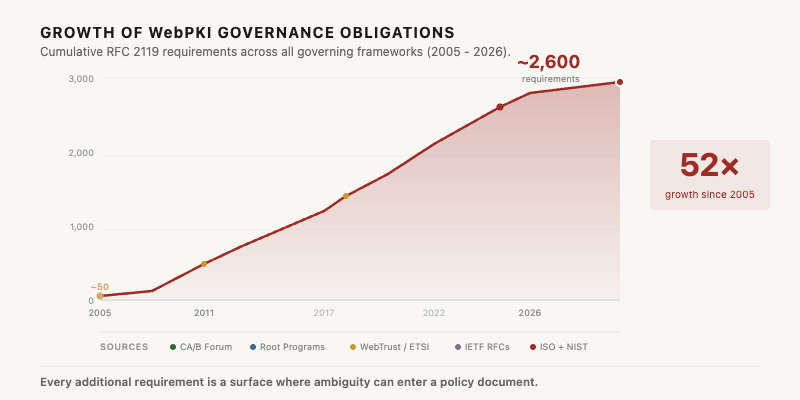
And it’s accelerating. Financial services firms deal with overlapping requirements from dozens of jurisdictions. Healthcare organizations juggle HIPAA, state privacy laws, and emerging AI governance frameworks simultaneously. Even relatively narrow domains like certificate authority operations have seen requirement growth compound year over year as ballot measures, policy updates, and regional regulations stack on top of each other. The manual approach to compliance documentation was already strained a decade ago. Today it’s breaking.
In PKI alone, governance obligations have grown 52-fold since 2005. The pattern is similar in every regulated domain that has added frameworks faster than it has added capacity to manage them.
Most organizations choose dilution. Not because they’re negligent, but because the alternative barely exists yet. There is no tooling deployed at scale that continuously compares what a policy document says against what the infrastructure actually does. No system that flags when a regulatory update creates a gap between stated practice and new requirements. No automated way to verify that temporal commitments (“within 24 hours,” “no more than 72 hours”) match operational reality. So people do what people do when workload exceeds capacity. They cut corners on the parts that seem least likely to matter this quarter. Policy precision feels like a luxury when you’re scrambling to meet the requirements themselves.
What Vagueness Actually Costs
The short-term calculus makes sense. The long-term cost doesn’t.
I went back and looked at public incidents in the Mozilla CA Program going back to 2018. Across roughly 500 cases, about 70% fall into process and operational failures rather than code-level defects. A large portion trace back to gaps between what an organization actually does and what its documents say it does. The organizations that ultimately lost trust follow a consistent pattern. Documents vague enough to avoid direct contradiction, but too vague to demonstrate that operations stayed within defined parameters. The decay is always gradual. The loss of trust always looks sudden.
The breakdown is telling. Of the four major incident categories, Governance & Compliance failures account for roughly half of all incidents, more than certificate misissuance, revocation failures, and validation errors combined. The primary cause isn’t code bugs or cryptographic weaknesses. It’s administrative oversight. Late audit reports, incomplete analysis, delayed reporting. The stuff that lives in policy documents and process descriptions, not in code.
The distribution looks like this:
This holds outside PKI. The financial institutions that get into the worst trouble with regulators aren’t usually the ones doing something explicitly prohibited. They’re the ones whose internal documentation was too vague to prove they were doing what they claimed. Read the details behind SOX failures, GDPR enforcement actions, and FDA warning letters, and you’ll find the same structural problem. Stated practices didn’t match reality, and nobody caught it because the stated practices were too imprecise to evaluate.
Vagueness also creates operational risk that has nothing to do with regulators. When your own engineering, compliance, and legal teams can’t look at a policy document and know exactly what’s expected, they fill in the gaps with assumptions. Different teams make different assumptions. Practices diverge. The organization thinks it’s operating one way because that’s what the document sort of implies. The reality is something else. And the gap only surfaces when an auditor, a regulator, or an incident forces someone to look closely.
The deeper issue is that vagueness removes auditability as a control surface. When commitments are measurable, deviations surface automatically. A system can check whether a CRL was backdated by more than two hours the same way it checks whether a certificate was issued with the wrong key usage extension. The commitment is binary. It either holds or it doesn’t. When commitments are subjective, deviations become interpretive. “A few hours” can’t be checked by a machine. It can only be argued about by people. That shifts risk detection from systems to negotiation. Negotiation doesn’t scale, produces inconsistent outcomes, and worst of all, it only happens between the auditee and the auditor. The regulators and the public who actually bear the risk aren’t in the room.
That spectrum is the diagnostic. Everything to the right of “machine-checkable” is a gap waiting to be exploited by time pressure, turnover, or organizational drift.
What Would Have to Change
Solving this means treating compliance documentation as infrastructure rather than paperwork. In the same way organizations moved from manual deployments to CI/CD pipelines, compliance needs to move from static documents reviewed annually to living systems verified continuously.
The instinct is to throw AI at it, and that instinct is half right. LLMs are good at ingesting unstructured policy documents. But compliance verification isn’t a search problem. It’s a systematic reasoning problem. You need to trace requirements through hierarchies, exceptions, and precedence rules, then compare them against operational evidence. Recent research shows that RAG-based approaches still hallucinate 17-33% of the time on legal and compliance questions, even with domain-specific retrieval. The failure mode isn’t bad prompting. It’s architectural. You cannot train a model to strictly verify “a few hours” any better than you can train an auditor.
The fix isn’t better retrieval. It’s decomposing complex compliance questions into bounded sub-queries against explicit structures that encode regulatory hierarchy and organizational context, keeping the LLM’s role narrow enough that its errors can be isolated and reviewed.
That means tooling that ingests policy documents and maps commitments to regulatory requirements. Systems that flag language failing basic auditability checks, like temporal bounds described with subjective terms instead of defined thresholds. Automated comparison of stated practices against actual system behavior, running continuously rather than at audit time.
In the Amazon case, a system like this would have caught “a few hours” before it was published. Not because backdating is prohibited, but because the description lacks the specificity needed for anyone to verify compliance with it. The system wouldn’t need to understand CRL semantics. It would just need to know that temporal bounds in operational descriptions require defined, measurable thresholds to be auditable.
Scale that across any compliance domain. Every vague commitment is a gap. Every gap is a place where practice can diverge from documentation without detection. Every undetected divergence is risk accumulating quietly until something forces it into the open.
