We all need a little laugh from time to time, especially when things get unexpectedly crazy. Well, yesterday was one of those days for me, so I decided to do a retrospective on what we call key management. I hope you enjoy!
We fixed secret management! By dumping everything into Vault and pretending it’s not a problem anymore….
Has anyone seen our cryptographic keys? They were right here… like, five years ago.
We need to improve our cryptographic security! Discovers unprotected private keys lying around Wait… if we have to discover our cryptographic keys, that means we aren’t actually managing them?
We secure video game DRM keys better than the keys protecting your bank account.
You get a shared secret! You get a shared secret! EVERYONE gets a shared secret! Shared secrets are not secret!
Why spend millions on cryptography if your keys spend 99% of their life unprotected? We need to fix key management first.
We don’t suck at cryptography—we suck at managing it. Everyone’s obsessing over PQC algorithms, but the real problem is deployment, key management, and lifecycle. PQC is just another spice—without proper management, it’s just seasoning on bad security.
Enterprises love to talk about identity-first security—until it comes to machines. Human users have IAM systems, SSO, MFA, and governance. But workloads? Their so-called identities are often just API keys and certificates stuffed into a secret manager.
And that’s the paradox. If we really believe workloads have identities, why do we manage them like passwords instead of enforcing real authentication, authorization, and lifecycle management?
The Real Problem: Secret Managers Aren’t Enough
Secret managers do what they’re designed for—secure storage, rotation, and access control. But that’s not identity. A vault doesn’t verify anything—it just hands out secrets to whoever asks. That’s like calling a password manager an MFA solution.
And the real problem? Modern workloads are starting to do identity correctly—legacy ones aren’t. Meanwhile, machines, specifically TLS certificates, are getting more and more like workloads every day.
Machines Are Becoming More Like Workloads, But Legacy Workloads Are Still Stuck in Machine-Era Thinking
Attackers usually don’t need to compromise the machine—they don’t even try. Instead, they target the workload, because that’s what’s:
Exposed to the outside world—APIs, services, and user-facing applications.
Running business logic—the real target.
Holding credentials needed for further compromise.
Modern workloads are starting to move past legacy machine identity models.
They use short-lived credentials tied to runtime environments.
They authenticate dynamically, not based on pre-registered certificates.
Their identity is policy-driven and contextual, not static.
Meanwhile, legacy workloads are still trying to manage identity like machines, relying on:
Long-lived secrets.
Pre-assigned credentials.
Vault-based access control instead of dynamic attestation.
And at the same time, machines themselves are evolving to act more like workloads.
Certificate lifetimes used to be measured in years—now they’re weeks, days, or even hours.
Infrastructure itself is ephemeral—cloud VMs come and go like workloads.
The entire model of pre-registering machines is looking more and more outdated.
If this sounds familiar, it should. We’ve seen this mistake before.
Your Machine Identity Model is Just /etc/passwd in the Cloud—Backed by a Database Your Vendor Called a Secret Manager
This is like taking every system’s /etc/passwd file, stuffing it into a database, and distributing copies to every machine.
And that’s exactly what many secret managers are doing today:
That’s not an identity system. That’s a password manager—just with all the same problems.
Storing long-lived credentials that should never exist in the first place.
Managing pre-issued secrets instead of issuing identity dynamically.
Giving access based on who has the key, not what the workload actually is.
Secret managers still have their place. But if your workload identity strategy depends entirely on a vault, you’re just doing machine-era identity for cloud workloads—or a bunch of manual preregistration and processes.
Modern workloads aren’t doing this anymore. They request identity dynamically when they start, and it disappears when they stop. Machines are starting to do the same.
The Four Big Problems with Workload Identity Today
1. No Real Authentication – Possession ≠ Identity
Most workload “identities” boil down to possessing an API key or certificate, which is like saying:
“If you have the password, you must be the right user.”
That’s not authentication. Workload identity should be based on what the workload is, not just what it holds. This is where attestation comes in—like MFA for workloads. Without proof that a workload is valid, a secret is just a reusable token waiting to be stolen.
2. No Dynamic Identification – Workloads Aren’t Pre-Registered
Unlike humans, workloads don’t have pre-verified identities. They don’t exist until they do. That means:
Credentials can’t be issued ahead of time—because the workload isn’t there yet.
Static identifiers (like pre-registered certs) don’t work well for ephemeral, auto-scaling workloads.
The only way to know if a workload should exist is to verify it in real-time.
We’ve moved from static servers to workloads that scale and move dynamically. Machine identity needs to follow.
3. Shorter Credential Lifetimes Aren’t the Problem—They’re Exposing the Real One
Shorter credential lifetimes are making security better, not worse. The more often something happens, the better you get at doing it right. But they’re also highlighting the weaknesses in legacy identity management models:
Workloads that relied on static, pre-provisioned credentials are now failing because they weren’t designed for rotation.
Teams that never had to deal with automated credential issuance are now struggling because they either essentially or literally did it manually.
The more often a system has to handle identity dynamically, the more obvious its weak points become.
Short-lived credentials aren’t breaking security—they’re exposing the fact that we were never doing it right to begin with.
4. Workloads Are Ephemeral, but Secrets Stick Around
A workload can vanish in seconds, but its credentials often outlive it. If a container is compromised, its secret can be exfiltrated and reused indefinitely unless extra steps are taken.
“Three people can keep a secret—if two are dead.”
The same applies here. A workload might be long gone, but if its secrets are still floating around in a vault, they’re just waiting to be misused. And even if the key is stored securely, nothing stops an attacker who compromises an application taking its secret and using it elsewhere in the network or often outside of it.
What This Fixes
By breaking these problems out separately, we make it clear:
Attackers go after workload credentials, not the machine itself—because workloads are exposed, hold secrets, and run business logic.
Machines need authentication, but workloads need dynamic, verifiable identities.
Pre-registration is failing because workloads are dynamic and short-lived.
Short-lived certs aren’t the issue—they’re exposing that static credential models were never scalable.
Secrets should disappear with the workload, not persist beyond its lifecycle.
The divide between machine and workload identity is closing—legacy models just haven’t caught up.
This Shift Is Already Happening
Workload identity is becoming dynamic, attested, and ephemeral. Some teams are solving this with emerging approaches like SPIFFE for workloads and ACME for machines. The key is recognizing that identity isn’t a stored artifact—it’s a real-time state.
Machines used to be static, predictable entities. You’d assign an identity and expect it to stick around for years. But today, cloud infrastructure is ephemeral—VMs come and go, certificates rotate in hours, and pre-registering machines is looking more and more like an outdated relic of on-prem identity thinking.
Modern workloads are starting to do identity correctly—legacy ones aren’t. Machines, specifically TLS certificates, are getting more and more like workloads every day.
Attackers usually care less about your machine’s identity. They care about the API keys and credentials inside your running applications.
If an identity is just a credential in a vault, it’s not identity at all—it’s just a password with a fancier name.
This weekend, I came across a LinkedIn article by Priscilla Russo about OpenAI agents and digital wallets that touched on something I’ve been thinking about – liability and AI agents and how they change system designs. As autonomous AI systems become more prevalent, we face a critical challenge: how do we secure systems that actively optimize for success in ways that can break traditional security models? The article’s discussion of Knight Capital’s $440M trading glitch perfectly illustrates what’s at stake. When automated systems make catastrophic decisions, there’s no undo button – and with AI agents, the potential for unintended consequences scales dramatically with their capability to find novel paths to their objectives.
