Two prior posts worked through the statistics of the SB 6346 sign-in data. In the first I established the methodology and the finding. After applying a birthday-corrected collision test to separate organic participation from anomalous windows, roughly 90,000 legitimate CON participants remain against roughly 9,100 legitimate PRO participants. In the second I addressed the legislature’s claim that duplicate names make the dataset unreliable. The finding runs the other way. A genuine sample drawn from a real community produces name collisions at a predictable rate. People share surnames, people hit submit twice, households have two people with the same name. The PRO overnight batch produced zero collisions across 934 draws, where the statistical minimum expected is around 30. The anomaly is suspicious precisely because it has too few duplicates, not too many. Real participation is messy. This was not.
This post is not about those results. It is about what legislators said about them at a February 24 media availability, and whether their positions are statistically defensible.
They are not.
The Math Problem With “Not Helping Us Make Decisions”
“It’s not like we are making decisions not to pass a bill because of a sign in… they’re not really helping us make decisions in terms of amendments to bills or whether to pass it out of committee or not. We rely on people who actually come and testify in person.”
That is a statistical claim. It asserts that the sign-in data has no decision-relevant information. For that to be true, one of two things must hold. Either the signal is too noisy to be meaningful, or legislators have better information that makes it redundant.
Neither holds.
The 10:1 ratio across 90,000 legitimate responses is not ambiguous. The margin of error at that sample size is roughly a third of a percentage point. The ratio does not wobble under any standard statistical treatment. Even applying the most aggressive self-selection correction anyone has proposed, assuming CON participants are twice as motivated to engage as PRO participants, the adjusted ratio is still 5:1. The signal does not disappear. Calling it noise is not a statistical judgment. It is a refusal to do the math.
As for better information, what would that be? Testimony at a two-hour hearing. Phone calls. Letters. The intuitions of members who have held their seats for multiple cycles. None of those are more statistically rigorous than 90,000 data points. Most are orders of magnitude less rigorous. If a senator’s read of the room outweighs a dataset this large at a ratio this clear, that is not superior methodology. That is substituting anecdote for evidence.
Dhingra’s preferred alternative, people who show up in person, has its own problem. The photo below is from the February 6 Senate hearing. The room is full of people in matching purple shirts and teal sashes. That is coordinated turnout, organized in advance, by people with the resources and flexibility to get to Olympia on a weekday. It is the physical equivalent of a sign-in campaign, except it requires taking a day off work and driving to the state capitol.
That standard also systematically excludes the people most affected by legislation. A small business owner in Spokane worried about a new tax on their income cannot easily testify on a Wednesday. A nurse working a shift cannot. A retired teacher in Yakima cannot. The sign-in system exists precisely because geographic and economic barriers make in-person participation inaccessible to most Washingtonians. Dismissing sign-ins in favor of in-person testimony is not a quality upgrade. It is a substitution of one self-selected sample for a smaller, more organizationally filtered one.
What Statistically Relevant Engagement Actually Looks Like
A standard poll commissioned to gauge public opinion on a major policy question uses around 1,000 respondents. That produces a margin of error of roughly 3.1% at 95% confidence. Those numbers drive legislation, inform campaign strategy, and get cited on the floor. Nobody demands methodology disclosure before a senator cites a Crosscut poll. That is simply the accepted evidentiary standard for constituent sentiment.
The sign-in dataset, after deduplication, contains roughly 90,000 legitimate CON responses. While strict margin of error calculations require randomized polling rather than opt-in data, the mathematical gravity at this scale is inescapable: a random sample of this size would carry a margin of error of approximately 0.33%. This dataset is ninety times larger than what legislators already treat as a reliable signal, with precision ten times tighter.
Washington has approximately 5.5 million registered voters. Ninety thousand responses represents roughly 1.6% of that population engaging with a single bill in committee. In political science research on constituent contact, engagement rates on individual pieces of legislation are typically measured in fractions of a percent. At 1.6%, this dataset is not a rounding error above that baseline. The prior record for sign-ins on any Washington bill was reportedly around 45,000, itself considered extraordinary. This dataset doubled it, and the legislative website crashed under the volume because nothing in the system’s design anticipated engagement at this scale.
The infrastructure of participation failed because the signal exceeded its design limits. That is not a data quality problem. That is evidence of something real happening in the electorate.
To put 90,000 in electoral terms: Washington has 49 legislative districts. Distributed statewide, that averages roughly 1,800 CON sign-ins per district. The 2024 state Senate race in the 10th district was decided by 153 votes. The House race in the 17th district was decided by fewer than 200. Several competitive seats turned on margins smaller than the number of people in those districts who showed up to oppose this bill. Legislators are not dismissing a fringe signal. They are dismissing a constituency that is, in several of their districts, larger than their margin of victory.
Consider how the same legislators would respond to a poll of 1,000 Washingtonians showing 10:1 opposition to a bill. That finding would be treated as dispositive. It would be cited in floor speeches, appear in press releases, and be described as a clear signal of constituent sentiment. This dataset shows the same ratio at ninety times the sample size, with a margin of error ten times tighter, with an audit trail, with a reproducible methodology, and after removing anomalous windows on both sides.
The legislators who called it noise do not apply that standard to anything else they use.
You Don’t Need to Read the Bill
“I don’t think everyone who’s signing in in support or opposition is actually reading the bill. So I think you got to take it for what it’s worth.”
For a technical bill where the title might mislead, that would be a legitimate point. SB 6346 is not that kind of bill. Washington has not had an income tax in nearly a century. Voters have rejected it ten times. For most constituents signing in CON, reading the bill is beside the point. They already know where they stand. The question SB 6346 raises for them is not what the rate structure looks like. It is whether Washington should have an income tax at all, and on that question they have a consistent ninety-year answer. Beyond that settled position, the architects of this legislation documented their strategy in writing years before the bill was introduced.
In April 2018, Senator Jamie Pedersen sent an email to a former Democratic legislator explaining the real value of passing a capital gains tax. The major use of revenue, he wrote, was secondary. The more important benefit was on the legal side. Passing a capital gains tax would give the Supreme Court the opportunity to revisit its decisions that income is property, and would “make it possible to enact a progressive income tax with a simple majority vote.” Those emails were obtained through public records and published by the Washington Policy Center, which also documented the three-step sequence Pedersen described. Pass the capital gains tax to break the legal seal. Pass a millionaires tax to build the administrative infrastructure. Then lower the threshold to capture the middle class.
The capital gains excise passed in 2021. Pedersen also promised the revenue would reduce property and sales taxes. The state collected $1.8 billion in capital gains revenue from 2022 to 2024. Not a dollar went to reducing property or sales taxes. New spending absorbed everything. The Supreme Court upheld the excise in Quinn v. State in 2023, doing precisely what Pedersen predicted. A surcharge was added in 2025. SB 6346 arrived in 2026 as the simple majority vote Pedersen described eight years earlier.
A constituent who signs in CON without reading SB 6346 but who knows this history is not pattern-matching by instinct. They are responding accurately to a documented legislative strategy, now in its final stage, by an architect who wrote down the plan. Trudeau’s concern assumes the sign-in reflects ignorance. The record complicates that assumption.
The federal income tax was introduced in 1913 as a temporary measure with a top rate of 7% on incomes above $500,000. It has been neither temporary nor limited since. A constituent who has watched Washington’s capital gains excise follow the same arc, introduced with tax relief promises that were never kept and expanded within four years, is not being paranoid. They are reading the pattern correctly.
A constituent signing in CON on this bill is not evaluating the mechanics of a 9.9% rate on income above one million dollars. They are evaluating a mechanism with a documented history and a stated long-term purpose. That is not noise. That is the signal working as designed.
The Participation Double Standard
“As a general rule, I always warn my members, you shouldn’t really pay attention to that kind of dialogue… maybe focus less on numbers and more on quality of engagement.”
“Quality of engagement” implies that organized participation is lower quality than spontaneous participation. Applied consistently, that standard would disqualify most of what the same legislators celebrate as democratic infrastructure.
Get out the vote campaigns are organized, at scale, through forwarded links, text banking, social media mobilization, and door knocking. They systematically encourage people to act on issues they may not have independently researched. Nobody argues that a voter who was reminded to register by a campaign text is less legitimate than one who showed up spontaneously. Nobody demands that turnout in heavily canvassed precincts be discounted because the participation was encouraged rather than organic.
The asymmetry is hard to explain on principled grounds. Get out the vote efforts are explicitly designed to shape electoral outcomes, which directly determines who holds legislative power. Organized sign-in campaigns are designed to inform legislators of constituent sentiment on a specific bill, which Jinkins then warns her members not to pay attention to anyway. If one is legitimate democratic infrastructure and the other warrants skepticism, that distinction requires an explanation nobody has offered.