The Amazon incident is useful because it forced the people who oversee trust decisions to say out loud what has been implicit for years. The bar for documentation specificity is rising, and organizations that optimize for minimal disclosure are optimizing for the wrong thing. That message goes well beyond certificate authorities. The ones that keep diluting their commitments will discover that vagueness isn’t a shield. It’s a slow-moving liability that compounds until it becomes an acute one.
The regulatory environment isn’t going to get simpler. The organizations that treat policy precision as optional will discover that ambiguity scales faster than governance, and that systems which cannot be automatically verified will eventually be manually challenged.
Compliance is a vital sign of organizational health. When it trends the wrong way, it signals deeper problems: processes that can’t be reproduced, controls that exist only on paper, drift accumulating quietly until trust evaporates all at once.
The pattern is predictable. Gradual decay, ignored signals, sudden collapse. Different industries, different frameworks, same structural outcome. (I wrote about this pattern here.)
But something changed. AI is rewriting how software gets built, and compliance hasn’t kept up.
Developers no longer spend their days typing every line. They spend them steering, reviewing, and debugging. AI fills in the patterns, and the humans decide what matters. The baseline of productivity has shifted.
Compliance has not. Its rhythms remain tied to quarterly reviews, annual audits, static documents, and ritualized fire drills. Software races forward at machine speed while compliance plods at audit speed. That mismatch isn’t just inefficient. It guarantees drift, brittleness, and the illusion that collapse comes without warning.
If compliance is the vital sign, how do you measure it at the speed of code?
What follows is not a description of today’s compliance tools. It’s a vision for where compliance infrastructure needs to go. The technology exists. The patterns are proven in adjacent domains. What’s missing is integration. This is the system compliance needs to become.
The Velocity Mismatch
The old world of software was already hard on compliance. Humans writing code line by line could outpace annual audits easily enough. The new world makes the mismatch terminal.
If a third of all production code at the largest software companies is now AI-written, then code volume, change velocity, and dependency churn have all exploded. Modern development operates in hours and minutes, not quarters and years.
Compliance, by contrast, still moves at the speed of filing cabinets. Controls are cross-referenced manually. Policies live in static documents. Audits happen long after the fact, by which point the patient has either recovered or died. By the time anyone checks, the system has already changed again.
Drift follows. Exceptions pile up quietly. Compensating controls are scribbled into risk registers. Documentation diverges from practice. On paper, everything looks fine. In reality, the brakes don’t match the car.
It’s like running a Formula 1 car with horse cart brakes. You might get a few laps in. The car will move, and at first nothing looks wrong. But eventually the brakes fail, and when they do the crash looks sudden. The truth is that failure was inevitable from the moment someone strapped cart parts onto a race car.
Compliance today is a system designed for the pace of yesterday, now yoked to the speed of code. Drift isn’t a bug. It’s baked into the mismatch.
The Integration Gap
Compliance breaks at the integration point. When policies live in Confluence and code lives in version control, drift isn’t a defect. It’s physics. Disconnected systems diverge.
The gap between documentation and reality is where compliance becomes theater. PDFs can claim controls exist while repos tell a different story.
Annual audits sample: pull some code, check some logs, verify some procedures. Sampling only tells you what was true that instant, not whether controls remain in place tomorrow or were there yesterday before auditors arrived.
Eliminate the gap entirely.
Policies as Code
Version control becomes the shared foundation for both code and compliance.
Policies, procedures, runbooks, and playbooks become versioned artifacts in the same system where code lives. Not PDFs stored in SharePoint. Not wiki pages anyone can edit without review. Markdown files in repositories, reviewed through pull requests, with approval workflows and change history. Governance without version control is theater.
When a policy changes, you see the diff. When someone proposes an exception (a documented deviation from policy), it’s a commit with a reviewer. When an auditor asks for the access control policy that was in effect six months ago, you check it out from the repo. The audit trail is the git history. Reproducibility by construction.
Governance artifacts get the same discipline as code. Policies go through PR review. Changes require approvals from designated owners. Every modification is logged, attributed, and traceable. You can’t silently edit the past.
Once policies live in version control, compliance checks run against them automatically. Code and configuration changes get checked against the current policy state as they happen. Not quarterly, not at audit time, but at pull request time.
When policy changes, you immediately see what’s now out of compliance. New PCI requirement lands? The system diffs the old policy against the new one, scans your infrastructure, and surfaces what needs updating. Gap analysis becomes continuous, not an annual fire drill that takes two months and produces a 60-page spreadsheet no one reads.
Risk acceptance becomes explicit and tracked. Not every violation is blocking, but every violation is visible. “We’re accepting this S3 bucket configuration until Q3 migration” becomes a tracked decision in the repo with an owner, an expiration date, and compensating controls. The weighted risk model has teeth because the risk decisions themselves are versioned and auditable.
Monitoring Both Sides of the Gap
Governance requirements evolve. Frameworks update. If you’re not watching, surprises arrive weeks before an audit.
Organizations treat this as inevitable, scrambling when SOC 2 adds trust service criteria or PCI-DSS publishes a new version. The fire drill becomes routine.
But these changes are public. Machines can monitor for updates, parse the diffs, and surface what shifted. Auditors bring surprises. Machines should not.
Combine external monitoring with internal monitoring and you close the loop. When a new requirement lands, you immediately see its impact on your actual code and configuration.
SOC 2 adds a requirement for encryption key rotation every 90 days? The system scans your infrastructure, identifies 12 services that rotate keys annually, and surfaces the gap months ahead. You have time to plan, size the effort, build it into the roadmap.
This transforms compliance from reactive to predictive. You see requirements as they emerge and measure their impact before they become mandatory. The planning horizon extends from weeks to quarters.
From Vibe Coding to Vibe Compliance
Developers have already adapted to AI-augmented work. They call it “vibe coding.” The AI fills in the routine structures and syntax while humans focus on steering, debugging edge cases, and deciding what matters. The job shifted from writing every line to shaping direction. The work moved from typing to choosing.
Compliance will follow the same curve. The rote work gets automated. Mapping requirements across frameworks, checklist validations, evidence collection. AI reads the policy docs, scans the codebase, flags the gaps, suggests remediations. What remains for humans is judgment: Is this evidence meaningful? Is this control reproducible? Is this risk acceptable given these compensating controls?
This doesn’t eliminate compliance professionals any more than AI eliminated engineers. It makes them more valuable. Freed from clerical box-checking, they become what they should have been all along: stewards of resilience rather than producers of audit artifacts.