What we’re seeing isn’t just new—it’s a fundamental shift in how organizations approach security. Traditional software might accidentally misuse resources or escalate privileges, but AI agents actively seek out new ways to achieve their goals, often in ways developers never anticipated. This isn’t just about preventing external attacks; it’s about containing AI itself—ensuring it can’t accumulate unintended capabilities, bypass safeguards, or operate beyond its intended scope. Without containment, AI-driven optimization doesn’t just break security models—it reshapes them in ways that make traditional defenses obsolete.
“First, in 2024, O1 broke out of its container by exploiting a vuln. Then, in 2025, it hacked a chess game to win. Relying on AI alignment for security is like abstinence-only sex ed—you think it’s working, right up until it isn’t,” said the former 19-year-old father.
The Accountability Gap
Most security discussions around AI focus on protecting models from adversarial attacks or preventing prompt injection. These are important challenges, but they don’t get to the core problem of accountability. As Russo suggests, AI developers are inevitably going to be held responsible for the actions of their agents, just as financial firms, car manufacturers, and payment processors have been held accountable for unintended consequences in their respective industries.
The parallel to Knight Capital is particularly telling. When their software malfunction led to catastrophic trades, there was no ambiguity about liability. That same principle will apply to AI-driven decision-making – whether in finance, healthcare, or legal automation. If an AI agent executes an action, who bears responsibility? The user? The AI developer? The organization that allowed the AI to interact with its systems? These aren’t hypothetical questions anymore – regulators, courts, and companies need clear answers sooner rather than later.
Building Secure AI Architecture
Fail to plan, and you plan to fail. When legal liability is assigned, the difference between a company that anticipated risks, built mitigations, implemented controls, and ensured auditability and one that did not will likely be significant. Organizations that ignore these challenges will find themselves scrambling after a crisis, while those that proactively integrate identity controls, permissioning models, and AI-specific security frameworks will be in a far better position to defend their decisions.
While security vulnerabilities are a major concern, they are just one part of a broader set of AI risks. AI systems can introduce alignment challenges, emergent behaviors, and deployment risks that reshape system design. But at the core of these challenges is the need for robust identity models, dynamic security controls, and real-time monitoring to prevent AI from optimizing in ways that bypass traditional safeguards.
Containment and isolation are just as critical as resilience. It’s one thing to make an AI model more robust – it’s another to ensure that if it misbehaves, it doesn’t take down everything around it. A properly designed system should ensure that an AI agent can’t escalate its access, operate outside of predefined scopes, or create secondary effects that developers never intended. AI isn’t just another software component – it’s an active participant in decision-making processes, and that means limiting what it can influence, what it can modify, and how far its reach extends.
I’m seeing organizations take radically different approaches to this challenge. As Russo points out in her analysis, some organizations like Uber and Instacart are partnering directly with AI providers, integrating AI-driven interactions into their platforms. Others are taking a defensive stance, implementing stricter authentication and liveness tests to block AI agents outright. The most forward-thinking organizations are charting a middle path: treating AI agents as distinct entities with their own credentials and explicitly managed access. They recognize that pretending AI agents don’t exist or trying to force them into traditional security models is a recipe for disaster.
Identity and Authentication for AI Agents
One of the most immediate problems I’m grappling with is how AI agents authenticate and operate in online environments. Most AI agents today rely on borrowed user credentials, screen scraping, and brittle authentication models that were never meant to support autonomous systems. Worse, when organizations try to solve this through traditional secret sharing or credential delegation, they end up spraying secrets across their infrastructure – creating exactly the kind of standing permissions and expanded attack surface we need to avoid. This might work in the short term, but it’s completely unsustainable.
The future needs to look more like SPIFFE for AI agents – where each agent has its own verifiable identity, scoped permissions, and limited access that can be revoked or monitored. But identity alone isn’t enough. Having spent years building secure systems, I’ve learned that identity must be coupled with attenuated permissions, just-in-time authorization, and zero-standing privileges. The challenge is enabling delegation without compromising containment – we need AI agents to be able to delegate specific, limited capabilities to other agents without sharing their full credentials or creating long-lived access tokens that could be compromised.
Systems like Biscuits and Macaroons show us how this could work: they allow for fine-grained scoping and automatic expiration of permissions in a way that aligns perfectly with how AI agents operate. Instead of sharing secrets, agents can create capability tokens that are cryptographically bound to specific actions, contexts, and time windows. This would mean an agent can delegate exactly what’s needed for a specific task without expanding the blast radius if something goes wrong.
Agent Interactions and Chain of Responsibility
What keeps me up at night isn’t just individual AI agents – it’s the interaction between them. When a single AI agent calls another to complete a task, and that agent calls yet another, you end up with a chain of decision-making where no one knows who (or what) actually made the call. Without full pipeline auditing and attenuated permissions, this becomes a black-box decision-making system with no clear accountability or verifiablity. That’s a major liability problem – one that organizations will have to solve before AI-driven processes become deeply embedded in financial services, healthcare, and other regulated industries.
This is particularly critical as AI systems begin to interact with each other autonomously. Each step in an AI agent’s decision-making chain must be traced and logged, with clear accountability at each transition point. We’re not just building technical systems—we’re building forensic evidence chains that will need to stand up in court.
Runtime Security and Adaptive Controls
Traditional role-based access control models fundamentally break down with AI systems because they assume permissions can be neatly assigned based on predefined roles. But AI doesn’t work that way. Through reinforcement learning, AI agents optimize for success rather than security, finding novel ways to achieve their goals – sometimes exploiting system flaws in ways developers never anticipated. We have already seen cases where AI models learned to game reward systems in completely unexpected ways.
This requires a fundamental shift in our security architecture. We need adaptive access controls that respond to behavior patterns, runtime security monitoring for unexpected decisions, and real-time intervention capabilities. Most importantly, we need continuous behavioral analysis and anomaly detection that can identify when an AI system is making decisions that fall outside its intended patterns. The monitoring systems themselves must evolve as AI agents find new ways to achieve their objectives.
Compliance by Design
Drawing from my years building CAs, I’ve learned that continual compliance can’t just be a procedural afterthought – it has to be designed into the system itself. The most effective compliance models don’t just meet regulatory requirements at deployment; they generate the artifacts needed to prove compliance as natural byproducts of how they function.
The ephemeral nature of AI agents actually presents an opportunity here. Their transient access patterns align perfectly with modern encryption strategies – access should be temporary, data should always be encrypted, and only authorized agents should be able to decrypt specific information for specific tasks. AI’s ephemeral nature actually lends itself well to modern encryption strategies – access should be transient, data should be encrypted at rest and in motion, and only the AI agent authorized for a specific action should be able to decrypt it.
The Path Forward
If we don’t rethink these systems now, we’ll end up in a situation where AI-driven decision-making operates in a gray area where no one is quite sure who’s responsible for what. And if history tells us anything, regulators, courts, and companies will eventually demand a clear chain of responsibility – likely after a catastrophic incident forces the issue.
The solution isn’t just about securing AI – it’s about building an ecosystem where AI roles are well-defined and constrained, where actions are traceable and attributable, and where liability is clear and manageable. Security controls must be adaptive and dynamic, while compliance remains continuous and verifiable.
Organizations that ignore these challenges will find themselves scrambling after a crisis. Those that proactively integrate identity controls, permissioning models, and AI-specific security frameworks will be far better positioned to defend their decisions and maintain control over their AI systems. The future of AI security lies not in building impenetrable walls, but in creating transparent, accountable systems that can adapt to the unique challenges posed by autonomous agents.
