The Washington House is now arguing that the sign-in dataset for SB 6346 is unreliable because it contains duplicate names. The claim is simple. If the same name appears more than once, you cannot trust the totals.
They are not wrong that duplicates exist. They are wrong about what duplicates mean and what to do about them.
Every real-world dataset contains noise. Names entered twice, typos, outliers, junk. This is not a scandal. It is a property of data collected from human beings at scale. The standard response is not to discard the dataset. It is to trim it. A trimmed mean, cutting the head or tail or both, is one of the oldest tools in data science. The presence of junk data is not a reason to abandon analysis. It is the reason analysis exists.
The birthday-corrected collision test applied in the previous post is a more principled version of exactly that. Rather than arbitrarily cutting a fixed percentage off the tail, it uses the population model to identify which specific windows are statistically anomalous and removes only those. The legislature is being offered a choice between principled trimming and throwing the whole dataset away. One of those is data science. The other is a talking point.
Why Duplicates Happen
Before getting to the test, it is worth being precise about why duplicates appear in the first place, because the innocent explanations are more common than the fraudulent ones.

Approximately 800 people named John Smith live in Washington state. These are real, distinct individuals.
The first is demographics. According to the U.S. Census Bureau, Smith is the most common surname in America, occurring roughly 828 times per 100,000 people. There are an estimated 32,000 people named John Smith in the United States, approximately 800 in Washington state alone. But national averages miss how name frequency actually works in practice. It clusters by community. Redmond and Bellevue have dense South Asian tech worker populations where Patel and Singh recur at rates far above the state average. Tukwila and south King County have large East African and Somali communities where Mohammed appears with predictable frequency. South Seattle and the Puget Sound corridor have substantial Vietnamese communities where Nguyen, already the most common surname in Vietnam, concentrates heavily. Name frequency is never random. It reflects religion, culture, and family tradition. Mohammed is among the most common names in the world because naming a son after the prophet is an act of Islamic devotion practiced across generations. That is not a data quality problem. The same full name appearing two or three times in 80,000 records is not evidence of anything. It is census math applied to a state that looks nothing like the national average.
The second reason duplicates appear is the sign-in form itself. It does not confirm that your submission was received. Anyone who has filled out a web form and stared at the screen knows what comes next. You submit again. Someone might also change their mind and resubmit to correct their position. A household with two people named Michael Johnson might both sign in independently. None of that is fraud. Both causes are real, and a serious analysis accounts for both.

Beyond that, even if we removed all of the duplicates, it would not even move the needle on the ultimate message being sent. With that said, it is worth noting that CON has more removals in absolute terms because it has ten times as many submissions, which is what we would expect based on the collision test.
On Rapid Submissions
A related claim is that submissions arriving within seconds of each other indicate bot activity. The timing observation is real. The interpretation is not supported by the data available.
Rapid same-name pairs are primarily a function of submission volume. When hundreds of people are submitting per hour, two people who share a name will statistically land within seconds of each other by chance alone. The chart below plots same-name rapid pairs against hourly submission rate for both sides. Both follow the same curve. The PRO overnight Feb 20 hours, at roughly 190 submissions per hour, fall below where the trend predicts they should be, which is consistent with what the collision test found. The timing argument does not add new evidence against PRO. It describes a mathematical property of any high-volume submission window.

The public export contains no IP addresses. Without them, rapid sequential submissions cannot be distinguished between three completely different explanations. The first is a single person double-submitting because the form gave no confirmation. The second is two people in the same household on the same connection. The third is two distinct people with different IPs whose submissions happened to land close together during a busy window.
The tool that would actually resolve this is IP address logs from the server. A same-IP rapid duplicate is strong resubmission evidence. A different-IP rapid duplicate from a residential ISP is two real people. A cluster of submissions from a datacenter or known VPN range is a different finding entirely. None of that analysis is possible from the public CSV, which is the only data anyone outside the AG’s office has seen.
This matters because the “within seconds” framing is being used to support a conclusion the available data cannot reach. The previous post noted that IP logs should be preserved before they age out. That recommendation stands. Until that analysis is done, timing alone is not evidence of anything specific.
It is also worth noting what the pattern does not look like. Unsophisticated bots reuse names, submit in mechanical bursts, and produce timing regularity that shows up clearly in both the collision test and the rapid pairs chart. The PRO Feb 20 overnight shows neither. It shows zero name collisions and below-trend rapid pairs, the opposite of what cheap automation produces. What that pattern is consistent with is a large list of pre-generated unique names submitted at a controlled rate. CAPTCHA does not stop that. Each submission looks like a distinct human from the name and timing perspective. The fix legislators might reach for does not address the threat model the data actually points to.