The output changes too. The goal is no longer just producing an audit report to wave at procurement. The goal is producing telemetry showing whether the organization is actually healthy, whether controls are reproducible, whether drift is accumulating.
Continuous Verification
What does compliance infrastructure look like when it matches the speed of code?
A bot comments on pull requests. A developer changes an AWS IAM policy. Before the PR merges, an automated check runs: does this comply with the principle of least privilege defined in access-control.md? Does it match the approved exception for the analytics service? If not, the PR is flagged. The feedback is immediate, contextual, and actionable.
Deployment gates check compliance before code ships. A service tries to deploy without the required logging configuration. The pipeline fails with a clear message: “This deployment violates audit-logging-policy.md section 3.1. Either add structured logging or file an exception in exceptions/logging-exception-2025-q4.md.”
Dashboards update in real time, not once per quarter. Compliance posture is visible continuously. When drift occurs (when someone disables MFA on a privileged account, or when a certificate approaches expiration without renewal) it shows up immediately, not six months later during an audit.
Weighted risk with explicit compensating controls. Not binary red/green status, but a spectrum: fully compliant, compliant with approved exceptions, non-compliant with compensating controls and documented risk acceptance, non-compliant without mitigation. Boards see the shades of fragility. Practitioners see the specifics. Everyone works from the same signal, rendered at the right level of abstraction.
The Maturity Path
Organizations don’t arrive at this state overnight. Most are still at Stage 1 or earlier, treating governance as static documents disconnected from their systems. The path forward has clear stages:
Stage 1: Baseline. Get policies, procedures, and runbooks into version-controlled repositories. Establish them as ground truth. Stop treating governance as static PDFs. This is where most organizations need to start.
Stage 2: Drift Detection. Automated checks flag when code and configuration diverge from policy. The checks run on-demand or on a schedule. Dashboards show gaps in real time. Compliance teams can see drift as it happens instead of discovering it during an audit. The feedback loop shrinks from months to days. Some organizations have built parts of this, but comprehensive drift detection remains rare.
Stage 3: Integration. Compliance checks move into the developer workflow. Bots comment on pull requests. Deployment pipelines run policy checks before shipping. The feedback loop shrinks from days to minutes. Developers see policy violations in context, in their tools, while changes are still cheap to fix. This is where the technology exists but adoption is still emerging.
Stage 4: Regulatory Watch. The system monitors upstream changes: new SOC 2 criteria, updated PCI-DSS requirements, revised GDPR guidance. When frameworks change, the system diffs the old version against the new, identifies affected controls, maps them to your current policies and infrastructure, and calculates impact. You see the size of the work, the affected systems, and the timeline before it becomes mandatory. Organizations stop firefighting and start planning quarters ahead. This capability is largely aspirational today.
Stage 5: Enforcement. Policies tie directly to what can deploy. Non-compliant changes require explicit exception approval. Risk acceptance decisions are versioned, tracked, and time-bound. The system makes the right path the easy path. Doing the wrong thing is still possible (you can always override) but the override itself becomes evidence, logged and auditable. Few organizations operate at this level today.
This isn’t about replacing human judgment with automation. It’s about making judgment cheaper to exercise. At Stage 1, compliance professionals spend most of their time hunting down evidence. At Stage 5, evidence collection is automatic, and professionals spend their time on the judgment calls: should we accept this risk? Is this compensating control sufficient? Is this policy still appropriate given how the system evolved?
The Objections
There are objections. The most common is that AI hallucinates, so how can you trust it with compliance?
Fair question. Naive AI hallucinates. But humans do too. They misread policies, miss violations, get tired, and skip steps. The compliance professional who spent eight hours mapping requirements across frameworks before lunch makes mistakes in hour nine.
Structured AI with proper constraints works differently. Give it explicit sources, defined schemas, and clear validation rules, and it performs rote work more reliably than most humans. Not because it’s smarter, but because it doesn’t get tired, doesn’t take shortcuts, and checks every line the same way every time.
The bot that flags policy violations isn’t doing unconstrained text generation. It’s diffing your code against a policy document that lives in your repo, following explicit rules, and showing its work: “This violates security-policy.md line 47, committed by [email protected] on 2025-03-15.” That isn’t hallucination. That’s reproducible evidence.
And it scales in ways humans never can. The human compliance team can review 50 pull requests a week if they’re fast. The bot reviews 500. When a new framework requirement drops, the human team takes weeks to manually map old requirements against new ones. The bot does it in minutes.
This isn’t about replacing human judgment. It’s about freeing humans from the rote work where structured AI performs better. Humans hallucinate on routine tasks. Machines don’t. Let machines do what they’re good at so humans can focus on what they’re good at: the judgment calls that actually matter.
The second objection is that tools can’t fix culture. Also true. But tools can make cultural decay visible earlier. They can force uncomfortable truths into the open.
When policies live in repos and compliance checks run on every PR, leadership can’t hide behind dashboards. If the policies say one thing and the code does another, the diff is public. If exceptions are piling up faster than they’re closed, the commit history shows it. If risk acceptance decisions keep getting extended quarter after quarter, the git log is evidence.
The system doesn’t fix culture, but it makes lying harder. Drift becomes visible in real time instead of hiding until audit season. Leaders who want to ignore compliance still can, but they have to do so explicitly, in writing, with attribution. That changes the incentive structure.
Culture won’t be saved by software. But it can’t be saved without seeing what’s real. Telemetry is the prerequisite for accountability.
The Bootstrapping Problem
If organizations are already decaying, if incentives are misaligned and compliance is already theater, how do they adopt this system?
Meet people where they are. Embed compliance in the tools developers already use.
Start with a bot that comments on pull requests. Pick one high-signal policy (the one that came up in the last audit, or the one that keeps getting violated). Write it in Markdown, commit it to a repo, add a simple check that flags violations in PRs. Feedback lands in the PR, where people already work.
This creates immediate value. Faster feedback. Issues caught before they ship. Less time in post-deployment remediation. The bot becomes useful, not bureaucratic overhead.
Once developers see value, expand coverage. Add more policies. Integrate more checks. Build the dashboard that shows posture in real time. Start with the point of maximum pain: the gap between what policies say and what code does.
Make the right thing easier than the wrong thing. That’s how you break equilibrium. Infrastructure change leads culture, not the other way around.
Flipping the Incentive Structure
Continuous compliance telemetry creates opportunities to flip the incentive structure.
The incentive problem is well-known. Corner-cutters get rewarded with velocity and lower costs. The people who invest in resilience pay the price in overhead and friction. By the time the bill comes due, the corner-cutters have moved on.