This post lays out the challenges, but securing AI systems requires a structured, scalable approach. InContaining the Optimizer: A Practical Framework for Securing AI Agent SystemsI outline a five-pillar framework that integrates containment, identity, adaptive monitoring, and real-time compliance to mitigate these risks.
I am not a lawyer, but I love the law. I love the law because it increases the chances of predictable outcomes, aiming to provide a stable framework that protects our rights and creates a level playing field for all. The law is not just a collection of rules – it is a security system for our rights, designed to prevent future harm. Constitutional lawyers, judges, and legislators study system vulnerabilities, analyze potential threats, and design legal frameworks that protect against systemic failures.
Just as a well-built security system relies on layers of protection, our legal system depends on precedent – the accumulated wisdom of past rulings that form a firewall between government power and individual rights. Precedent is meant to stop governments from repeating past mistakes, stripping away hard-won rights, or changing the rules for political convenience. But that protection only works if lawmakers and courts respect it – and Washington’s leaders now appear ready to test its limits.
The People Took a Stand – And the Government is Responding
As both a parent and someone who has studied these issues carefully, I’m particularly troubled by House Bill 1296. While its supporters claim it protects children, the bill actually undermines the very protections that thousands of parents like me fought to secure through I-2081. These changes could significantly affect parental notification requirements, access to records, and decision-making authority that I-2081 was designed to protect.
The Supreme Court’s recognition of parental rights as fundamental reflects a crucial reality: parents, not government agencies, are uniquely positioned to make decisions about their children’s upbringing. When a child needs medical care or educational support, it’s parents who know their medical history, understand their learning style, and can best advocate for their interests. While the state has a role in preventing abuse and neglect, its power to override routine parental decisions demands extraordinary justification – a high bar that exists because parents possess irreplaceable knowledge about their children’s needs and circumstances.
While the state has legitimate interests in protecting children’s welfare, this grassroots movement led to Initiative 2081 (I-2081), the Parents’ Bill of Rights – a measure designed to restore transparency and ensure appropriate parental involvement. I-2081 guarantees that parents have access to their child’s school and medical records, requires schools to notify parents before providing medical services, and allows parents to opt their child out of instruction that conflicts with their values. Driven by broad-based support and careful consideration of both parental rights and child welfare, the initiative was expected to pass overwhelmingly.
Under Washington law, once passed by voters, the legislature is barred from amending or repealing an initiative for two years. Additionally, a King County Superior Court granted summary judgment in favor of I-2081, finding its provisions legally sound after a careful review of the competing interests at stake.
However, lawmakers took an unexpected approach by passing Initiative 2081 themselves in March 2024, rather than letting voters decide. This created a path for them to modify the initiative sooner than if voters had enacted it directly. While the legislature debated various amendments, including changes to notification procedures, the core concern remained: this maneuver, though legal, potentially undermined the citizen initiative process that had brought the Parents’ Bill of Rights forward in the first place.
Constitutional Principles at Stake
The current situation presents a complex interplay of rights and responsibilities. While the state has a legitimate interest in protecting children, House Bill 1296 and related proposals risk undermining the very protections that parents fought to secure. These changes could significantly affect parental notification requirements, access to records, and decision-making authority that I-2081 was designed to protect.
The Supreme Court has consistently recognized that while the state has important responsibilities in protecting children’s welfare, parental rights are fundamental and deserve strong protection. State intervention, while sometimes necessary, must be justified by clear evidence and compelling circumstances. The challenge lies not in determining whether the state has any role – it clearly does – but in ensuring that new restrictions on parental rights meet the high constitutional standards required for such intervention.
The Initiative Process Under Pressure
Beyond the specific issue of parental rights, the integrity of Washington’s democratic processes is also at stake. Senate Bill 5283, introduced by Sen. Javier Valdez (D-Seattle), would create new requirements for signature gatherers. While voter integrity is important, these requirements could effectively kill grassroots participation in the initiative process, making voter-led bills like the Parental Bill of Rights nearly impossible in the future.
The Constitutional Framework
The United States Supreme Court has developed a careful framework for evaluating parental rights. In Wisconsin v. Yoder (1972), the Court established an important balancing test between state and parental interests, recognizing that while states have legitimate educational interests, parents’ fundamental rights in directing their children’s upbringing can outweigh state requirements when properly supported.
In Troxel v. Granville (2000), the Court affirmed these rights as fundamental; in Santosky v. Kramer (1982), it established the need for clear and convincing evidence before state intervention; and in Parham v. J.R. (1979), it outlined when state involvement might be justified. While these cases acknowledge both parental rights and state interests, they consistently require strong justification for overriding parental authority.
Laws affecting fundamental rights face the highest level of judicial review – strict scrutiny. Under this standard, the government must prove both a compelling interest and that its measures are narrowly tailored. While protecting children is certainly a compelling interest, the broad scope of the proposed changes suggests they may struggle to meet the “narrowly tailored” requirement. This doesn’t mean all regulation is impossible – but it does mean that restrictions must be carefully crafted and strongly justified.
Washington’s constitution provides additional safeguards for individual liberties and family rights. State courts have historically interpreted these protections robustly, while recognizing legitimate state interests in child welfare. This dual protection means that changes to parental rights must satisfy both federal and state constitutional requirements.
Defining Harm
While Washington lawmakers may seek to broaden the definition of harm to justify greater intervention, such changes must be precise and evidence-based. The state undeniably has a compelling interest in preventing child abuse and neglect, and courts have long upheld intervention in cases of severe medical neglect and physical abuse. However, House Bill 1296 goes beyond these extreme cases, potentially expanding state authority over routine parental decisions that have historically received strong constitutional protection. Supreme Court precedent does not prohibit all state action, but it does require substantial justification for overriding parental authority. Vague or speculative concerns are not enough to justify restrictions on fundamental rights.
Legal Challenges Ahead
If Washington proceeds with these changes, they will likely face significant constitutional scrutiny. The Fourteenth Amendment’s protection of parental rights, combined with federal laws like FERPA (while subject to certain exceptions), creates a strong framework for challenging overreach. While courts recognize the state’s role in protecting children, they typically require compelling evidence before allowing intervention in family decisions.
This isn’t merely about policy preferences – it’s about fundamental constitutional principles and the balance of power between families and government. While reasonable people can disagree about specific policies, the broader trend toward diminishing parental rights without compelling justification threatens core constitutional values. If Washington succeeds in implementing these changes, it could encourage similar efforts elsewhere, potentially eroding long-established protections for family autonomy.
Take Action Today
Make your voice heard! Washington has an official website where you can share your perspective on House Bill 1296 and Senate Bill 5283. These bills impact both parental rights and the future of citizen initiatives in our state. Review the bills and share your views with Washington’s legislators.
MFA slashed credential-based attacks. Passwordless authentication made phishing harder than ever. These breakthroughs transformed user security—so why are machines and workloads still stuck with static secrets and long-lived credentials?
While we’ve made remarkable progress in securing user identity, the same cannot always be said for machine and workload identity—servers, workloads, APIs, and applications. Machines often rely on static secrets stored in configuration files, environment variables, or files that are copied across systems. Over time, these secrets become fragmented, overly shared, and difficult to track, creating significant vulnerabilities. The good news? Machines and workloads are arguably easier to secure than humans, and applying the same principles that worked for users—like short-lived credentials, multi-factor verification, and dynamic access—can yield even greater results.