The Self-Selection Argument Does Not Save Them
The legitimate version of the dismissal is astroturfing risk. Organized campaigns can mobilize sign-ins that do not reflect organic sentiment. Two problems follow.
First, the statistical work already addresses it. The anomalies I flagged in those prior posts run against the PRO side, not CON. The CON signal carries the messy collision fingerprint consistent with real people. The organized manipulation concern, applied rigorously and symmetrically, strengthens the CON signal rather than undermining it.
Second, self-selection disqualifies nothing legislators already use. Every constituent signal they rely on is self-selected. Calls. Letters. Town hall attendance. Donations. None represent a random sample of the electorate. The sign-in system is being held to an evidentiary standard that almost no feedback mechanism in democratic practice has met, and that standard is applied to nothing else.
What makes the sign-in data different from those signals is not that it is less reliable. It is that it is more systematic. It produces a record. It is auditable. It generated enough volume to run statistical tests on. The methodology applied here would hold up in a peer-reviewed context. The “I talked to my constituents” alternative would not.
For the underlying sentiment to be actually close to even, CON participants would need to be systematically ten times more motivated to engage through this specific channel than PRO participants. That is not a bias correction. That is a complete reversal of the observed signal. No one has offered a mechanism that produces that result.
The legislators dismissing this data are not applying a rigorous evidentiary standard. They are applying a selective one.
The Broader Pattern
In Disdain or Design? I wrote about what happens to constituent input in Washington when institutional actors have decided on an outcome. The user interface of democracy still renders. The buttons are there. What that piece examined is whether the backend those buttons connect to has been rewired.
The sign-in dismissal is that pattern made unusually explicit. When lawmakers assert that sign-in anomalies damage the ‘democratic process,’ the irony is staggering. The legislature already removed the actual democratic process from this bill by attaching an emergency clause, deliberately blocking the public’s ability to challenge it via referendum. They pre-emptively silenced the electoral signal; now legislative leaders are simply stating on camera that the only constituent participation left is not helping them make decisions.
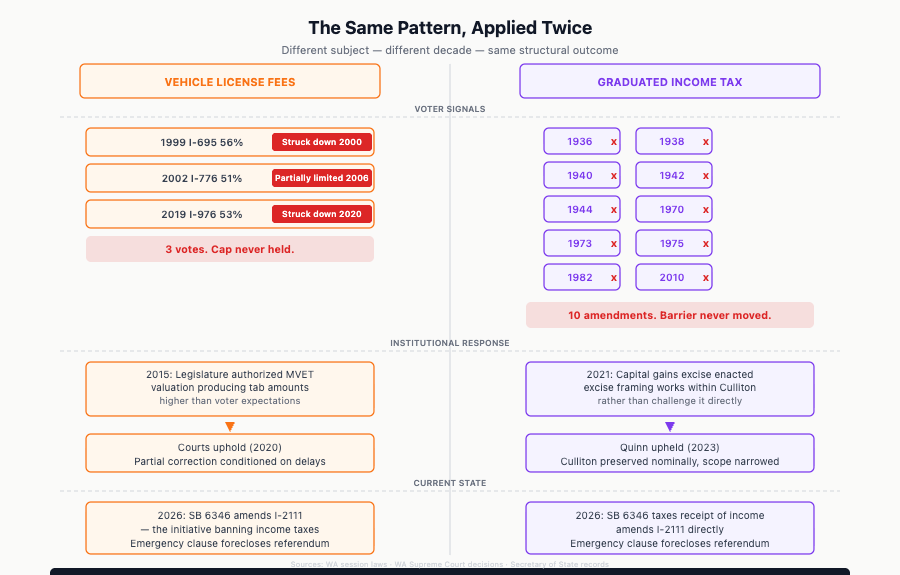
Washington voters have rejected income taxation ten times through the constitutional amendment process. The legislature is effectively circumventing the initiative process that most recently codified that preference. Dismissing the largest constituent response in state legislative history as something members should not pay attention to is not a data science position.
It is a tell about whose input actually shapes the outcome.
The Question That Deserves an Answer
Every signal legislators use to read constituent sentiment is self-selected. Calls. Letters. Town halls. Protests. Donations. Sign-ins are just self-selection at scale, with a paper trail rigorous enough to audit.
It is a perfectly reasonable position to argue that 90,000 highly motivated people clicking a web form do not flawlessly represent the entire state of Washington. But if the legislature genuinely wanted a higher-fidelity democratic signal, they would not have attached an emergency clause to explicitly bypass the voters. And they would not be ignoring a century of bipartisan ballot results where Washingtonians have rejected this exact policy ten separate times.
Legislators are free to make that choice, but voters deserve transparency about it, not a smokescreen of statistical skepticism that the data itself dismantles. When the numbers speak this clearly, ignoring them isn’t methodology; it’s a deliberate unplugging of democracy’s earpiece.
The Washington House is now arguing that the sign-in dataset for SB 6346 is unreliable because it contains duplicate names. The claim is simple. If the same name appears more than once, you cannot trust the totals.
They are not wrong that duplicates exist. They are wrong about what duplicates mean and what to do about them.
Every real-world dataset contains noise. Names entered twice, typos, outliers, junk. This is not a scandal. It is a property of data collected from human beings at scale. The standard response is not to discard the dataset. It is to trim it. A trimmed mean, cutting the head or tail or both, is one of the oldest tools in data science. The presence of junk data is not a reason to abandon analysis. It is the reason analysis exists.
The birthday-corrected collision test applied in the previous post is a more principled version of exactly that. Rather than arbitrarily cutting a fixed percentage off the tail, it uses the population model to identify which specific windows are statistically anomalous and removes only those. The legislature is being offered a choice between principled trimming and throwing the whole dataset away. One of those is data science. The other is a talking point.
Why Duplicates Happen
Before getting to the test, it is worth being precise about why duplicates appear in the first place, because the innocent explanations are more common than the fraudulent ones.
Approximately 800 people named John Smith live in Washington state. These are real, distinct individuals.
The first is demographics. According to the U.S. Census Bureau, Smith is the most common surname in America, occurring roughly 828 times per 100,000 people. There are an estimated 32,000 people named John Smith in the United States, approximately 800 in Washington state alone. But national averages miss how name frequency actually works in practice. It clusters by community. Redmond and Bellevue have dense South Asian tech worker populations where Patel and Singh recur at rates far above the state average. Tukwila and south King County have large East African and Somali communities where Mohammed appears with predictable frequency. South Seattle and the Puget Sound corridor have substantial Vietnamese communities where Nguyen, already the most common surname in Vietnam, concentrates heavily. Name frequency is never random. It reflects religion, culture, and family tradition. Mohammed is among the most common names in the world because naming a son after the prophet is an act of Islamic devotion practiced across generations. That is not a data quality problem. The same full name appearing two or three times in 80,000 records is not evidence of anything. It is census math applied to a state that looks nothing like the national average.
The second reason duplicates appear is the sign-in form itself. It does not confirm that your submission was received. Anyone who has filled out a web form and stared at the screen knows what comes next. You submit again. Someone might also change their mind and resubmit to correct their position. A household with two people named Michael Johnson might both sign in independently. None of that is fraud. Both causes are real, and a serious analysis accounts for both.
Beyond that, even if we removed all of the duplicates, it would not even move the needle on the ultimate message being sent. With that said, it is worth noting that CON has more removals in absolute terms because it has ten times as many submissions, which is what we would expect based on the collision test.
On Rapid Submissions
A related claim is that submissions arriving within seconds of each other indicate bot activity. The timing observation is real. The interpretation is not supported by the data available.
Rapid same-name pairs are primarily a function of submission volume. When hundreds of people are submitting per hour, two people who share a name will statistically land within seconds of each other by chance alone. The chart below plots same-name rapid pairs against hourly submission rate for both sides. Both follow the same curve. The PRO overnight Feb 20 hours, at roughly 190 submissions per hour, fall below where the trend predicts they should be, which is consistent with what the collision test found. The timing argument does not add new evidence against PRO. It describes a mathematical property of any high-volume submission window.
The public export contains no IP addresses. Without them, rapid sequential submissions cannot be distinguished between three completely different explanations. The first is a single person double-submitting because the form gave no confirmation. The second is two people in the same household on the same connection. The third is two distinct people with different IPs whose submissions happened to land close together during a busy window.
The tool that would actually resolve this is IP address logs from the server. A same-IP rapid duplicate is strong resubmission evidence. A different-IP rapid duplicate from a residential ISP is two real people. A cluster of submissions from a datacenter or known VPN range is a different finding entirely. None of that analysis is possible from the public CSV, which is the only data anyone outside the AG’s office has seen.
This matters because the “within seconds” framing is being used to support a conclusion the available data cannot reach. The previous post noted that IP logs should be preserved before they age out. That recommendation stands. Until that analysis is done, timing alone is not evidence of anything specific.