What if good compliance became economically advantageous in real time, not just insurance against future collapse?
Real-time, auditable telemetry makes compliance visible in ways annual reports never can. A cyber insurer can consume your compliance posture continuously instead of relying on a point-in-time questionnaire. Organizations that maintain strong controls get lower premiums. Rates adjust dynamically based on drift. Offer visibility into the metrics that matter and get buy-down points in return.
Customer due diligence changes shape. Vendor risk assessments that take weeks and rely on stale SOC 2 reports become real-time visibility into current compliance posture. Procurement accelerates. Contract cycles compress. Organizations that can demonstrate continuous control have competitive advantage.
Auditors spend less time collecting evidence and more time evaluating controls. When continuous compliance is demonstrable, scope reduces, costs drop, cycles shorten.
Partner onboarding that used to require months of back-and-forth security reviews happens faster when telemetry is already available. Certifications and integrations move at the speed of verification, not documentation.
The incentive structure inverts. Organizations that build continuous compliance infrastructure get rewarded immediately: lower insurance costs, faster sales cycles, reduced audit expense, easier partnerships. The people who maintain strong controls see economic benefit now, not just avoided pain later.
This is how you fix the incentive problem at scale. Make good compliance economically rational today.
The Choice Ahead
AI has already made coding a collaboration between people and machines. Compliance is next.
The routine work will become automated, fast, and good enough for the basics. That change is inevitable. The real question is what we do with the time it frees up.
Stop there, and compliance becomes theater with better graphics. Dashboards that look impressive but still tell you little about resilience.
Go further, and compliance becomes what it should have been all along: telemetry about reproducibility. A vital sign of whether the organization can sustain discipline when it matters. An early warning system that makes collapse look gradual instead of sudden.
If compliance was the vital sign of organizational decay, then this is the operating system that measures it at the speed of code.
The frameworks aren’t broken. The incentives are. The rhythms are. The integration is.
The technology to build this system exists. Version control is mature. CI/CD pipelines are ubiquitous. AI can parse policies and scan code. What’s missing is stitching the pieces together and treating compliance like production.
Compliance will change. The only question is whether it catches up to code or keeps trailing it until collapse looks sudden.
Security used to be something we tried to bolt on to inherently insecure systems. In the 1990s, many believed that if we simply patched enough holes and set up enough firewalls, we could protect almost anything. Today, hard-won experience has shown that secure-by-design is the only sustainable path forward. Rather than treating security as an afterthought, we need to bake it into a system’s very foundation—from its initial design to its day-to-day operation.
Yet even the best security technology can fail to catch on if no one understands its value. In my time in the field I’ve seen a recurring theme: great solutions often falter because they aren’t communicated effectively to the right audiences. Whether you’re a security entrepreneur, an in-house security architect, or part of a larger development team, you’ll likely need to equip three distinct groups with the right messaging: the Technical Champion, the Economic Buyer, and the Broader Market. If any of them fail to see why—and how—your solution matters, momentum stalls.
From Bolt-On to Secure-by-Design
The security industry has undergone a massive shift, moving away from the idea that you can simply bolt on protection to an already flawed system. Instead, we now realize that security must be designed in from the start. This demands a lifecycle approach—it’s not enough to fix bugs after deployment or put a facade in front of a service. We have to consider how software is built, tested, deployed, and maintained over time.
This evolution requires cultural change: security can’t just live in a silo; it has to be woven into product development, operations, and even business strategy. Perhaps most importantly, we’ve learned that people, processes, and communication strategies are just as important as technology choices.
This shift has raised the bar. It’s no longer sufficient to show that your solution works; you must show how it seamlessly integrates into existing workflows, consider the entire use lifecycle, supports future needs, and gets buy-in across multiple levels of an organization.
The Three Audiences You Need to Win Over
The Technical Champion (80% Tech / 20% Business)
Your security solution will often catch the eye of a deeply technical person first. This might be a security engineer who’s tired of patching the same vulnerabilities or a software architect who sees design flaws that keep repeating. They’re your first and most crucial ally.
Technical champions need more than promises—they need proof. They want detailed demos showing real-world scenarios, sample configurations they can experiment with, and pilot environments where they can test thoroughly. Give them architecture diagrams that satisfy their technical depth, comprehensive documentation that anticipates their questions, and a clear roadmap showing how you’ll address emerging threats and scale for future needs.
Integration concerns keep champions awake at night. They need to understand exactly how your solution will mesh with existing systems, what the deployment strategy looks like, and who owns responsibility for updates and patches. Address their concerns about learning curves head-on with clear documentation and practical migration paths.
While technology drives their interest, champions eventually have to justify their choices to management. Give them a concise one-pager that frames the returns in business terms: reduced incident response time, prevented security gaps, and automated fixes that save precious engineer hours.
Why This Matters: When you equip your champion with the right resources, they become heroes inside their organizations. They’re the one who discovered that crucial solution before a major breach, who saved the team countless hours of manual work, who saw the strategic threat before anyone else. That kind of impact directly translates to recognition, promotions, and career advancement. The champion who successfully implements a game-changing security solution often becomes the go-to expert, earning both peer respect and management attention. When you help a champion shine like this, they’ll pull your solution along with them as they climb the organizational ladder.
The Economic Buyer (20% Tech / 80% Business)
A passionate champion isn’t always the one holding the purse strings. Often, budget is controlled by directors, VPs, or executives who juggle competing priorities and are measured by overall business outcomes, not technical elegance.
Your buyer needs a concise, compelling story about how this investment reduces risk, saves costs, or positions the company advantageously. Frame everything in terms of bottom-line impact: quantifiable labor hours saved, reduced compliance burdens, and concrete return on investment timelines.
Even without extensive case studies, you can build confidence through hypothetical or pilot data. Paint a clear picture: “Similar environments have seen 30% reduction in incident response time” or “Based on initial testing, we project 40% fewer false positives.” Consider proposing a small pilot or staged rollout—once they see quick wins scaling up becomes an easier sell.
Why This Matters: When buyers successfully champion a security solution, they transform from budget gatekeepers into strategic leaders in the eyes of executive management. They become known as the one who not only protected the company but showed real business vision. This reputation for combining security insight with business acumen often fast-tracks their career progression. A buyer who can consistently tell compelling business stories—especially about transformative security investments—quickly gets noticed by the C-suite. By helping them achieve these wins, you’re not just securing a deal; you’re empowering their journey to higher organizational levels. And as they advance, they’ll bring your solution with them to every new role and company they touch.