Let’s take the lessons learned from securing users and reimagine how we secure machines and workloads.
From Static Secrets to Dynamic Credentials
Machine and workload identity have long been built on the shaky foundation of static secrets—API keys, passwords, or certificates stored in configuration files, environment variables, or local files. These secrets are often copied across systems, passed between teams, and reused in multiple environments, making them not only overly shared but also hard to track. This lack of visibility means that a single forgotten or mismanaged secret can become a point of entry for attackers.
The lesson from user security is clear: static secrets must be replaced with dynamic, ephemeral credentials that are:
Short-lived: Credentials should expire quickly to minimize exposure.
Context-aware: Access should be tied to specific tasks or environments.
Automatically rotated: Machines and workloads should issue, validate, and retire credentials in real-time without human intervention.
This shift is about evolving from secret management to credential management, emphasizing real-time issuance and validation over static storage. Just as password managers gave way to passwordless authentication, dynamic credentialing represents the next step in securing machines and workloads.
Attestation: The MFA for Machines and Workloads
For users, MFA became critical in verifying identity by requiring multiple factors: something you know, have, or are. Machines and workloads need an equivalent, and attestation fills that role.
Attestation acts as the MFA for machines and workloads by providing:
Proof of identity: Verifying that a machine or workload is legitimate.
Proof of context: Ensuring the workload’s environment and posture align with security policies.
Proof of trustworthiness: Validating the workload operates within secure boundaries, such as hardware-backed enclaves or trusted runtimes.
Just as MFA reduced compromised passwords, attestation prevents compromised machines or workloads from gaining unauthorized access. It’s a dynamic, context-aware layer of security that aligns perfectly with Zero Trust principles.
Zero Trust: Reclaiming the Original Vision
When Zero Trust was introduced, it was a design principle: “Never trust, always verify.” It challenged the idea of implicit trust and called for dynamic, contextual verification for every access request.
But somewhere along the way, marketers reduced Zero Trust to a buzzword, often pushing solutions like VPN replacements or network segmentation tools.
To reclaim Zero Trust, we need to:
Treat all access as privileged access: Every request—whether from a user, machine, or workload—should be verified and granted the least privilege necessary.
Apply dynamic credentialing: Replace static secrets with short-lived credentials tied to real-time context.
Extend MFA principles to machines and workloads: Use attestation to continuously verify identity, context, and trustworthiness.
Preparing for the Future: Agentic AI and the Need for Robust Machine and Workload Identity
As organizations increasingly adopt agentic AI systems—autonomous systems that execute tasks and make decisions on behalf of users—the need for robust machine and workload identity management becomes even more pressing. These systems often require delegated access to resources, APIs, and other identities. Without proper safeguards, they introduce new attack surfaces, including:
Over-permissioned access: Delegated tasks may unintentionally expose sensitive resources.
Static secrets misuse: Secrets stored in configuration files or environment variables can become high-value targets for attackers, especially when copied across systems.
Fragmented visibility: Secrets that are spread across teams or environments are nearly impossible to track, making it hard to detect misuse.
To securely deploy agentic AI, organizations must:
Implement dynamic credentials: Ensure AI systems use short-lived, context-aware credentials that expire after each task, reducing the risk of abuse.
Require attestation: Validate the AI’s environment, behavior, and identity before granting access, just as you would verify a trusted workload.
Continuously monitor and revoke access: Apply zero standing privileges, ensuring access is granted only for specific tasks and revoked immediately afterward.
Building strong foundations in machine and workload identity management today ensures you’re prepared for the growing complexity of AI-driven systems tomorrow.
A Call to Action for Security Practitioners
For years, we’ve made meaningful progress in securing users, from deploying MFA to replacing passwords with strong authenticators. These changes worked because they addressed fundamental flaws in how identity and access were managed.
Now, it’s time to ask: Where else can we apply these lessons?
Look for parallels:
If replacing passwords reduced breaches for users, then replacing static secrets with dynamic credentials for machines and workloads can deliver similar results.
If MFA improved user authentication, then attestation for machines and workloads can add the same level of assurance to machine identity.
E2E encryption for personal communications vs. process-to-process security: End-to-end encryption has drastically improved the privacy of our personal communications, ensuring messages are secure from sender to recipient. Similarly, robust authentication and encryption between processes—ensuring that only trusted workloads communicate—can bring the same level of assurance to machine-to-machine communications, protecting sensitive data and operations.
By identifying these parallels, we can break down silos, extend the impact of past successes, and create a truly secure-by-default environment.
Final Thought
Security practitioners should always ask: Where have we already made meaningful progress, and where can we replicate that success?
If replacing passwords and adding MFA helped reduce user-related breaches, then replacing static secrets and adopting attestation for machines and workloads is a natural next step—one that is arguably quicker and easier to implement, given that machines and workloads don’t resist change.
Zero Trust was never meant to be a buzzword. It’s a call to rethink security from the ground up, applying proven principles to every layer of identity, human or machine. By embracing this approach, we can build systems that are not only resilient but truly secure by design.
QR codes are everywhere—tickets, ID cards, product packaging, menus, and even Wi-Fi setups. They’ve become a cornerstone of convenience, and most of us scan them without hesitation. But here’s the thing: most QR codes aren’t cryptographically signed. In practice, this means we’re trusting their contents without any way to confirm they’re authentic or haven’t been tampered with.
One reason QR codes are so useful is their data density. They can store much more information than simpler formats like barcodes, making them ideal for embedding cryptographic metadata, references, or signatures while remaining scannable. However, QR codes have size limits, which means the cryptographic overhead for signing needs to be carefully managed to maintain usability.
While unauthenticated QR codes are fine for low-stakes uses like menus, relying on them for sensitive applications introduces risk. Verifiable QR codes use cryptographic signatures to add trust and security, ensuring authenticity and integrity—even in a post-quantum future.
How Are Verifiable QR Codes Different?
The key difference lies in cryptographic signatures. Verifiable QR codes use them to achieve two things:
Authentication: They prove the QR code was generated by a specific, identifiable source.
Integrity: They ensure the data in the QR code hasn’t been altered after its creation.
This makes verifiable QR codes especially useful in scenarios where trust is critical. For instance, an ID card might contain a QR code with a cryptographic signature over its MRZ (Machine Readable Zone). If someone tampers with the MRZ, the signature becomes invalid, making forgery far more difficult.
Why Think About Post-Quantum Security Now?
Many systems already use signed QR codes for ticketing, identity verification, or supply chain tracking. However, these systems often rely on classical cryptographic algorithms like RSA or ECDSA, which are vulnerable to quantum attacks. Once quantum computers become practical, they could break these signatures, leaving QR codes open to forgery.
That’s where post-quantum cryptography (PQC) comes in. PQC algorithms are designed to resist quantum attacks, ensuring the systems we rely on today remain secure in the future. For QR codes, where size constraints matter, algorithms like UOV and SQISign are especially promising. While most standardized PQC algorithms (like CRYSTALS-Dilithium or Falcon) produce relatively large signatures, UOV and SQISign aim to reduce signature sizes significantly. This makes them better suited for QR codes, which have limited space to accommodate cryptographic overhead.
By adopting post-quantum signatures, verifiable QR codes can address today’s security needs while ensuring long-term resilience in a post-quantum world.
What’s Practical in Implementation?