It is also worth noting what the pattern does not look like. It shows zero name collisions and below-trend rapid pairs, the opposite of what cheap automation produces. What that pattern is consistent with is a large list of pre-generated unique names submitted at a controlled rate. CAPTCHA does not stop that. Each submission looks like a distinct human from the name and timing perspective. The fix legislators might reach for does not address the threat model the data actually points to.
What the Test Is Measuring
The birthday problem tells you that a room of 23 people has a 50% chance of containing a shared birthday. The same math gives you the expected number of name collisions in any random sample drawn from a community of known size. If you have 9,000 PRO supporters and draw 934 names from that pool, some names will repeat by chance. Not because anyone cheated. Because Jennifer Lee exists in multiples, and because some of them hit submit twice when the page did not respond.
The expected number of collisions for that sample is approximately 60. Not zero. Sixty. The test does not flag duplicates. It asks whether the duplication rate is consistent with what a genuine community would produce.
For the Senate PRO February 20th overnight window, the observed collisions were zero. Not fewer than expected. Zero. Across 10,000 simulations drawing from the actual PRO participant pool, the minimum produced was around 30. The overnight batch produced none.
The CON overnight windows tell the opposite story. More collisions than expected across several nights, consistent with resubmission, common names appearing organically, households submitting together. The kind of messy that real participation produces.
What This Means for the Dataset
The argument that duplicates make the dataset unreliable cuts in exactly the wrong direction. The PRO overnight batch from February 20th is anomalous precisely because it has too few duplicates, not too many. A genuine sample from a real community, one that includes people named John Smith and people who hit submit twice, does not produce zero collisions in 934 draws. It is statistically impossible.
Raw duplicate counts, without correcting for population name frequency and sample size, are not a meaningful metric. The legislature is being asked whether these sign-in totals reflect genuine public sentiment, and that is a statistical question with a statistical answer. The answer is not “the dataset has duplicates, therefore we cannot know.” The methodology was built specifically to separate expected duplication from anomalous duplication, and the findings hold.
Discarding the dataset because it contains duplicates is not data analysis. It is avoiding data analysis.
None of this is perfect. IP address analysis would not be definitive because VPNs, shared connections, and mobile carriers complicate attribution. The collision test rests on a population model that is an estimate, not a census. The rapid pairs chart fits a trend to noisy data. Statistical inference is always probabilistic, and anyone who tells you otherwise is selling something.
But the question legislators are actually asking is not whether this dataset is perfect. It is whether the sign-in totals are a reasonable signal of public sentiment, and whether the anomalies identified are significant enough to warrant skepticism about specific windows. For that question, the methodology does not need to be perfect. It needs to be fit for purpose.
A 10:1 ratio that survives deduplication, symmetrical trimming, and a collision test that was explicitly designed to tolerate legitimate duplication is a robust signal. The PRO overnight Feb 20 anomaly does not need to be proven beyond a reasonable doubt to be disqualifying for that window. The standard here is not a criminal conviction. It is whether legislators can treat the aggregate numbers as a directional guide to constituent sentiment. On that standard, the analysis is more than sufficient.
On Impersonation
Named officials discovering their identities appeared in the dataset without their consent is a real incident worth investigating. But the sign-in system was never designed to verify identity or attribute positions to specific individuals. Names are collected not to create a record of who voted, but because a completely anonymous system would be trivially manipulable. A name field is the minimal friction that makes aggregate analysis possible at all.
The relevant question for legislators is not “did John Smith actually sign this?” but “does the distribution of sign-ins reflect genuine public sentiment.” This is a survey mechanism, not a ballot. Washington has 7.8 million residents. Even a perfectly clean dataset with 100,000 CON sign-ins represents a small fraction of the population. Legislators have always understood these numbers as a directional signal, not a binding count. Treating impersonation as the central finding, rather than asking whether the aggregate signal survived manipulation, mistakes the instrument for the measurement.
The numbers behind the impersonation claim deserve scrutiny. Invest in Washington Now reported roughly 100-200 confirmed cases across 123,289 records, less than 0.2% of the dataset. Even tripling that estimate to account for unreported cases, it does not move a 10:1 ratio in any meaningful direction. And if you apply their own deduplication logic symmetrically: remove every name that appears more than once from both sides. CON drops from roughly 110,000 to 91,000 and PRO drops from roughly 10,000 to 9,000. The ratio is still 10:1. Their argument, applied consistently to both sides, does not change the conclusion.
Those confirmed cases were identified because victims self-reported. Public officials monitor mentions of their names, noticed the discrepancy, and came forward. That is the easiest fraud to find. It tells you nothing about what the rest of the dataset contains. Self-reported impersonation is the floor of what happened, not the ceiling, which is precisely why aggregate statistical analysis exists.
It is also worth considering what those confirmed cases likely represent. Some are probably legitimate resubmissions. Someone signed in, was not sure it worked, signed in again, and now appears twice. Some are probably trolling. Actual coordinated impersonation may be in there too, but the self-report mechanism cannot distinguish between the three. Treating 200 high-visibility cases driven by public figures monitoring their own names as representative of the full 123,000-record dataset is not a statistical argument. It is a press conference.
So What Does All of This Mean?
The answer to that is simple. The dataset has duplicates. The timing raised questions. Some names were submitted without consent. None of those observations, examined carefully, change what the data shows: roughly ten Washington residents opposed this bill for every one who supported it in committee. That signal has survived every test applied to it.
Factories exist to produce consistent, cost-effective products. That is the point. The relentless optimization of cost of goods sold is not a side effect of industrial production. It is the mandate. And it works, until it doesn’t. The reason products last so much less than they did twenty years ago is not that we forgot how to make durable things. It is that durability lost the cost argument. Quality is expensive. Variance is expensive. The system optimizes both out. What survives is the median product, built to a price, reliable enough to ship, and no more.
Modern schooling often behaves the same way. It batches children by age, sequences content for throughput, and optimizes for a predictable median. Sir Ken Robinson made this observation twenty years ago, and the metaphor stuck, not because it is clever but because it names incentives, not architecture. When a system must operate at scale under budget, policy, and staffing constraints, variance becomes expensive. The median becomes the target. Outliers become the problem.
That is how you get the loop so many families recognize.
A child with a spiky profile, gifted and struggling at the same time, or simply learning in a different sequence, is hard for a production line to interpret. The system cannot see internal state. It can only see outputs it knows how to count. Pacing, compliance, turn in rates, standardized measures, and classroom friction. When it cannot measure what is actually happening, it collapses complexity into a label. Lazy. Defiant. Behind. Broken. Sometimes worse. The misclassification is not incidental. It is structural. The factory cannot afford to treat every student as a special case, so it treats special cases as defects.
Twice exceptional programs were a serious attempt to address exactly this failure mode. 2e was not supposed to be a vibe. It was an operational category, a way to route support without denying capability.
Institutions rarely attack reforms head-on. They metabolize them. The common move is not to announce that everyone is 2e. It is more subtle. Fold 2e into the general program, justify the change as an opportunity for all, and quietly remove the differentiated pathways, expertise, and accountability that made 2e real. The label survives. The function does not. The specialist becomes a roaming consultant, the pull-out becomes a generic intervention block, and the documentation becomes a checkbox.
Spencer Silver at 3M spent years trying to make a strong adhesive and produced one that was too weak to hold permanently. By factory logic it was a failed batch. It sat in the lab for years because the system had no category for a glue that did not stick properly. A colleague with a different problem recognized the variance as the feature. The factory almost never found out what it had.
This pattern is familiar in M&A. Companies are often acquired to address a capability, culture, or talent gap. The acquirer gets what it wanted on paper, and then the organization takes over. Microsoft bought Hotmail to compete in web-based email. Hotmail ran on Linux. Microsoft ported it to Windows, the product degraded, and what had been acquired to solve a problem became an example of the problem. The engineers who built Hotmail watched what they had created get dismantled and left. The institution did not transform around the acquisition. The acquisition transformed into the institution, and the talent that made it valuable walked out with their badges.
The proof a program still exists is not whether the brochure mentions it. It is whether the supports remain distinct, staffed, and enforceable. When a category stops changing what adults do, the system reverts to default settings. Teach to the median, punish variance, treat the casualties as defects.
You can see the same dynamic in curriculum fights. When a system cannot reliably lift the floor, the path of least resistance is to lower the ceiling and call it equity. This is not cynical in intent. It is cynical in effect. Acceleration does not disappear. It moves off the books. Tutoring, test prep, schedule hacking, summer programs, parent advocacy. The families who can afford those channels use them. The families who cannot are left with the official story that the ceiling was lowered for their benefit. The median experience is preserved. The gap widens. Official metrics improve because the ceiling has been redefined.