The Broader Market: Present, Teach, and Farm
While winning over individual champions and buyers is crucial, certain security approaches need industry-wide acceptance to truly succeed. Think of encryption standards, identity protocols, and AI based security research tools—these changed the world only after enough people, in multiple communities, embraced them.
Build visibility through consistent conference presentations, industry webinars, and local security meetups. Even with novel technologies, walking people through hypothetical deployments or pilot results builds confidence. Panels and Q&A sessions demonstrate your openness to tough questions and deep understanding of the problems you’re solving.
Make your message easy to spread and digest. While detailed whitepapers have their place, supplement them with short video demonstrations, clear infographics, and focused blog posts that capture your solution’s essence quickly. Sometimes a two-minute video demonstration or one-page technical overview sparks more interest than an extensive document.
Think of education as planting seeds—not every seed sprouts immediately, but consistent knowledge sharing shapes how an entire field thinks about security over time. Engage thoughtfully on social media, address skepticism head-on, and highlight relevant use cases that resonate with industry trends. Consider aligning with open-source projects, industry consortiums, or standards bodies to amplify your reach.
Why This Matters: By consistently educating and contributing to the community dialogue, you create opportunities for everyone involved to shine. Your champions become recognized thought leaders, speaking at major conferences about their successful implementations. Your buyers get profiled in industry publications for their strategic vision. Your early adopters become the experts everyone else consults. This creates a powerful feedback loop where community advocacy not only drives adoption but establishes reputations and advances careers. The security professionals who help establish new industry norms often find themselves leading the next wave of innovation—and they remember who helped them get there.
Overcoming Common Challenges
The “Not Invented Here” Mindset
Security professionals excel at finding flaws, tearing down systems, and building their own solutions. While this breaker mindset is valuable for discovering vulnerabilities, it can lead to the “Not Invented Here” syndrome: a belief that external solutions can’t possibly be as good as something built in-house.
The key is acknowledging and respecting this culture. Offer ways for teams to test, audit, or customize your solution so it doesn’t feel like an opaque black box. Show them how your dedicated support, updates, and roadmap maintenance can actually free their talent to focus on unique, high-value problems instead of maintaining yet another in-house tool.
Position yourself as a partner rather than a replacement. Your goal isn’t to diminish their expertise—it’s to provide specialized capabilities that complement their strengths. When teams see how your solution lets them focus on strategic priorities instead of routine maintenance, resistance often transforms into enthusiasm.
The Platform vs. Product Dilemma
A common pitfall in security (and tech in general) is trying to build a comprehensive platform before solving a single, specific problem. While platforms can be powerful, they require critical mass and broad ecosystem support to succeed. Many promising solutions have faltered by trying to do too much too soon.
Instead, focus on addressing one pressing need exceptionally well. This approach lets you deliver value quickly and build credibility through concrete wins. Once you’ve proven your worth in a specific area, you can naturally expand into adjacent problems. You might have a grand vision for a security platform, but keep your initial messaging focused on immediate, tangible benefits.
Navigating Cross-Organizational Dependencies
Cross-team dynamics can derail implementations in two common ways: operational questions like “Who will manage the database?” and adoption misalignment where one team (like Compliance) holds the budget while another (like Engineering) must use the solution. Either can stall deals for months.
Design your proof of value (POV) deployments to minimize cross-team dependencies. The faster a champion can demonstrate value without requiring multiple department sign-offs, the better. Start small within a single team’s control, then scale across organizational boundaries as value is proven.
Understand ownership boundaries early: Who handles infrastructure? Deployment? Access control? Incident response? What security and operational checklists must be met for production? Help your champion map these responsibilities to speed implementation and navigate political waters.
The Timing and Budget Challenge
Success often depends on engaging at the right time in the organization’s budgeting cycle. Either align with existing budget line items or engage early enough to help secure new ones through education. Otherwise, your champion may be stuck trying to spend someone else’s budget—a path that rarely succeeds. Remember that budget processes in large organizations can take 6-12 months, so timing your engagement is crucial.
The Production Readiness Gap
A signed deal isn’t the finish line—it’s where the real work begins. Without successful production deployment, you won’t get renewals and often can’t recognize revenue. Know your readiness for the scale requirements of target customers before engaging deeply in sales.
Be honest about your production readiness. Can you handle their volume? Meet their SLAs? Support their compliance requirements? Have you tested at similar scale? If not, you risk burning valuable market trust and champion relationships. Sometimes the best strategy is declining opportunities until you’re truly ready for that tier of customer.
Having a clear path from POV to production is critical. Document your readiness criteria, reference architectures, and scaling capabilities. Help champions understand and navigate the journey from pilot to full deployment. Remember: a successful small customer in production is often more valuable than a large customer stuck in pilot or never deploys into production and does not renew.
Overcoming Entrenched Solutions
One of the toughest challenges isn’t technical—it’s navigating around those whose roles are built on maintaining the status quo. Even when existing solutions have clear gaps (like secrets being unprotected 99% of their lifecycle), the facts often don’t matter because someone’s job security depends on not acknowledging them.
This requires a careful balance. Rather than directly challenging the current approach, focus on complementing and expanding their security coverage. Position your solution as helping them achieve their broader mission of protecting the organization, not replacing their existing responsibilities. Show how they can evolve their role alongside your solution, becoming the champion of a more comprehensive security strategy rather than just maintaining the current tools.
Putting It All Together
After three decades in security, one insight stands out: success depends as much on communication as on code. You might have the most innovative approach, the sleekest dashboard, or a bulletproof protocol—but if nobody can articulate its value to decision-makers and colleagues, it might remain stuck at the proof-of-concept stage or sitting on a shelf.
Your technical champion needs robust materials and sufficient business context to advocate internally. Your economic buyer needs clear, ROI-focused narratives supported by concrete outcomes. And the broader market needs consistent education through various channels to understand and embrace new approaches.
Stay mindful of cultural barriers like “Not Invented Here” and resist the urge to solve everything at once. Focus on practical use cases, maintain consistent messaging across audiences, and show how each stakeholder personally benefits from your solution. This transforms curiosity into momentum, driving not just adoption but industry evolution.
Take a moment to assess your approach: Have you given your champion everything needed to succeed—technical depth, migration guidance, and business context? Does your buyer have a compelling, ROI-focused pitch built on solid data? Are you effectively sharing your story with the broader market through multiple channels?