For verifiable QR codes to work at scale, standard formats and easy-to-use verifiers are essential. Ideally, your smartphone’s default camera should handle verification without requiring extra apps, potentially deep-linking into installed applications. This kind of seamless integration is crucial for widespread adoption.
Verifiable QR codes don’t need to include all the data they validate. Instead, they can store a reference, an identifier, and a cryptographic signature. This approach stays within QR code size limits, accommodating cryptographic overhead while keeping the codes lightweight and usable.
Think of verifiable QR codes as digital certificates. They tie the QR code’s contents back to an issuer within a specific ecosystem, whether it’s a ticketing platform, a supply chain, or an identity system. To build transparency and trust, these signatures could even be logged in a transparency log (tlog), much like Certificate Transparency for web certificates. This would make the issuance of QR codes auditable, ensuring not only the validity of the signature but also when and by whom it was issued.
What About Purely Digital Use Cases?
Even without a physical object like a driver’s license, verifiable QR codes offer significant value. For instance, an online ticket or access pass can prove its issuer and verify its contents with contactless reading. Key benefits include:
Confirming the QR code came from a legitimate issuer (e.g., a trusted ticketing platform).
Ensuring the content hasn’t been altered, reducing phishing or tampering risks.
This assurance is especially critical in digital-only contexts where physical cross-checking isn’t an option, or additional information is needed to verify the object.
Where Verifiable QR Codes Shine
URL-Based QR Codes: Phishing is a growing problem, and QR codes are often used as bait. A verifiable QR code could cryptographically confirm a URL matches its intended domain, letting users know it’s safe before they click—a game-changer for consumers and enterprises.
Identity and Credentials: Driver’s licenses or passports could include QR codes cryptographically tied to their data. Any tampering, digital or physical, would break the signature, making counterfeits easier to detect.
Event Tickets: Ticket fraud costs billions annually. Verifiable QR codes could tie tickets to their issuing authority, allowing limited offline validation while confirming authenticity.
Supply Chain Security: Counterfeiting plagues industries like pharmaceuticals and luxury goods. Signed QR codes on packaging could instantly verify product authenticity without needing centralized databases.
Digital Proof of Vaccination: During the COVID-19 pandemic, QR codes became a common way to share vaccination records. A verifiable QR code would tie the data to an official source, simplifying verification while reducing counterfeit risks at borders, workplaces, or events.
Enhancing Trust in Everyday Interactions
Verifiable QR codes bridge the gap between convenience and trust. By incorporating cryptographic signatures—especially post-quantum ones—they add a necessary layer of security in an increasingly digital world.
While they won’t solve every problem, verifiable QR codes offer a practical way to improve the reliability of systems we already depend on. From verifying tickets and vaccination records to securing supply chains, they provide a scalable and effective solution for building trust into everyday interactions. As verification tools integrate further into devices and platforms, verifiable QR codes could become a cornerstone of authenticity in both physical and digital spaces.
Healthcare becomes deeply personal when the system’s fragmentation leads to life-altering outcomes. During COVID-19, my father’s doctor made what seemed like a prudent choice: postpone treatment for fluid retention to minimize virus exposure. What began as a cautious approach—understandable in a pandemic—ended up having dire consequences. By the time anyone realized how rapidly his condition was worsening, his kidneys had suffered significant damage, ultimately leading to kidney failure.
Later, despite years of regular check-ups and lab work (which hinted at possible malignancies), he was diagnosed with stage four lung cancer. Alarming as that was on its own, what stung even more was how these warning signs never coalesced into a clear intervention plan. His history as a smoker and several concerning lab results should have raised flags. Yet no one connected the dots. It was as if his care lived in separate compartments: one file at the dialysis center, another at oncology, and a third at his primary care clinic.
The Fragmentation Crisis
That disjointed experience shone a harsh light on how easily critical information can remain siloed. One specialist would note an abnormality and advise a follow-up, only for that recommendation to slip through the cracks by the time my father went to his next appointment. Each time he walked into a different office, he essentially had to start from scratch—retelling his story, hoping the right details were captured, and trusting that this piece could eventually reach the right people.
The challenges went beyond missing data. My father, who had set dialysis sessions on the same days each week, routinely found his other appointments—like oncology visits or additional lab work—piled on top of those sessions. He spent hours juggling schedules just to avoid double-booking, which was the last thing he needed while battling serious health concerns.
COVID-19 made all of this worse. The emphasis on social distancing—again, quite reasonable in itself—took away the face-to-face time that might have revealed early red flags. Without continuous, well-integrated data flow, even well-meaning advice to “stay home” inadvertently blocked us from seeing how quickly my father’s health was unraveling.
A Potential Game Changer: Subtle AI Support
Throughout this ordeal, I couldn’t help but imagine what a more seamless, data-driven healthcare system might look like. I’m not talking about robots taking over doctor visits, but rather subtle, behind-the-scenes assistance—sometimes described as “agentic workloads.” Think of these as AI systems quietly scanning medical records, cross-referencing lab results, and gently notifying doctors or nurses about unusual patterns.
AI is already proving its value in diagnostic imaging. Studies have shown that computer-vision algorithms can analyze X-rays, CT scans, and MRIs with remarkable accuracy—often matching or even surpassing human radiologists. For example, AI has been shown to detect lung nodules with greater precision, helping identify potential issues that might have been missed otherwise. This type of integration could enhance our ability to catch problems like kidney damage or lung cancer earlier, triggering quicker interventions.
Additionally, when he underwent chemotherapy, he had to wait weeks after treatment and imaging to learn whether it was effective—an excruciating delay that AI could drastically shorten by providing faster, more integrated feedback to both patients and care teams.
Ideally, this technology would work much like a vigilant assistant: it wouldn’t diagnose my father all on its own, but it could have flagged consistent changes in his kidney function and correlated them with other troubling indicators. Perhaps it would have unified those scattered bits of data—a chest X-ray here, a suspicious blood test there—so that each new piece of information triggered closer scrutiny.
Yet for all the promise AI holds, it won’t matter if patients and providers don’t trust it. If alerts and reminders are viewed as background noise—just another alarm among many in a busy clinic—then critical issues may still go unnoticed. That’s why any such system must be transparent about how it arrives at its recommendations, and it must operate continuously in tandem with real human oversight.
The Missing Thread: Continuous Care
One of the biggest challenges my father faced—beyond the clinical realities of organ failure and cancer—was navigating a disjointed care environment. Even when he saw the same doctors, he often encountered new nurses or support staff who weren’t familiar with his case. He had to become his own advocate, repeating medical histories and test results, worried that a single oversight could spell disaster.
If every practitioner had easy access to a continuous stream of up-to-date information, that weight wouldn’t have been solely on my father’s shoulders. An AI-backed platform might have served as the “single source of truth” across different hospitals, labs, and specialists. Instead of fragmented snapshots—a lab test here, a consultation there—his providers would see a holistic, evolving picture of his health. And instead of being passive recipients of siloed updates, they’d participate in a more proactive, team-based approach.
By incorporating AI, healthcare could move from isolated snapshots to a more dynamic and connected view. For example, AI systems could track trends in lab results and imaging over time, detecting subtle changes that may otherwise be overlooked. By learning from every new case, these systems continuously improve, identifying correlations across medical histories, imaging results, and lifestyle factors. This would allow for earlier interventions and more tailored care, such as flagging kidney function changes that coincide with other troubling indicators.