What the Test Is Measuring
The birthday problem tells you that a room of 23 people has a 50% chance of containing a shared birthday. The same math gives you the expected number of name collisions in any random sample drawn from a community of known size. If you have 9,000 PRO supporters and draw 934 names from that pool, some names will repeat by chance. Not because anyone cheated. Because Jennifer Lee exists in multiples, and because some of them hit submit twice when the page did not respond.
The expected number of collisions for that sample is approximately 60. Not zero. Sixty. The test does not flag duplicates. It asks whether the duplication rate is consistent with what a genuine community would produce.
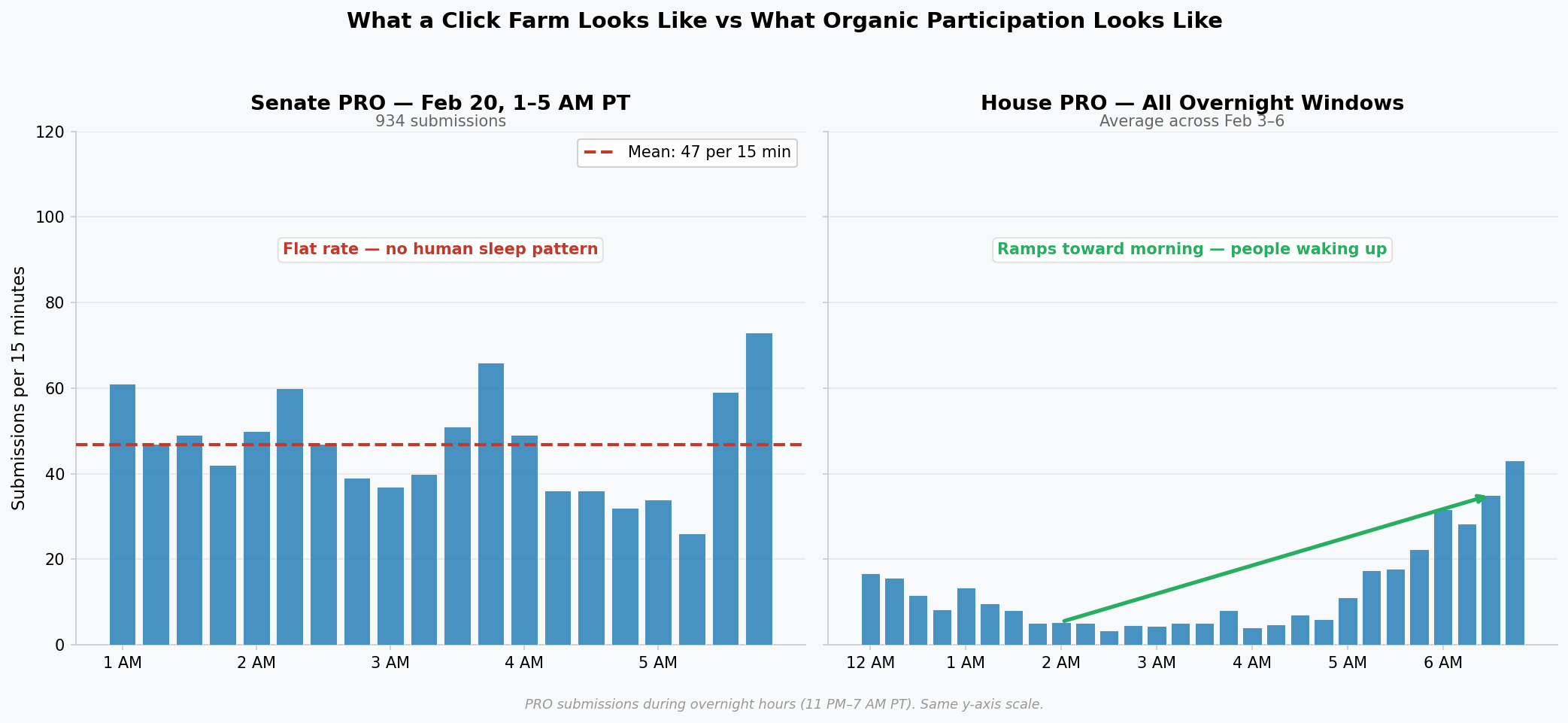
For the Senate PRO February 20th overnight window, the observed collisions were zero. Not fewer than expected. Zero. Across 10,000 simulations drawing from the actual PRO participant pool, the minimum produced was around 30. The overnight batch produced none.