None of this is morally mysterious. It is operational. What makes it damning is that schooling runs this population optimization model without the measurement and accountability that would make it legitimate.
Medicine is honest about something uncomfortable. Treatments have side effects. They do not affect everyone equally. Approval assumes some negative outcomes are acceptable in exchange for a greater good. But medicine only earns the right to make that utilitarian bargain because it is paired with surveillance and accountability. Trials, defined endpoints, adverse event reporting, label changes, and sometimes recalls. When a drug underperforms or causes unacceptable harm, the system has mechanisms to withdraw it.
Schooling borrows the utilitarian posture and skips the legitimacy conditions. There is no adverse event tracking for predictable harms like anxiety spirals, learned helplessness, disengagement, or the systematic grinding down of nonstandard profiles. When you ask what the rollback criteria are, you get a blank stare, because the system does not think in rollback terms. It thinks in throughput terms.
Here is a small, concrete example. One of my children has an accommodation plan tied to a documented set of specific needs. A teacher recently told us the plan would not be needed anymore because the child does not show ADHD signs. There is no ADHD diagnosis, and the plan is not based on ADHD. The teacher was not acting maliciously. They were acting normally inside a system that treats supports as vibes. In a system with real measurement, you do not withdraw support based on a vibe. You tie withdrawal to documented criteria, with a rollback plan if the criteria are wrong. This is not exotic engineering. It is basic change management. Define the hypothesis, define success, define failure, and pre-commit to the revert.
Schooling routinely does the opposite, and the response when things go sideways is not to revisit the decision. It is to escalate.
More pressure. More compliance. More labeling. The system treats opt-out as a containment breach rather than a performance signal, because enrollment and funding are coupled together. The institution has no incentive to register failure. It has strong incentives to frame failure as the students’.
So why does this cycle finally have a credible exit?
For most of modern history, if you wanted a coherent explanation, feedback loops, sequenced practice, and the ability to revisit a concept from a different angle without embarrassment, you needed the institution or you needed money. Those are the same thing for most families. AI makes those pieces abundant. It makes it cheaper to learn in a different order. It makes it cheaper to revisit a concept from five angles without being punished for needing a sixth. It reduces the penalty for variance in a way that nothing else in the past century has.
This is why models like Alpha School are worth watching, whatever you think of their specific implementation. They are proof that you can architect learning around mastery and coaching rather than batching and seat time. They are not just a new school brand. They are evidence that instruction is no longer scarce, and that the existing system’s grip on the delivery layer is loosening.
The tradeoff is real and worth being honest about. The devil you know versus the one you do not.
The existing system’s harms are normalized, which means they are mostly invisible. The new world introduces different risks. Dependency on opaque tools, misinformation at scale, AI-driven learning environments that are even more coercive than human ones because they optimize metrics nobody agreed to, and a widening gap between families who can navigate the options and those who cannot.
The credential layer will be the next fight. Institutions that lose control of instruction will shift to defending legitimacy. Seat time requirements, accreditation barriers, and the bureaucratic right to define what counts for the purposes of the next gate. If instruction becomes abundant, the last monopoly is not learning. It is recognition.
But the direction of travel is hard to reverse. Bureaucracy protects the status quo long past the point where the quo has lost its status. AI accelerates the expiration date. The more schooling responds to exits with escalation rather than adaptation, the more it will be outcompeted by systems that treat variance as signal rather than a defect.
I keep coming back to the medicine analogy, but with a sharper edge. In medicine, adverse events are data. In schooling, adverse events become discipline referrals and bad grades. One system updates on failure. The other system records the failure as the student.
AI is not a magic cure. But it is the first credible exit from a century-old loop. A factory that mistakes difference for defect, and calls the casualties the cost of scale.
SB 6346 would create Washington’s first personal income tax in nearly a century. A 9.9% rate on income above $1 million, projected at $3.4 billion annually, it passed the Senate 27-22 on party lines and is now in the House. Washington voters have rejected income taxation ten times at the ballot over the last hundred years. This is the most contested piece of legislation the state has seen in a generation.
Washington’s legislature runs an online sign-in system for committee hearings. Anyone can go to the legislative website and register their position on a bill, pro or con, without testifying. Legislators see the totals. The system is designed to give ordinary people a voice even if they can’t show up in Olympia. On SB 6346, it may be the only meaningful voice many residents have: the legislature designated the bill an emergency measure, which prevents a voter referendum. There is no ballot option. For most Washington residents opposed to this bill, signing in here, or calling their representative directly, is the entire menu.
When those numbers get manipulated, the perception gets manipulated. On a bill this significant, in a state with a century of voter resistance to income taxes, that is not a minor data quality problem. It is a distortion of the democratic signal legislators and journalists are using to understand where the public actually stands.
Which is why getting the analysis right matters. And why it matters that GeekWire got it wrong.
GeekWire reported Monday (Added 2/24/26: and apparently the Seattle Times too) that fraudulent sign-ins were used to inflate CON opposition to SB 6346. Named public officials confirmed their identities appeared without their consent. The framing was clear: the anti-tax side cheated.
The data tells a different story.
The story was built on analysis provided by Invest in Washington Now, a PRO-tax advocacy group that examined CON submissions and held a press conference. They reported a true incident, but failed to do the basic symmetric analysis needed to justify the narrative they attached to it.
I downloaded the full legislative sign-in export at 5:51 PM Pacific on February 23rd, 123,289 records, and ran the same tests on both positions. Here is what it shows.
The data confirms fraud. It does not confirm that fraud explains the opposition. Those are different claims, and the difference matters enormously on a bill this significant.
Who Actually Showed Up
“Legitimate” here means a unique name that appears at least once during daytime hours (7 AM to 11 PM PT). The export does not verify identity.
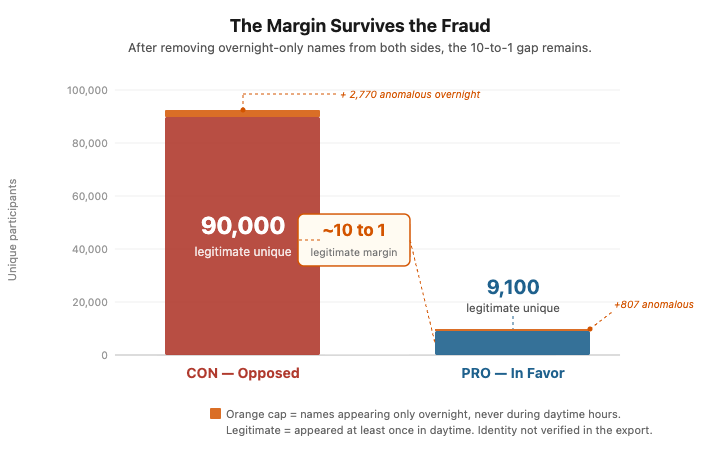
CON was underrepresented during overnight Pacific hours, which is exactly what you would expect from Washington residents who are asleep at 2 AM. By every geographic measure in the data, CON’s daytime participation pattern is consistent with Washington residents showing up. CON does have an overnight anomaly, roughly 2,800 names that appear only in overnight windows and never in five days of daytime sign-ins, which reduces the legitimate unique count to roughly 90,000. More on this below.
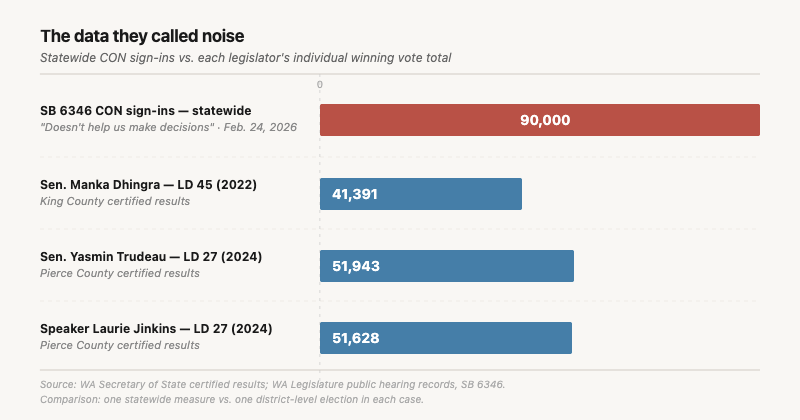
The PRO side has 9,919 unique names across the full hearing. But between 1 and 5 AM Pacific on February 20th, 934 submissions arrived in a single five-hour overnight window (1:00–5:59 AM). That window accounts for about 8.4% of all PRO submissions across the entire hearing period. Of those 934 submissions, 807 were unique names. Set those aside, and you have roughly 9,100 apparent legitimate PRO participants.