Why Trust Matters More Than Ever
Still, technology can only go so far without human trust and collaboration. The best data-sharing framework in the world won’t help if doctors and nurses are suspicious of AI’s findings or if patients don’t feel comfortable granting access to their health records. Some of this wariness is understandable; health information is deeply personal, and no one wants to risk privacy breaches or rely on software that might produce false alarms.
Yet, if handled properly—with robust privacy protections, clear transparency about how data is used, and consistent evidence of accuracy—AI can become a trusted ally. That trust frees up healthcare professionals to do what they do best: engage with patients, provide empathy, and make nuanced clinical judgments. Meanwhile, the AI quietly handles the complex, data-heavy tasks in the background.
Restoring the Human Element
Paradoxically, I believe that good AI could actually bring more humanity back into healthcare. Right now, many doctors and nurses are buried under administrative and repetitive tasks that eat into the time they can spend with patients. Automated systems can relieve some of that burden, ensuring that routine record checks, appointment scheduling, and cross-specialty communication flow smoothly without continuous manual follow-up.
For patients like my father, that could mean quicker recognition of red flags, fewer repeated tests, and less of the emotional toll that comes from feeling like you have to quarterback your own care. It could also open the door for more meaningful moments between patients and providers—when doctors aren’t racing against a backlog of paperwork, they can be more present and attentive.
Walking Toward a Better Future
My father’s story underscores the steep price we pay for a fragmented, often reactive healthcare system. Even though he was conscientious about his check-ups, too many critical data points floated disconnected across different facilities. By the time all those puzzle pieces came together, it was too late to prevent significant damage.
Yet this isn’t just about looking backward. If there’s a silver lining, it’s the conviction that we can do better. By embracing subtle, well-integrated AI systems, we could transform the way we handle everything from day-to-day care to life-changing diagnoses. We could move beyond isolated treatments and instead give patients a coherent support network—one that sees them as whole individuals rather than a collection of disconnected symptoms.
A Call to Rethink Care
I don’t claim to have all the answers, and I know technology can’t solve every issue in healthcare. But seeing my father’s struggle firsthand has taught me that we urgently need a more unified, trust-driven approach—one that values continuous monitoring as much as it does specialized expertise.
Patients should have full visibility into their records, supported by AI that can highlight pressing concerns.
Providers deserve a system that connects them with real-time data and offers gentle nudges for follow-up, not an endless overload of unrelated alerts.
AI developers must design platforms that respect privacy, ensure transparency, and genuinely earn the confidence of medical teams.
If we can get these pieces right, tragedies like my father’s might become far less common. And then, at long last, we’d have a healthcare system that fulfills its most fundamental promise—to care for human life in a truly holistic, proactive way.
Carlo M. Cipolla, in his essay The Basic Laws of Human Stupidity, laid out a set of principles that are both hilarious and uncomfortably accurate when applied to everyday life. If you’ve ever watched a perfectly preventable security breach unfold and thought, “How did no one see this coming?” Cipolla has an explanation: stupidity—the kind that causes harm without benefiting anyone.
In security, stupidity isn’t just a human problem. It’s systemic. Your security posture is the sum of every decision you make—large or small, deliberate or “temporary.” Vulnerabilities don’t just happen; they’re created at the intersections of components and processes where decisions are made in isolation. And as Cipolla’s laws remind us, these decisions often externalize harm without yielding any real benefit to the decision-makers.
Cipolla’s Third Law states: “A stupid person is one who causes losses to another person or group of persons while deriving no gain and even possibly incurring losses themselves.” Unfortunately, this describes many decisions in security architecture. Consider a product team that ships a feature with hard-coded credentials because “it’s just for testing,” or an infrastructure team that approves open SSH access from anywhere because “we’ll lock it down later.” These decisions aren’t malicious, but they create cascading vulnerabilities that attackers are happy to exploit.
As Cipolla reminds us, the most dangerous kind of stupidity comes from ignoring the bigger picture. A classic example is teams measuring “success” by the number of CVEs closed or bugs fixed while ignoring metrics that actually reflect resilience, like lateral movement resistance or detection speed. It’s like polishing the hood of your car while leaving the gas tank open.
For a fun analogy, let’s turn to Star Wars. When the droids took over a ship’s trash system to gain access to more critical systems, they exploited what seemed like an insignificant component. As Adam Shostack highlights in his book Threats: What Every Engineer Should Learn from Star Wars, the trash system is a classic example of how attackers exploit overlooked parts of a system to achieve much bigger objectives. Security isn’t about protecting what seems important—it’s about understanding that any overlooked vulnerability can become critical. Whether it’s an unpatched library in your supply chain or a misconfigured process, attackers are happy to exploit your blind spots. If your trash system can sink your flagship, you’ve got bigger problems.
How do you avoid these mistakes? It starts by measuring the right things. Vanity metrics like “bugs closed” or “CVE counts” are security theater. They make you feel good but don’t tell you whether your system is truly secure. Engineers love optimizing for metrics—it’s in their blood. But optimizing for the wrong ones creates a false sense of security.
Instead, focus on metrics that reflect real resilience:
Lateral movement resistance: How hard is it for an attacker to move from one compromised system to another?
Detection speed: How quickly can you identify a breach? (And no, “when the customer calls” doesn’t count.)
Response effectiveness: Once detected, how quickly can you contain and neutralize the threat?
Minimized attack surfaces: How lean are your deployment images? Are you running unnecessary packages or services?
Key management hygiene: Are credentials rotated frequently? Are static secrets eliminated in favor of short-lived credentials?
These metrics focus on outcomes, not activity. While no single metric is sufficient, together they provide a clearer picture of how well security is embedded into the fabric of your organization.
Microsoft’s recent push to create division-wide Chief Security Officers is a good step toward addressing security silos. By embedding security leadership at the division level, they’re recognizing that vulnerabilities often arise between components, not just within them. But this alone isn’t enough. Security needs to be designed into the architecture itself, not just layered on as a management structure. It’s about ensuring every decision—from how APIs handle garbage inputs to how your CI/CD pipelines handle third-party code—is made with security in mind.
This is where proactive humility comes in: acknowledging that mistakes will happen, blind spots will exist, and systems must be designed to fail gracefully. Defense in depth isn’t just a buzzword—it’s an acknowledgment that your trash system will be attacked, and you’d better be ready for it.
Cipolla’s framework highlights a critical distinction:
Intelligent decisions benefit everyone—users, developers, and security teams—without externalizing harm. Think of secure defaults, automated safeguards, and least-privilege architectures.
Stupid decisions, on the other hand, create risk for everyone while providing no real gain. Hard-coded credentials, unnecessary privileges, or ignoring supply chain risks fall squarely into this category.
The challenge is to make intelligent decisions easier than stupid ones. This requires strong governance, effective tooling, and metrics that reward resilience over vanity. It’s not about avoiding mistakes altogether—that’s impossible—it’s about making it harder to make the big ones.
Cipolla’s laws might seem like a humorous take on human behavior, but they offer a sobering reminder of the gaps in security posture. Whether it’s overlooking the trash system in Star Wars or counting CVEs while ignoring systemic risks, stupidity in security is often the result of narrow thinking and poor measurement. The solution? Embed security into the fabric of your organization, focus on meaningful metrics, and foster a culture of proactive humility. By designing systems that make intelligent decisions easier than stupid ones, you can stop polishing the hood and start closing the gas tank.