The CON overnight windows tell the opposite story. More collisions than expected across several nights, consistent with resubmission, common names appearing organically, households submitting together. The kind of messy that real participation produces.
What This Means for the Dataset
The argument that duplicates make the dataset unreliable cuts in exactly the wrong direction. The PRO overnight batch from February 20th is anomalous precisely because it has too few duplicates, not too many. A genuine sample from a real community, one that includes people named John Smith and people who hit submit twice, does not produce zero collisions in 934 draws. It is statistically impossible.
Raw duplicate counts, without correcting for population name frequency and sample size, are not a meaningful metric. The legislature is being asked whether these sign-in totals reflect genuine public sentiment, and that is a statistical question with a statistical answer. The answer is not “the dataset has duplicates, therefore we cannot know.” The methodology was built specifically to separate expected duplication from anomalous duplication, and the findings hold.
Discarding the dataset because it contains duplicates is not data analysis. It is avoiding data analysis.
None of this is perfect. IP address analysis would not be definitive because VPNs, shared connections, and mobile carriers complicate attribution. The collision test rests on a population model that is an estimate, not a census. The rapid pairs chart fits a trend to noisy data. Statistical inference is always probabilistic, and anyone who tells you otherwise is selling something.
But the question legislators are actually asking is not whether this dataset is perfect. It is whether the sign-in totals are a reasonable signal of public sentiment, and whether the anomalies identified are significant enough to warrant skepticism about specific windows. For that question, the methodology does not need to be perfect. It needs to be fit for purpose.
A 10:1 ratio that survives deduplication, symmetrical trimming, and a collision test that was explicitly designed to tolerate legitimate duplication is a robust signal. The PRO overnight Feb 20 anomaly does not need to be proven beyond a reasonable doubt to be disqualifying for that window. The standard here is not a criminal conviction. It is whether legislators can treat the aggregate numbers as a directional guide to constituent sentiment. On that standard, the analysis is more than sufficient.
On Impersonation
Named officials discovering their identities appeared in the dataset without their consent is a real incident worth investigating. But the sign-in system was never designed to verify identity or attribute positions to specific individuals. Names are collected not to create a record of who voted, but because a completely anonymous system would be trivially manipulable. A name field is the minimal friction that makes aggregate analysis possible at all.
The relevant question for legislators is not “did John Smith actually sign this?” but “does the distribution of sign-ins reflect genuine public sentiment.” This is a survey mechanism, not a ballot. Washington has 7.8 million residents. Even a perfectly clean dataset with 100,000 CON sign-ins represents a small fraction of the population. Legislators have always understood these numbers as a directional signal, not a binding count. Treating impersonation as the central finding, rather than asking whether the aggregate signal survived manipulation, mistakes the instrument for the measurement.
The numbers behind the impersonation claim deserve scrutiny. Invest in Washington Now reported roughly 100-200 confirmed cases across 123,289 records, less than 0.2% of the dataset. Even tripling that estimate to account for unreported cases, it does not move a 10:1 ratio in any meaningful direction. And if you apply their own deduplication logic symmetrically: remove every name that appears more than once from both sides. CON drops from roughly 110,000 to 91,000 and PRO drops from roughly 10,000 to 9,000. The ratio is still 10:1. Their argument, applied consistently to both sides, does not change the conclusion.
Those confirmed cases were identified because victims self-reported. Public officials monitor mentions of their names, noticed the discrepancy, and came forward. That is the easiest fraud to find. It tells you nothing about what the rest of the dataset contains. Self-reported impersonation is the floor of what happened, not the ceiling, which is precisely why aggregate statistical analysis exists.
It is also worth considering what those confirmed cases likely represent. Some are probably legitimate resubmissions. Someone signed in, was not sure it worked, signed in again, and now appears twice. Some are probably trolling. Actual coordinated impersonation may be in there too, but the self-report mechanism cannot distinguish between the three. Treating 200 high-visibility cases driven by public figures monitoring their own names as representative of the full 123,000-record dataset is not a statistical argument. It is a press conference.
So What Does All of This Mean?
The answer to that is simple. The dataset has duplicates. The timing raised questions. Some names were submitted without consent. None of those observations, examined carefully, change what the data shows: roughly ten Washington residents opposed this bill for every one who supported it in committee. That signal has survived every test applied to it.
Pingback: The Signal They Chose to Ignore | UNMITIGATED RISK