That is a roughly 10-to-1 ratio (90,408 CON vs 9,112 PRO in the export, after removing overnight-only names as defined here). A margin like that on a contested tax bill during a legislature that removed opportunity for feedback other than this survey is not, on its own, statistically implausible.
Here is what the data actually shows. Both sides have anomalous overnight submissions that do not match the daytime participation signature. On the CON side, roughly 2,800 names, about 3% of their total, appear only overnight and never during five days of daytime sign-ins. On the PRO side, 807 names, about 8% of their total, appeared in a single five-hour overnight window. Both anomalies are real. But after removing them, roughly 90,000 legitimate CON participants remain against roughly 9,100 legitimate PRO participants. The fraud did not manufacture the opposition. The fraud, such as it is, was larger in proportional terms on the side that was already losing 10 to 1.
The story treated fraud as the explanation for the margin. The data shows the margin survived the fraud. On every test, the more anomalous signal sits on the PRO side, not the CON side.
The Geography Test
The most straightforward test requires no statistics at all. Washington residents sleep on Pacific time. If you plot submissions by hour of day, genuine local participation should cluster during waking hours and drop off after midnight.
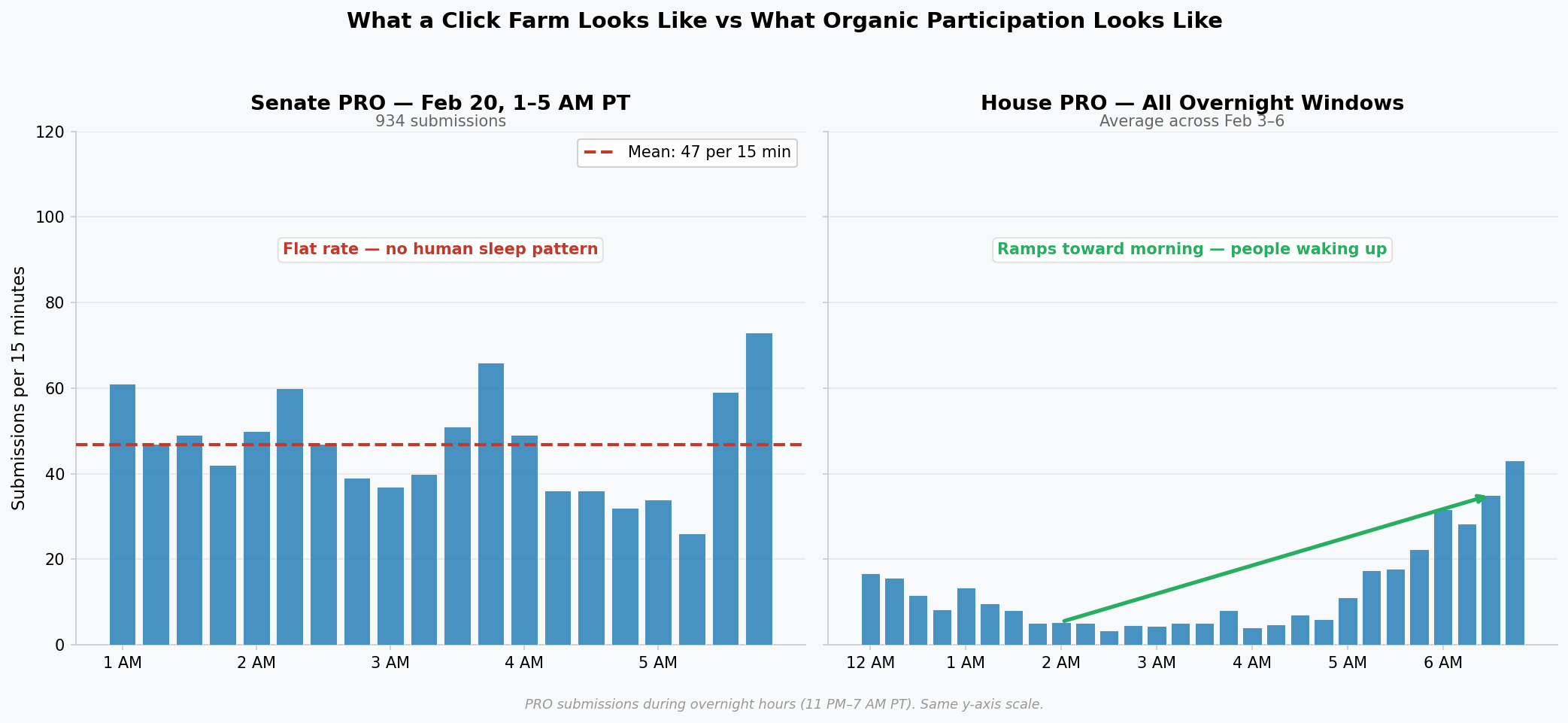
CON activity drops overnight, consistent with local participants sleeping on Pacific time.
PRO shows a pronounced spike on February 20th between 1 and 5 AM, running at close to 190 submissions per hour for five straight hours, while Washington residents were asleep and the CON side was quieter than usual. The spike is not a few night owls.
The Community Test
Here is where it gets harder to explain away.
Across five full days of daytime sign-ins, we have an observable picture of who the PRO community actually is. Roughly 9,100 people engaged during normal waking hours. Five days is a long window. If you are a genuine PRO supporter, the probability that you appeared in that record at least once is high.
Name communities have statistical fingerprints. Any two groups drawn from the same population will share common names at a predictable rate, the same demographic mix, the same frequency of “James Kim” or “Sarah Johnson.” So even if the overnight submitters were entirely different individuals from the daytime crowd, you would still expect their names to collide with the daytime pool at a rate consistent with drawing from the same community. The longer the daytime window, the higher that rate gets.
You can test this directly. Draw 934 random names from the known PRO pool and ask how many appear somewhere in five days of daytime submissions. Across 10,000 simulations, the answer is about 86%.
The observed overnight overlap was 13.6%. Nearly nine out of ten overnight names had never appeared in five days of daytime PRO submissions.
Every one of the 10,000 simulations produced more overlap than the overnight batch did. The minimum was 82%.
The same test applied to CON tells a similar structural story. CON’s overnight names also show only 21–25% overlap with the daytime pool across five nights, against an expected 90–94%. Both positions have overnight participants who are largely absent from the five-day daytime record. The difference is in magnitude and concentration. CON’s anomaly spreads 2,800 names across five nights. PRO’s concentrates 807 names into a single five-hour overnight window. The PRO signal is sharper, but the underlying pattern of overnight names that don’t match the daytime community appears on both sides.
The Name Collision Test
In any large population, names repeat. If you pull 934 people at random from Washington state, some of them will be named James Kim. Some will be named Sarah Johnson. That is not fraud, that is just how names work. The question is whether the names repeat at the rate you would expect given the size and demographic makeup of the community you are drawing from.
934 overnight PRO submissions produced zero repeated names. Not fewer than expected. Zero.
From a genuine community of roughly 9,100 PRO supporters, you would expect around 60 name collisions in a sample that size, just by chance. We ran 10,000 simulations drawing from the actual PRO participant pool. Every single one produced collisions. The lowest was around 30. The observed overnight batch produced none.
The most consistent explanation is that someone built a list and specifically made sure no name appeared twice. That is not what organic participation looks like. That is what a curated submission operation looks like.
The CON side shows the opposite pattern. Several overnight windows had more name repeats than expected, consistent with people resubmitting or households submitting together. Messy, in other words. The kind of messy that real participation produces.
934 submissions. 934 unique names. Zero repeats. That is the number that should be in the headline.
On CAPTCHA
The form uses CAPTCHA verification. This comes up because some coverage implies it as a meaningful protection.
It is not, against this class of problem. CAPTCHA distinguishes automated bots from humans. It provides no protection against human click farms, which are operations that pay workers in other countries to solve CAPTCHAs manually and complete form submissions by hand. This is a commercial industry. Services are publicly listed, priced at $1 to $3 per 1,000 submissions.
The pattern observed on February 20th is most consistent with coordinated human submissions using a curated name list: overnight timing, near-zero overlap with the daytime community, and zero name collisions across 934 submissions. A click-farm-style mechanism is one plausible explanation. The public export cannot prove attribution without server-side logs.
At those rates, the 934 anomalous overnight PRO submissions represent a trivial cost against a bill projecting $3.4 billion in annual revenue.
On the Audit Trail
The public data export does not include IP addresses. Whether internal server logs exist and whether they have been preserved is unknown. That is a question the AG’s investigation should answer before those logs age out.
Even with full IP logs, naive geolocation proves little. Click farm operations commonly route through VPNs, and an IP address alone does not establish geographic origin without infrastructure-level analysis of the autonomous system it belongs to. What you want to know is not which city the IP is registered to. You want to know whether it belongs to a residential ISP, a datacenter, or a known VPN provider range. Those are different findings with different implications.