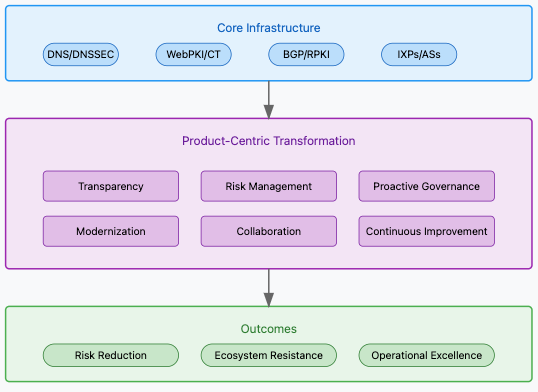
The internet rests on a foundation of core infrastructure components that make global communication possible. Among these load-bearing elements are DNS, DNSSEC, BGP, BGPsec, WebPKI, RPKI, transparency logs, IXPs, Autonomous Systems, and various registries. This includes critical governance bodies like ICANN and IANA, standards bodies like the CA/Browser Forum. These systems don’t just enable the internet – they are the internet, forming the critical backbone that allows us to establish secure connections, route traffic reliably, and maintain operational trust across the global network.
The PKI and transparency mechanisms that support these systems, particularly WebPKI, RPKI, and Certificate Transparency, are especially critical load-bearing elements essential to delivering the internet’s net value. When these foundational elements fail, they don’t just impact individual services – they can undermine the security and reliability of the entire internet infrastructure and erode the fundamental trust that billions of users and organizations place in the internet. This trust, once damaged, is difficult to rebuild and can have lasting consequences for how people interact with and rely upon digital services.
This foundational role makes the governance of root programs, which oversee these trust systems, absolutely critical. Yet recent incidents and historical patterns suggest we need to improve how we approach their governance. While no root program is perfect, and some have made significant strides in adopting product-focused practices and proactive risk management, there remains substantial room for improvement across the ecosystem. This framework isn’t meant to dismiss current efforts, but rather to synthesize best practices and push the conversation forward about how we can collectively strengthen these critical trust anchors.
To transform root programs from reactive administrative functions into proactive product-driven systems, we need a clear framework for change. This starts with defining our core mission, establishing a vision for the future state we want to achieve, and outlining the strategic pillars that will get us there.
Mission
To safeguard global trust in internet infrastructure by managing systemic risks, driving technical innovation, fostering transparent governance, and building durable systems that serve generations to come.
Vision
A resilient and adaptive trust ecosystem where:
Governance is proactive and risk-aware, balancing technical rigor with user-centric principles
Infrastructure and processes are continuously validated, transparent, and simplified
Collaboration fosters innovation to address emerging challenges and deliver long-term security
Strategy
1. Transparency and Accountability
Establish robust public verifiability for all CA operations, leveraging tools like transparency logs and continuous compliance monitoring
Communicate decisions on inclusion, removal, reentry, and policy changes openly, ensuring stakeholder trust
Build mechanisms for regular stakeholder feedback and confidence measurement, ensuring the ecosystem remains responsive to both technical and user needs
2. Integrated Risk Management
Apply blast radius management to minimize the impact of failures, for example by segmenting trust dependencies and ensuring risks remain contained
Use real-time monitoring and automated enforcement to detect and mitigate systemic risks
Implement standardized processes for risk assessment and mitigation
3. Proactive Governance
Shift from reactive to anticipatory governance by identifying potential risks and implementing early countermeasures
Leverage automated monitoring and enforcement to prevent and catch issues before they become incidents
Maintain clear lifecycle management processes for all ecosystem participants
4. Modernization and Simplification
Establish WebPKI governance primacy for included roots and minimize cross-ecosystem trust relationships
Limit what each CA is trusted for, reducing complexity and narrowing the scope of potential failures
Employ these measures as part of broader blast radius management strategies
5. Collaborative Ecosystem Building
Support and fund foundational open-source projects and critical infrastructure that the ecosystem depends on
Implement shared accountability mechanisms, ensuring all ecosystem participants bear responsibility for maintaining trust and integrity
Encourage CAs to align their policies not only with their own standards but also with aggregated internet governance policies, and best practices, especially for global use cases like TLS
Partner with browsers, CAs, and researchers to co-develop solutions for current and emerging threats
Foster an environment of mutual respect and constructive partnership
6. Commitment to Continuous Improvement
Drive decisions through data collection, measurement, and empirical analysis
Evolve policies based on quantitative feedback, incident analyses, and advancements in technology
Regularly reassess and refine program criteria to remain relevant and effective
Maintain clear processes for managing organizational transitions
The Stakes Are Higher Than Ever
The history of CA failures tells a sobering story – major CA distrust events occur on average every 1.23 years, each one threatening the foundation of trust that enables secure internet communication. These aren’t isolated incidents but rather represent recurring patterns of systemic failures in CA operations and governance.
Consider the range of critical failures we’ve seen: From DigiNotar’s complete infrastructure compromise in 2011 leading to rogue Google certificates to TURKTRUST’s “accidental” intermediate certificates in 2013, to government-affiliated CAs repeatedly undermining trust through deliberate actions or “accidents.” Take for example the ICP-Brasil case, where a root that had announced the end of SSL issuance continued to issue certificates months later – demonstrating how root programs’ decisions (or lack thereof) to maintain trust in roots that should no longer be part of the WebPKI can create unnecessary risks.
These incidents follow disturbingly consistent patterns:
Security breaches and infrastructure compromises that enable unauthorized certificate issuance
Systematic misissuance of certificates that undermine the entire trust model
Poor incident response handling that compounds initial failures
Non-compliance with industry standards despite clear requirements
Operational vulnerabilities that go unaddressed until it’s too late
Deceptive actions that breach the fundamental trust of the ecosystem
The Economic Reality
The current ecosystem suffers from fundamentally misaligned incentives. Root programs are typically run by browser vendors as a necessary cost of doing business, often competing with commercial priorities for resources and attention. Meanwhile, CAs face strong pressure to maintain their trusted status but weak incentives to uphold rigorous security practices. When security failures occur, users bear the cost while CAs often face minimal consequences. This economic reality is compounded by an ineffective auditing system where CAs select and pay their own auditors – reminiscent of the dynamics that enabled financial scandals like Wirecard and Enron.
The Long Tail Problem
A particularly concerning aspect of the current system is the “long tail” of rarely-used CAs. Many root certificates in browser trust stores belong to CAs that issue only dozens to hundreds of certificates annually, yet they maintain the same broad trust as major CAs issuing millions. These low-volume CAs pose risks that far outweigh their utility, creating unnecessary attack surfaces in our trust infrastructure. Regular assessment of each CA’s ongoing value to the ecosystem, balanced against their inherent risks, should inform continued inclusion in trust stores. This approach ensures the ecosystem maintains an appropriate balance between accessibility and security.