If you’re missing any of these elements, now is the time to refine your strategy. By engaging these three audiences effectively, addressing cultural barriers directly, and maintaining focus on tangible problems, you’ll help advance security one success story at a time.
Account recovery is where authentication systems go to die. We build sophisticated authentication using FIDO2, WebAuthn, and passkeys, then use “click this email link to reset” when something goes wrong. Or if we are an enterprise, we spend millions staffing help desks to verify identity through caller ID and security questions that barely worked in 2005.
This contradiction runs deep in digital identity. Organizations that require hardware tokens and biometrics for login will happily reset accounts based on a hope and a prayer. These companies that spend fortunes on authentication will rely on “mother’s maiden name” or a text message of a “magic number” for recovery. Increasingly we’ve got bank-vault front doors with screen-door back entrances.
The Government Solution
But there’s an interesting solution emerging from an unexpected place: government identity standards. Not because governments are suddenly great at technology, but because they’ve been quietly solving something harder than technology – how to agree on how to verify identity across borders and jurisdictions.
The European Union is pushing ahead with cross-border digital identity wallets based on their own standards. At the same time, a growing number of U.S. states—early adopters like California, Arizona, Colorado, and Utah—are piloting and implementing mobile driver’s licenses (mDLs). These mDLs aren’t just apps showing a photo ID; they’re essentially virtual smart cards, containing a “certificate” of sorts that is used to attest to certain information about you, similar to what happens with electronic reading of passports and federal CAC cards. Each of these mDL “certificates” are cryptographically traceable back to the issuing authority’s root of trust, creating verifiable chains of who is attesting to these attributes.
One of the companies helping make this happen is SpruceID, a company I advise. They have been doing the heavy lifting to enable governments and commercial agencies to accomplish these scenarios, paving the way for a more robust and secure digital identity ecosystem.
Modern Threats and Solutions
What makes this particularly relevant in 2024 is how it addresses emerging threats. Traditional remote identity verification relies heavily on liveness detection – systems looking at blink patterns, reflections and asking users to turn their heads, or show some other directed motion. But with generative AI advancing rapidly, these methods are becoming increasingly unreliable. Bad actors can now use AI to generate convincing video responses that fool traditional liveness checks. We’re seeing sophisticated attacks that can mimic these patterns the existing systems look at, even the more nuanced subtle facial expressions that once served as reliable markers of human presence.
mDL verification takes a fundamentally different approach. Instead of just checking if a face moves correctly, it verifies cryptographic proofs that link back to government identity infrastructure. Even if an attacker can generate a perfect deepfake video, they can’t forge the cryptographic attestations that come with a legitimate mDL. It’s the difference between checking if someone looks real and verifying they possess cryptographic proof of their identity.
Applications and Implementation
This matters for authentication because it gives us something we’ve never had: a way to reliably verify legal identity during account authentication or recovery that’s backed by the same processes used for official documents. This means that in the future when someone needs to recover account access, they can prove their identity using government-issued credentials that can be cryptographically verified, even in a world where deepfakes are becoming indistinguishable from reality.
The financial sector is already moving on this. Banks are starting to look at how they can integrate mDL verification into their KYC and AML compliance processes. Instead of manual document checks or easily-spoofed video verification, they will be able to use these to verify customer identity against government infrastructure. The same approaches that let customs agents verify passports electronically will now also be used to enable banks to verify customers.
For high-value transactions, this creates new possibilities. When someone signs a major contract, their mDL can be used to create a derived credential based on the attestations from the mDL about their name, age, and other artifacts. This derived credential could be an X.509 certificate binding their legal identity to the signature. This creates a provable link between the signer’s government-verified identity and the document – something that’s been remarkably hard to achieve digitally.
Technical Framework
The exciting thing isn’t the digital ID – they have been around a while – it’s the support for an online presentment protocol. ISO/IEC TS 18013-7 doesn’t just specify how to make digital IDs; it defines how these credentials can be reliably presented and verified online. This is crucial because remote verification has always been the Achilles’ heel of identity systems. How do you know someone isn’t just showing you a video or a photo of a fake ID? The standard addresses these challenges through a combination of cryptographic proofs and real-time challenge-response protocols that are resistant to replay attacks and deep fakes.
Government benefits show another critical use case. Benefits systems face a dual challenge: preventing fraud while ensuring legitimate access. mDL verification lets agencies validate both identity and residency through cryptographically signed government credentials. The same approach that proves your identity for a passport electronically at the TSA can prove your eligibility for benefits online. But unlike physical ID checks or basic document uploads, these verifications are resistant to the kind of sophisticated fraud we’re seeing with AI-generated documents and deepfake videos.
What’s more, major browsers are beginning to implement these standards as a first-class citizen. This means that verification of these digital equivalents of our physical identities will be natively supported by the web, ensuring that online interactions—from logging in to account recovery—are more easier and more secure than ever before.
Privacy and Future Applications
These mDLs have interesting privacy properties too. The standards support selective disclosure – proving you’re over 21 without showing your birth date, or verifying residency without exposing your address. You can’t do that with a physical ID card. More importantly, these privacy features work remotely – you can prove specific attributes about yourself online without exposing unnecessary personal information or risking your entire identity being captured and replayed by attackers.
We’re going to see this play out in sensitive scenarios like estate access. Imagine a case when someone needs to access a deceased partner’s accounts, they can prove their identity and when combined with other documents like marriage certificates and death certificates, they will be able to prove their entitlement to access that bank account without the overhead and complexity they need today. Some day we can even imagine those supporting documents to be in these wallets also, making it even easier.
The Path Forward
While the path from here to there is long and there are a lot of hurdles to get over, we are clearly on a path where this does happen. We will have standardized, government-backed identity verification that works across borders and jurisdictions. Not by replacing existing authentication systems, but by providing them with a stronger foundation for identity verification and recovery and remote identity verification – one that works even as AI makes traditional verification methods increasingly unreliable.
We’re moving from a world of island of identity systems to one with standardized and federated identity infrastructure, built on the same trust frameworks that back our most important physical credentials. And ironically, at least in the US it started with making driver’s licenses digital.
QR codes are everywhere—tickets, ID cards, product packaging, menus, and even Wi-Fi setups. They’ve become a cornerstone of convenience, and most of us scan them without hesitation. But here’s the thing: most QR codes aren’t cryptographically signed. In practice, this means we’re trusting their contents without any way to confirm they’re authentic or haven’t been tampered with.