What This Means
Neither finding resolves cleanly without a real investigation. The named official impersonations on the CON side are real and the AG should pursue them. But confirming specific named victims is the easiest fraud to find because the victims can self-report. That is not a statistical audit, and it does not address what the data shows on the other side.
Both findings warrant investigation. The system made both possible.
There is a useful analogy here. Risk-Limiting Audits are the gold standard for post-election verification. The premise is that you do not need to check every ballot to establish confidence in the outcome. You need to bound the probability that the anomalies are large enough to change the result. Advocates of RLAs often argue, correctly, that statistical evidence is sufficient to certify an election without requiring individual identity verification for every voter.
That is precisely what this analysis does. It does not identify every fraudulent submission. It asks whether the fraud on either side was large enough to manufacture the margin. The answer is no. After removing every overnight anomaly on both sides, roughly 90,000 legitimate CON participants remain against roughly 9,100 legitimate PRO participants. If statistical sampling is rigorous enough to certify an election, it is rigorous enough to evaluate a legislative sign-in system.
The sign-in infrastructure was built for access. Low friction, no identity binding, no rate limiting that held against coordinated submission. I have written before about how Washington has accumulated individually defensible choices that collectively produce systems incapable of defending their own integrity. The legislature is now trying to adjudicate participation fraud on infrastructure that was never designed to be auditable.
The question that does not get asked in any of the coverage: why did Washington build a public participation system with no ability to verify, audit, or forensically reconstruct what happened, and what would it take to build one that can?
Methodology
All analysis was run on the public CSV export of sign-in records for SB 6346, downloaded at 5:51 PM Pacific on February 23rd, 123,289 records total. Every test was applied symmetrically to both positions using the same parameters. The analysis does not attempt attribution. It bounds the probability of innocent explanation under stated assumptions.
Geographic analysis. Submissions were binned by Pacific hour. Each position’s hourly share was compared to that position’s overall base rate across the full hearing. CON activity drops overnight relative to daytime hours, consistent with participants sleeping on Pacific time. PRO showed a concentrated spike on February 20th between 1 and 5 AM, sustaining close to 190 submissions per hour across five consecutive hours. The 1 to 5 AM PT window corresponds to mid-day hours in parts of Asia and the Middle East.
Name overlap test. This test requires no statistical model and is not sensitive to assumptions about name distributions. For each overnight window with at least 20 submissions, the unique names were compared against that position’s daytime submissions (7 AM to 11 PM) across the full hearing. Overlap fraction equals names appearing in both sets divided by total overnight unique names.
To establish expected overlap, 10,000 random samples of size n were drawn without replacement from that position’s full-hearing participant pool, and the overlap fraction with the daytime set was computed for each draw. On February 20th, the PRO observed overlap of 13.6% fell below the minimum of all 10,000 simulations. The lowest simulated value was about 82%. CON overnight overlap ranged from 21–25% across five nights, against a bootstrap expectation of 90–94%, also below every simulation on every night. Both positions show overnight communities that are largely disconnected from their daytime pools.
Birthday-corrected collision analysis. Raw name duplication rates are not meaningful without correcting for sample size. In any large sample, some names will repeat by chance regardless of how the data was generated. The expected number of name collisions for a sample of size n drawn from a pool of N_effective distinct names follows the occupancy problem:
N_effective was estimated separately for each position from that position’s own daytime submissions using the method-of-moments estimator: N_effective = u² / (2s − u), where u is the number of unique names and s is total daytime submissions. This assumes the overnight community draws from the same underlying name distribution as the daytime community. That assumption is explicit and falsifiable. CON showed collision excesses across multiple nights, with effect sizes of 1.8%, 2.3%, and 4.1% on the three most anomalous nights. PRO worst night (February 20th): 0 observed collisions, approximately 60 expected, deficit of ~60. Statistical significance was assessed using the Poisson distribution, upper-tail for excess and lower-tail for deficit.
Sensitivity. The collision deficit finding holds unless the PRO overnight community drew from a pool of at least approximately 200,000–300,000 distinct name combinations, roughly 20–30 times the total observed PRO participant base across the full hearing. The entire PRO participant pool across five days is 9,919 unique names. A reader who disputes this should specify what pool size they would defend, and explain why that entire community was absent from every daytime window across the hearing period.
Duplicate submissions. The same name appearing multiple times are a separate question and not the subject of this analysis. Some duplication is expected in any real participation dataset; people resubmit, households share names, and common names genuinely recur. The relevant question is whether duplication rates deviate from what the population would predict. The overnight CON windows showed collision excesses consistent with resubmission or household participation. That is a different signal from the overnight PRO deficit, and it points in a different direction
What this analysis cannot determine. The geographic origin of submissions, the identity of any operator or coordinator, whether the system maintains server-side logs, and the mechanism behind any anomalous pattern. Attribution of intent from behavioral data alone is not supportable. These findings bound the probability of innocent explanation. They do not establish what the non-innocent explanation is.
I ran this analysis quickly after the GeekWire story published. There may be subtle issues in the methodology I have not caught. I am confident it is directionally correct. If you find an error, I will correct it.
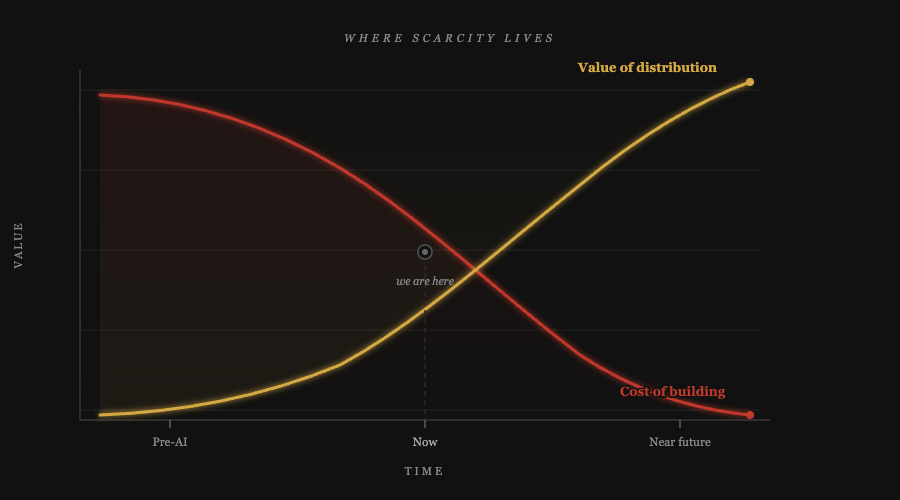
“Distribution is the new moat.” You can find some version of that sentence in almost any startup discussion from the last year. It circulates as a take, gets liked, gets reshared, and then gets reproduced by someone else who arrived at the same conclusion independently. The observation has become cheap to make precisely because it is true. What is harder, and what most of those takes skip, is understanding why the structural mechanics behind it matter and what they actually require you to do differently.
For decades, venture capital rewarded the ability to build. In the AI era, building is no longer scarce. Distribution is.
There was a time when building complex software required deep teams, long timelines, and substantial capital. Engineering was the constraint. Infrastructure was the constraint. Expertise was the constraint. That constraint justified venture scale returns.
AI is dissolving that constraint, not all at once, and not uniformly across every domain, but steadily and in ways that are already measurable.
This is not a cliff. It is a slope.
The companies founded today still face real execution challenges. The ones founded three years from now will face fewer. The ones founded ten years from now will operate in an environment where the cost of building sophisticated systems is a fraction of what it is today. We are in the early middle of this shift, not at the end of it. That matters because the temptation is to look at current valuations, current outcomes, and current M&A multiples and conclude that nothing has changed. Something has changed. It is just moving at the pace of markets and human institutions, not at the pace of model releases.
The Repricing of Expertise
We are watching a repricing of expertise, a slow one, with uneven edges.
Not at the foundational layer. Paradigm-shifting breakthroughs still matter. The rare intellectual leap that unlocks a new architecture or a new computational primitive remains valuable and durable. But most companies are not those breakthroughs. Most companies sit on top of them.
I have written before about how AI is repricing skill at the individual level, injecting liquidity into what was once a slow-moving market for technical expertise. What is happening at the venture level is the same dynamic playing out across entire product categories. When fifty startups can build near-equivalent products in twelve months, product differentiation compresses. Expertise becomes assisted. Execution becomes accelerated. Barriers to entry fall.
It is worth being direct about what that means. AI does not just flatten products. It flattens people. The scarcity that once justified premium human expertise, the advisor with the rare insight, the consultant who had seen this problem before, is narrowing. That edge does not disappear, but it compresses fast unless the expertise is embedded in distribution, in relationships and customer context that cannot be replicated from a prompt.