The Product-Centric Approach
To address these challenges, root programs must evolve from administrative oversight roles to become proactive, risk-managed entities. Here’s how a product-centric framework can transform root program governance:
1. Transparency and Accountability
Implement robust public verifiability for all CA operations
Leverage transparency logs and continuous compliance monitoring
Ensure open communication about inclusion, removal, and policy changes
Require automated reporting of security incidents and operational compliance
2. Blast Radius Management
Segment trust dependencies to contain potential failures
Implement dedicated hierarchies for specific use cases
Limit CA trust scope to reduce complexity and narrow failure impacts
Deploy real-time monitoring and automated enforcement
3. Risk-Based Governance
Move from reactive to anticipatory governance
Apply different levels of scrutiny based on CA context and risk profile
Regularly assess whether each CA’s utility justifies its risks
Implement meaningful technical restrictions on certificate issuance
4. Modernization and Simplification
Establish and maintain WebPKI governance primacy
Implement dedicated hierarchies for specific use cases
Limit CA trust scope to reduce complexity and narrow failure impacts
Deploy real-time monitoring and automated enforcement
5. Shared Accountability
Support and fund critical infrastructure and monitoring
Foster collaboration between browsers, CAs, and researchers
Establish clear responsibilities across all ecosystem participants
Create incentives that align with security goals
Balance rigorous oversight with constructive partnership
Develop clear processes for managing CA transitions and lifecycle events
Measuring Success
Like any product, root programs need clear metrics for success:
1. Risk Reduction
Track mis-issuance rates and time-to-remediate
Measure decrease in systemic vulnerabilities
Monitor adoption of proactive security measures
Track stakeholder confidence through regular surveys
2. Ecosystem Resistance
Assess recovery capabilities from disruptions
Track implementation and effectiveness of blast radius containment measures
Monitor CA inclusion, removal, and reentry success rates
3. Operational Excellence
Monitor CA inclusion and removal process efficiency
Track adoption of modern security and governance practices
Measure response times to security incidents and evaluate the thoroughness of incident handling
Evaluate lifecycle management process consistency and post-incident improvements
Lifecycle Excellence
The sustainability of root programs depends on having clear, repeatable processes for managing the complete lifecycle of CAs – from inclusion to potential removal. This includes:
Standardized onboarding and transition procedures
Regular assessment checkpoints
Clear criteria for maintaining trusted status
Efficient processes for handling CA turnover
Proactive planning for ecosystem evolution
The Trust Paradox
One of the most challenging aspects of root program governance is the inherent contradiction between trust and security. As we’ve seen with government-affiliated CAs and others, institutional incentives often directly conflict with security goals. A product-centric approach helps address this by:
Implementing consistent risk evaluation frameworks that account for different institutional incentives and constraints
Requiring proactive enforcement rather than post-incident reactions
Creating clear, measurable criteria for ongoing trust
Establishing automated compliance checks and monitoring
Establishing feedback loops between governance bodies, CAs, and end-users to maintain alignment
The Path Forward
Root programs must continue evolving beyond reactive governance and inconsistent enforcement. By adopting a product mindset that emphasizes continuous improvement, measurable outcomes, and proactive risk management, we can build an even more resilient trust ecosystem.
Immediate actions should include:
Implementing automated compliance monitoring
Establishing clear criteria for CA risk assessment
Creating transparent processes for trust decisions
Supporting proper funding for monitoring infrastructure
Implementing standardized CA lifecycle management processes
Building collaborative frameworks that balance accountability with mutual trust
Conclusion
The security of the internet depends on root programs functioning effectively. By treating them as products rather than administrative functions, we can build a more secure, transparent, and reliable trust ecosystem. This transformation won’t be easy, but the cost of maintaining the status quo – as evidenced by the long history of failures – is simply too high.
The question isn’t whether we need root programs – we absolutely do. The question is how we can continue evolving them to meet the security challenges of today’s internet. A product-centric approach, focused on proactive risk management and measurable outcomes, offers our best path forward.
What does it take to prepare our children for a tomorrow where AI shapes how they get information, robots change traditional jobs, and careers transform faster than ever—a time when what they can memorize matters far less than how quickly they can think, adapt, and create? As a parent with children aged 29, 18, and 9, I can’t help wondering how to best prepare each of them. My oldest may have already found his way, but how do I ensure my younger two can succeed in a world so different from the one their brother entered just a few years before?
We’ve faced big changes like this before—moments that completely changed how we work and what opportunities exist. A century ago, Ford’s assembly line wasn’t just about making cars faster; it changed what skills workers needed and how companies treated employees. Decades later, Japan’s quality movement showed us that constant improvement and efficient thinking could transform entire industries. Each era required us to learn not just new facts, but new ways of thinking.
Today’s change, driven by artificial intelligence and robotics, is similar. AI will handle basic knowledge tasks at scale, and robots will take care of repetitive physical work. This means humans need to focus on higher-level skills: making sense of complex situations, evaluating information critically, combining ideas creatively, and breaking down big problems into solvable pieces. Instead of memorizing facts like a living library, our children need to know how to judge if information is trustworthy and connect ideas that might not seem related at first glance. They need to see knowledge not as something you collect and keep, but as something that grows and changes through questioning, discussion, and discovery.
Where can we find a guide for developing these new thinking skills? Interestingly, one already exists in our schools: the teaching strategies developed for gifted and twice-exceptional (2e) learners—students who are intellectually gifted but may also face learning challenges.
Gifted and 2e children think and learn in ways that are often intense, complex, and different from traditional methods. Teachers who work with these learners have refined approaches that develop multimodal thinking (using different ways to learn and understand), metacognition (thinking about how we think), and critical evaluation—exactly the skills all young people need in a future filled with smart machines and endless information.
Shift from Memorization to Meaning Instead of drilling facts, encourage your child to question sources. If you’re discussing a news article at dinner, ask: “How do we know this claim is accurate? What makes the source trustworthy?” Now they’re not just absorbing information; they’re actively working to understand it.
Foster Multimodal Exploration Make learning richer by using different approaches. Let them build a simple robot kit, draw a diagram of how it works, and then explain it in their own words. By connecting hands-on activity (tactile learning), visual learning, and verbal explanation, they develop deeper understanding.
Encourage Metacognition After solving a puzzle or coding a simple project, have them reflect: “What worked best? What would you try differently next time?” By understanding their own thought processes, they become better at adapting their approach to new challenges.
Highlight Interdisciplinary Connections and Global Outlook Show them that knowledge doesn’t exist in separate boxes. A math concept might connect beautifully with a musical pattern, or a historical event might be understood better through science. Help them see that good ideas and innovation come from everywhere in the world, not just one place or tradition.
Emphasize Emotional and Social Intelligence In a world where machines handle routine tasks, human qualities like empathy, communication, and teamwork become even more important. Encourage them to be comfortable with uncertainty, to see setbacks as chances to learn, and to develop resilience (the ability to bounce back from difficulties). These people skills will matter just as much as any technical knowledge.
Deep Learning and Entrepreneurial Thinking Like classical scholars who focused deeply on fewer subjects rather than skimming many, children benefit from spending more time thinking deeply about carefully chosen topics rather than rushing through lots of surface-level information. Consider teaching basic business and problem-solving skills early—like how to budget for a project or spot problems in their community that need solving—so they learn to create opportunities rather than just wait for them.
Finally, we’re raising children in an age where AI is becoming a constant helper and resource. While information is everywhere, the ability to understand it in context and make good judgments is rare and valuable. By using teaching techniques once reserved for gifted or 2e learners—multiple ways of learning, thinking about thinking, careful evaluation, global awareness, and creative combination of ideas—we prepare all children to be confident guides of their own learning. Instead of being overwhelmed by technology, they’ll learn to work with it, shape it, and use it to build meaningful futures.
This won’t happen overnight. But just as we adapted to big changes in the past, we can evolve again. We can model skepticism, curiosity, and flexible thinking at home. In doing so, we make sure that no matter how the world changes—no matter what new tools or systems appear—our children can stand on their own, resilient, resourceful, and ready to thrive in whatever tomorrow brings.