One reason QR codes are so useful is their data density. They can store much more information than simpler formats like barcodes, making them ideal for embedding cryptographic metadata, references, or signatures while remaining scannable. However, QR codes have size limits, which means the cryptographic overhead for signing needs to be carefully managed to maintain usability.
While unauthenticated QR codes are fine for low-stakes uses like menus, relying on them for sensitive applications introduces risk. Verifiable QR codes use cryptographic signatures to add trust and security, ensuring authenticity and integrity—even in a post-quantum future.
How Are Verifiable QR Codes Different?
The key difference lies in cryptographic signatures. Verifiable QR codes use them to achieve two things:
Authentication: They prove the QR code was generated by a specific, identifiable source.
Integrity: They ensure the data in the QR code hasn’t been altered after its creation.
This makes verifiable QR codes especially useful in scenarios where trust is critical. For instance, an ID card might contain a QR code with a cryptographic signature over its MRZ (Machine Readable Zone). If someone tampers with the MRZ, the signature becomes invalid, making forgery far more difficult.
Why Think About Post-Quantum Security Now?
Many systems already use signed QR codes for ticketing, identity verification, or supply chain tracking. However, these systems often rely on classical cryptographic algorithms like RSA or ECDSA, which are vulnerable to quantum attacks. Once quantum computers become practical, they could break these signatures, leaving QR codes open to forgery.
That’s where post-quantum cryptography (PQC) comes in. PQC algorithms are designed to resist quantum attacks, ensuring the systems we rely on today remain secure in the future. For QR codes, where size constraints matter, algorithms like UOV and SQISign are especially promising. While most standardized PQC algorithms (like CRYSTALS-Dilithium or Falcon) produce relatively large signatures, UOV and SQISign aim to reduce signature sizes significantly. This makes them better suited for QR codes, which have limited space to accommodate cryptographic overhead.
By adopting post-quantum signatures, verifiable QR codes can address today’s security needs while ensuring long-term resilience in a post-quantum world.
What’s Practical in Implementation?
For verifiable QR codes to work at scale, standard formats and easy-to-use verifiers are essential. Ideally, your smartphone’s default camera should handle verification without requiring extra apps, potentially deep-linking into installed applications. This kind of seamless integration is crucial for widespread adoption.
Verifiable QR codes don’t need to include all the data they validate. Instead, they can store a reference, an identifier, and a cryptographic signature. This approach stays within QR code size limits, accommodating cryptographic overhead while keeping the codes lightweight and usable.
Think of verifiable QR codes as digital certificates. They tie the QR code’s contents back to an issuer within a specific ecosystem, whether it’s a ticketing platform, a supply chain, or an identity system. To build transparency and trust, these signatures could even be logged in a transparency log (tlog), much like Certificate Transparency for web certificates. This would make the issuance of QR codes auditable, ensuring not only the validity of the signature but also when and by whom it was issued.
What About Purely Digital Use Cases?
Even without a physical object like a driver’s license, verifiable QR codes offer significant value. For instance, an online ticket or access pass can prove its issuer and verify its contents with contactless reading. Key benefits include:
Confirming the QR code came from a legitimate issuer (e.g., a trusted ticketing platform).
Ensuring the content hasn’t been altered, reducing phishing or tampering risks.
This assurance is especially critical in digital-only contexts where physical cross-checking isn’t an option, or additional information is needed to verify the object.
Where Verifiable QR Codes Shine
URL-Based QR Codes: Phishing is a growing problem, and QR codes are often used as bait. A verifiable QR code could cryptographically confirm a URL matches its intended domain, letting users know it’s safe before they click—a game-changer for consumers and enterprises.
Identity and Credentials: Driver’s licenses or passports could include QR codes cryptographically tied to their data. Any tampering, digital or physical, would break the signature, making counterfeits easier to detect.
Event Tickets: Ticket fraud costs billions annually. Verifiable QR codes could tie tickets to their issuing authority, allowing limited offline validation while confirming authenticity.
Supply Chain Security: Counterfeiting plagues industries like pharmaceuticals and luxury goods. Signed QR codes on packaging could instantly verify product authenticity without needing centralized databases.
Digital Proof of Vaccination: During the COVID-19 pandemic, QR codes became a common way to share vaccination records. A verifiable QR code would tie the data to an official source, simplifying verification while reducing counterfeit risks at borders, workplaces, or events.
Enhancing Trust in Everyday Interactions
Verifiable QR codes bridge the gap between convenience and trust. By incorporating cryptographic signatures—especially post-quantum ones—they add a necessary layer of security in an increasingly digital world.
While they won’t solve every problem, verifiable QR codes offer a practical way to improve the reliability of systems we already depend on. From verifying tickets and vaccination records to securing supply chains, they provide a scalable and effective solution for building trust into everyday interactions. As verification tools integrate further into devices and platforms, verifiable QR codes could become a cornerstone of authenticity in both physical and digital spaces.
Many enterprise products these days have a core architecture that consists of placing a proxy in front of an existing service. While the facade architecture makes sense in some cases, it’s usually a temporary measure because it increases the costs of administration, scaling, security, and debugging. It also adds complexity to general management.
The use cases for these offerings often involve one team in an organization providing incremental value to a service operated by another team. This introduces various organizational politics, which make anything more than a proof of concept not really viable, at least on an ongoing basis.
Essentially, anyone who has ever carried a pager or tried to deploy even the most basic system in a large enterprise should avoid this pattern except as a stopgap solution for a critical business system. It is far better, in the medium and long term, to look at replacing the fronted system with something that provides the needed integration or capability natively.
For example, some solutions aim to enable existing systems to use quantum-secure algorithms. In practice, these solutions often look like a single TLS server sitting in front of another TLS server, or a TLS-based VPN where a TLS client (for example, integrating via SOCKS) interfaces with your existing TLS client, which then communicates with that TLS server sitting in front of another TLS server. You can, of course, implement this, and there are places where it makes sense. However, on a long-term basis, you would be better off if there were native support for quantum-secure algorithms or switching out the legacy system altogether.
Similarly, it’s very common now for these enterprise-focused solutions to split the architecture between on-premise/private cloud and a SaaS component. This approach has several benefits: the on-premise part enables integration, core policy enforcement, and transaction handling, and, if done right, ensures availability. The SaaS component serves as the control plane. This combination gives you the best benefits of both on-premise and SaaS offerings and can be implemented while minimizing the security impact of the service provider.