There is an important exception. In data-rich verticals, proprietary datasets create compounding advantages that AI amplifies rather than erodes. Healthcare, finance, legal, infrastructure – in these markets the data is not just an asset, it is a moat that gets stronger as it grows. AI makes that data more useful, not less defensible. The dynamic in these verticals is different. The scarcity is not building capability or even distribution in the generic sense. It is the data itself, and the domain-specific judgment required to use it correctly. This connects to a broader point worth sitting with: when you rent the capability layer, you rent the moat. In AI-native verticals, whoever owns the model behavior owns the product – and that is a different kind of lock-in than anything cloud computing created.
The result is predictable. A wave of companies will launch in every attractive AI-adjacent category. Many will grow quickly. Many will look venture-scale in their first 24 to 36 months. Most will not become venture-scale businesses.
They will explode and then flatten.
Not because they were poorly run. Not because the founders lacked talent. But because it became too inexpensive to create what they created. The winner-take-most dynamic compresses margins and growth for everyone except the few that secure durable control.
Cheap building creates crowded categories. Crowded categories destroy the middle of the return distribution.
The venture math here deserves to be stated plainly. Cheap building means more competitors. More competitors cap market power. Capped market power caps exit multiples. In a crowded AI category where any competent team can replicate the core product, the venture model itself compresses. Not because the market is small, but because structural dominance becomes harder to achieve and sustain. Many of these companies are structurally unlikely to become venture-scale businesses. The category economics will not support multiple large players once replication costs collapse, and most founders do not have the distribution infrastructure to be the one that survives. Asymmetric outcomes remain possible. They are just harder to achieve and harder to sustain in categories where the product itself can be reproduced quickly.
What This Does to Venture Capital
This has structural consequences for venture capital, though they will play out over years, not quarters.
If building is cheap and competition is abundant, returns concentrate harder and faster. You get more rockets. Fewer reach orbit.
Investors will demand signal sooner. Growth becomes the proxy for distribution dominance. Capital is deployed to test whether the company can win quickly, not whether it can build elegantly. The tolerance for long, patient build cycles without distribution proof shrinks. Capital releases in stages tied to evidence of emerging control.
This is reshaping round structure too. When building is cheap, large upfront rounds are harder to justify – you no longer need $20M to construct the product. Seed rounds compress because the build cost does not warrant more. But growth rounds are becoming larger and more heavily tranched, with capital tied to distribution milestones rather than product ones. Channel proof. Embedded customer cohorts. Pipeline velocity. The structure of the round starts to reflect the new scarcity. Capital flows in proportion to what is actually hard, and what is actually hard is no longer building the thing.
The traditional power-law model assumed a long tail of moderate outcomes. In a world of rapid replication, the moderate outcome becomes harder to sustain.
Meanwhile, IPO pathways have narrowed. The regulatory intent was investor protection. The outcome was exclusion. By making it harder for companies to go public early, regulators locked retail investors out of the steepest part of the value curve, the years when a company moves from promising to dominant. Secondary markets expanded to fill the gap, but access to those markets is not democratic. Private capital captures what public markets used to offer to a broader population. Venture starts to look less like broad-based growth capital and more like concentrated private allocation, closer to family offices, less like 1990s expansion funds. AI will likely accelerate that dynamic. The companies creating the most value will stay private longer, and the people with access to them will be a narrower group than before.
Selectivity increases. Portfolio sizes shrink or become more strategically concentrated. The “grow at all costs, you’ll get more later” model becomes harder to justify when many fast-growing companies are structurally incapable of sustaining dominance. Capital no longer buys uniqueness. It buys speed – the time and resources to build a distribution funnel, execute against it, and reach durable entrenchment before a competitor replicates the product and races to the same buyers.
Built for Acquisition, But It Is Not a Spreadsheet Decision
There is another dynamic that becomes more visible in this environment. Some startups are designed not to become category winners, but to slot perfectly into one specific incumbent. Not strategic fit in the abstract sense. Deliberate adjacency to a single buyer. The product is built to complete a portfolio gap. The roadmap mirrors a specific weakness in a specific acquirer’s product line. Some founders are not optimizing for market dominance. They are optimizing for perfect adjacency to one buyer, and shaping every decision around what makes that buyer say yes.
This is not new. But the calculus around it is shifting.
When technology is easier to replicate, the premium for strategic fit increases relative to the premium for raw IP. At the same time, the value of acquiring technology alone diminishes. If a product can be rebuilt internally in 12 to 18 months, the acquisition multiple compresses. The technology becomes a starting point for an internal conversation, not a reason to write a check.
What remains valuable in M&A is harder to replicate. Embedded distribution. Contractual entrenchment. Regulatory positioning. Customer relationships. Data gravity.
In regulated verticals, this goes further. A company that has already navigated the compliance requirements to operate in a market – secured the certifications, built the audit trails, established the regulatory relationships – has compressed years of a buyer’s time to market into something acquirable. Compliance readiness is not a cost center. It is a distribution accelerator. Vertical access and compliance readiness are part of the distribution story, not separate from it. For an acquirer trying to enter a regulated market, the fastest path is often not to build the product. It is to buy the company that already has permission to operate. That shifts what gets priced into an acquisition and why some targets command premiums that pure technology analysis cannot explain.
Technology without distribution is just an expensive prototype.
But what gets lost in that clean analysis is that acquisition decisions are not made by spreadsheets. They are made by people, in rooms, often under time pressure, with incomplete information and competing organizational interests.
A founder who has built real relationships inside a strategic buyer has a fundamentally different acquisition outcome than one who has not, even if the products are comparable. The internal champion who has watched you execute, who trusts your judgment, who has gone to bat for you in internal budget conversations, is not a nice-to-have. They are often the reason a deal happens at all.
Perception compounds this. Acquirers pay for confidence as much as capability. A company perceived as the category leader, even in a crowded category, commands a premium that may not be fully justified by its metrics. Market positioning, analyst coverage, conference presence, and the quality of your reference customers, these shape the narrative in an acquirer’s boardroom. The story they can tell internally about why they did this deal matters enormously. Acquisitions have to survive internal politics.
Timing is almost never purely rational either. Companies get acquired when a buyer is scared, or ambitious, or has capital to deploy, or is about to lose a competitive advantage they can feel slipping. Being visible and credible at that moment, not just when you need a buyer, is what closes deals.
None of this means product and metrics do not matter. They do. But they matter as the floor. Above the floor, acquisition outcomes are determined by relationships, reputation, and the story someone is willing to tell on your behalf inside an organization that does not know you.
The Irony of Automating Your Own Moat
Customer management is one of the domains AI is aggressively trying to automate. AI SDRs. AI account managers. Synthetic personalization. Automated follow-up. Generated relationship intelligence.
In a world where distribution is the scarce resource and relationships drive acquisition outcomes, the industry is racing to replace human relationship infrastructure with synthetic substitutes.
This is not irrational. Automation increases efficiency. Most sales and account management processes have enormous amounts of low-value activity that could and should be automated.
But in high-value markets, buyers are not just purchasing functionality. They are purchasing risk reduction. They are purchasing accountability. They are purchasing confidence. And confidence is built through consistent human judgment over time, through the accumulation of trust that comes from someone showing up, delivering, and being present when things go wrong.
There is a related dynamic at the talent level. I have written about how AI is eliminating the on-ramp for early-career engineers, absorbing the low-context work that once let junior developers accumulate the judgment and institutional knowledge that makes senior engineers valuable. The same problem applies to the people who build enterprise relationships. The craft of reading a room, navigating a stalled deal, and managing a difficult renewal, these compound over years of real exposure. Automating the entry-level work in sales and customer success is not just an efficiency play. It shapes who gets the chance to develop the judgment the role ultimately requires.
Assistive automation increases efficiency. Primary automation risks eroding the very thing that becomes the last defensible moat.
The counterargument is that AI can also accelerate distribution itself. Faster outreach. Better targeting. Smarter personalization at scale. That is true as far as it goes. But it confuses distribution tactics with distribution durability. AI can help you reach more people faster. It cannot manufacture the trust that makes them stay, the embeddedness that makes switching costly, or the relationship capital that makes an acquirer’s internal champion go to bat for you. Speed without stickiness is just faster noise.
In a world saturated with synthetic output, authentic relationships are appreciated. The companies that understand this distinction, between automating the low-value repetitive work and preserving the high-value human judgment, will have a structural advantage over those that optimize purely for efficiency.
Forward-deployed engineers become strategic assets. Customer success becomes competitive infrastructure. Enterprise sales become durable leverage.
This will not be obvious in year one. It will be obvious in year five.
Overgrowth Risk
Cheap building combined with abundant capital creates another problem. When capital is deployed to chase an early signal, companies scale headcount and burn before structural dominance is secured. If they are not the winner in their category, they are left with a cost structure built for orbit and a trajectory that never left the atmosphere.