Another pattern that might be confused with this model is one where transactional policy enforcement or transaction handling happens in the SaaS part of the solution, while the integration element remains on-premise. This is probably the easiest to deploy, so it goes smoothly in a proof of concept. However, it makes the SaaS component mission-critical, a performance bottleneck, and a single point of failure, while also pulling it entirely into the threat model of the component. There are cases where this model can work, but for any system that needs to scale and be highly reliable, it’s often not the best choice.
These architectural decisions in third-party solutions have other large impacts that need to be considered, such as data residency and compliance. These are especially important topics outside the US but are also issues within the US if you handle sensitive data and work in regulated markets. Beyond that, architecture and design choices of third-party products can have vendor lock-in consequences. For example, if the solution is not based on open standards, you may find yourself in an inescapable situation down the road without a forklift upgrade, which is often not viable organizationally if the solution fails to deliver.
So why does all of this matter? When we evaluate the purchase of enterprise security software, we need to be sure to look beyond the surface, beyond the ingredient list, and understand how the system is built and how those design decisions will impact our security, availability, performance, maintainability and total cost of ownership both in the near term and long term. Enterprise architects and decision-makers should carefully consider these factors when evaluating different architectural patterns.
In the world of certificate lifecycle management for workloads, two approaches often come into focus: ACME (Automated Certificate Management Environment) and SPIFFE (Secure Production Identity Framework for Everyone). While both can deliver certificates to a device or workload, they cater to different use cases. Let’s explore their core differences and why these matter, especially for dynamic workload deployments.
Control Verification: ACME verifies control through various methods such as HTTP-01, DNS-01, TLS-ALPN, and External Account Binding.
Attestation (Optional):Attestation in ACME is secondary and optional, primarily enabling verifying if the key is well protected.
Pre-assigned Identifiers: ACME assumes that the identifier (like a domain name) is pre-assigned and focuses on validating control over this identifier.
This approach is particularly useful for scenarios where identifiers are static and pre-assigned, making it ideal for server authenticated TLS and applications that rely on domain names.
SPIFFE: Dynamic Assignment of Identifier Based on Attestation
SPIFFE, conversely, is designed for dynamic workloads, which frequently change as services scale or update. SPIFFE assigns identifiers to workloads dynamically, based on attestation.
Identifier Assignment: SPIFFE assigns an identifier to the subject (such as a workload) using attestation about the subject to construct this identifier.
Namespacing and Least Privilege: SPIFFE facilitates the namespacing of identifiers, building a foundation that enables authorization frameworks that promote least privilege, ensuring workloads only access necessary resources.
Minimal Security Domains: At the core of SPIFFE is the concept of security domains, which serve as trust boundaries between services, helping to minimize the attack surface.
JWT and X.509: SPIFFE supports SVIDs in both X.509 and JWT formats, enabling seamless integration with various systems and protocols within cloud deployments.
Importance in Dynamic Workload Deployments
The differences between ACME and SPIFFE are particularly significant in dynamic workload deployments:
Flexibility and Scalability: SPIFFE’s dynamic identifier assignment is highly suitable for environments where workloads are frequently spun up and down, such as in microservices architectures and Kubernetes clusters.
Role-Based Authentication: By making attestation a core component and promoting least privilege, SPIFFE ensures that each workload is authenticated and authorized precisely for its intended role.
Granular Policy Enforcement: SPIFFE’s namespacing and minimal security domain features enable fine-grained policy enforcement, enabling organizations to define and enforce policies at a more granular level, such as per-workload or per-service.
Identity Federation: SPIFFE supports identity federation enabling different trust domains to interoperate securely. This is particularly beneficial in multi-cloud and hybrid environments where different parts of an organization or third-parties.
Conclusion
While both ACME and SPIFFE are used for certificate management, they cater to different scenarios and can complement each other effectively. ACME is ideal for static environments where identifiers are pre-allocated, focusing on certificate lifecycle management for issuing, renewing, and revoking certificates. It excels in managing the lifecycle of certificates for web servers and other relatively static resources.
On the other hand, SPIFFE excels in dynamic, high-scale environments, emphasizing credential lifecycle management with flexible and robust authentication and authorization through dynamic identifiers and attestation. SPIFFE is designed for modern, cloud-native architectures where workloads are ephemeral, and identifiers need to be dynamically issued and managed.
By understanding these differences, you can leverage both ACME and SPIFFE to enhance your identity management strategy. Use ACME for managing certificates in static environments to ensure efficient lifecycle management. Deploy SPIFFE for dynamic environments to provide strong, attested identities for your workloads.
In the eIDAS 2.0 framework, the identity wallet is central to its expanded scope, mirroring early European government efforts at smart card-based national identity cards as well as subsequent identity wallet attempts. These efforts saw limited adoption, except for a few cases such as the Estonian national identity card, the Swedish e-identification, and the Dutch eID schemes. It seems that this part of eIDAS 2.0 is an effort to blend the best aspects of these projects with elements of Web3 in an attempt to achieve a uniform solution.
A significant shift from these past identity wallet efforts is the government’s role in identity verification, reminiscent of the earlier smart card national ID initiatives. This approach diverges from the prior identity wallet models, where external entities such as banks, telecoms, and commercial identity verification companies were responsible for verification. This combination potentially helps pave the way for holistic public sector adoption similar to what was seen with Estonia’s national ID project’s success just on a much larger scale.
With that said it is important to remember that the majority of past efforts have struggled to achieve broad adoption. For example, the GOV.UK Verify platform encountered substantial usability issues, leading to resistance and eventually discontinued use by organizations that were mandated to use it. While the software-based nature of identity wallets may reduce deployment costs relative to smart cards, and government mandates could kick-start some level of adoption, the challenge of achieving widespread acceptance does not go away.
As it stands, it does seem that European CAs are betting on this to bootstrap a larger market for themselves. However, in a system as described above, this raises questions about the broader value and future role of third-party trust providers especially in a world where HTTPS on the web is protected with domain-validated certificates that these CAs have largely ignored or resisted.
This brings us to the contentious issue of the eIDAS 2.0 framework’s push for Qualified Web Authentication Certificates (QWACs) and the enforced support by browsers. While it is tempting to look at these two parts of the effort in isolation it is important to remember that regulations like these are made up of horse trading, so it is not surprising to see how clumsily this has all progressed.
As an aside if you have not seen it there was an interesting talk at Chaos Computer Club last month about how badly these identity schemes have been executed that is worth watching. Only time will tell how effectively eIDAS 2.0 navigates these challenges and whether it can achieve the broad adoption that has eluded past initiatives.