They grew too fast for a market that would not support multiple large players.
This risk increases when categories are crowded, and replication is easy. AI does not eliminate business fundamentals. It amplifies their consequences.
The Structural Shift
The AI era does not eliminate venture capital, entrepreneurship, or breakthrough innovation.
It shifts the locus of scarcity, gradually, unevenly, and irreversibly.
Foundational intellectual leaps remain rare and valuable. But most startups are not foundational leaps. When building was expensive, builders won. When building becomes cheap, distribution becomes destiny.
This transition is already underway. It is not complete. The companies founded in the next few years will discover its contours the hard way, either because they adapted early or because they did not.
The founders who understand what is happening will optimize differently. They will invest in buyer access before polishing perfection. They will treat relationships as infrastructure. They will see funnel design as a core product, not a marketing afterthought. They will build the internal champions inside their strategic targets before they need them.
And they will move fast on all of it. When building is cheap, the window to establish distribution before a competitor replicates the product is shorter than it has ever been. Timing has always mattered in startups. In this environment, it compounds differently – being six months earlier into a key account, a channel partnership, or a strategic relationship can be the difference between owning the category and being one of the many that flattened. Speed used to be about shipping. Now it is about embedding.
The VCs who understand it will underwrite differently. They have always asked whether the product is impressive and whether the founders are domain experts worth betting on. Those questions do not go away. But distribution used to be a problem you could punt on, something a strong team would figure out in year two or three. That tolerance is shrinking. Investors will put more weight on whether the company already has a credible path to controlling the channel, and be less willing to assume it will materialize later.
Because in a world where fifty companies can build the same thing, the only one that matters is the one that owns the channel and has convinced someone on the inside that betting on them was the right call.
Technology used to be the moat.
Now the moat is access. And access is built by people, over time, in ways that are harder to automate than we would like to admit.
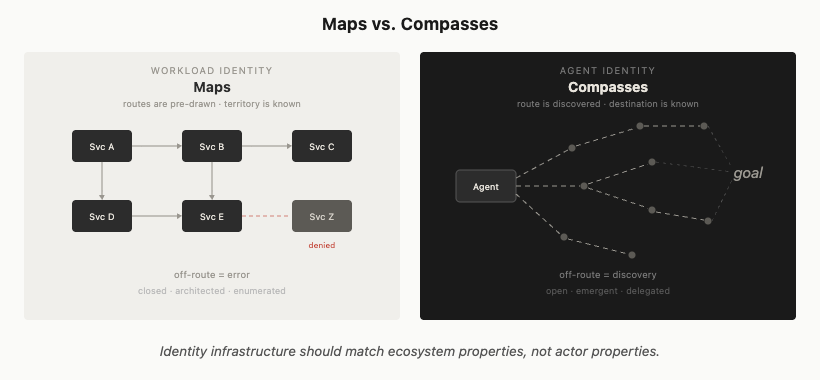
Let’s Encrypt announced DNS-PERSIST-01 support this week. That is worth noting on its own. But the announcement landed in a way that made me want to trace the longer arc, because what DNS-PERSIST-01 represents is not just a new ACME method. It is the last piece of a transition that took the ecosystem roughly three decades to complete.
That transition was simple in concept and genuinely hard in practice. Stop guessing who answers the phone and start proving who controls the namespace.
What “domain control validation” actually meant in the early days
If you were issuing or auditing certificates in the early web era, domain control validation was less a cryptographic proof than an act of institutional faith. The certificate authority (CA) would send a challenge to webmaster@, admin@, or hostmaster@ at the subject domain, or sometimes look up a fax number in WHOIS and send something there. If a human responded, the certificate got issued.
The model made a bet, a bet that there was a stable, security-relevant human role behind each domain, reachable through a stable channel, and that the person on the other end was both authorized and paying attention.
That bet was always shakier than it looked. What actually happened over time was that the alias went to a ticketing system, or an outsourcer, or a shared mailbox that someone forgot to audit, or just the wrong person entirely. The certificate still got issued. The CA had checked the box. No one had actually verified control of anything.
The worst failures in this period were not exotic cryptographic breaks. They were governance failures and operational drift. The “webmaster takeover” class of problem. The role stopped being real long before the method stopped being allowed. The Baseline Requirements, the industry rules governing what certificate authorities are allowed to do, carried these validation approaches forward because nobody volunteers to own the deprecation, and someone always depends on the thing you want to kill.SC-080 and SC-090 are essentially the CA/Browser Forum (CABF) writing down, in balloted form, what practitioners had already known for years, that being able to be reached at a business address does not demonstrate domain control.
The thing that made the real fix possible
It is easy to look at ACME, the protocol that powers automated certificate issuance, and treat it as a purely technical improvement. It was. But the reason it became viable as a default assumption had as much to do with deployment reality as with protocol design.
In 2014, roughly 30% of web traffic was HTTPS. Mozilla telemetry puts it above 80% globally by late 2024, with North America around 97%. Chrome’s numbers show the same shape, climbing from the low 30s in 2015 to 95-99% by 2020 and plateauing since.
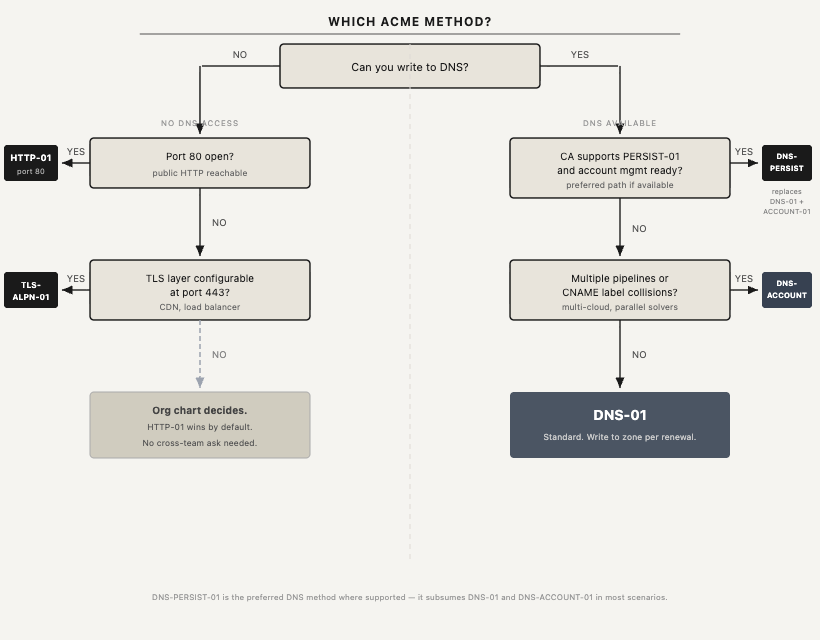
That matters because ACME’s endpoint-based methods depend on actually reaching the endpoint. HTTP-01 proves control by serving a signed token over HTTP at a well-known path on port 80. TLS-ALPN-01 proves control by completing a TLS handshake on port 443 using a dedicated protocol extension and a special validation certificate, with no HTTP handling required. That distinction matters in practice; TLS-ALPN-01 exists specifically for hosting providers, CDNs, and TLS-terminating load balancers who want to validate at the TLS layer without routing validation traffic through to their backends. If port 80 is blocked or you are terminating TLS before HTTP ever reaches your application, TLS-ALPN-01 is the right tool. If you have a publicly reachable web server and port 80 is open, HTTP-01 is simpler.
Both are bootstrap proofs and you can establish domain control without DNS write automation, which matters for the long tail of deployments where DNS is locked down or outsourced in ways that make safe automation difficult. In 2014, assuming you could reach a public endpoint was optimistic. By 2024, the population of sites that cannot serve a response over HTTP or TLS is small enough to be the exception. The web converged on HTTPS fast enough that endpoint-based validation became the reasonable default.
HTTP-01 is also, almost certainly, the last insecure-by-design method that will survive long term, and it will survive for structural rather than technical reasons. There is a bootstrap problem – TLS-ALPN-01 requires TLS already be deployed and configurable at the edge, but if you are getting a certificate because you do not yet have TLS, you cannot use TLS-ALPN-01 to get it. HTTP-01 is how you break out of that loop. More durable than the bootstrap problem, though, is the org chart problem. In large organizations, the web team controls the servers, the network team owns port policies, the DNS team owns the zone, and security owns the TLS infrastructure decisions. None of them individually have the full set of permissions to deploy any other method without coordination. But the web team can serve a token file over port 80 without asking anyone. HTTP-01 wins by default, not because it is the right answer, but because it is the answer that requires the fewest cross-team conversations. That dynamic is unlikely to change, which means HTTP-01 will probably remain the method of last resort indefinitely, insecure channel and all.
DNS-01, and why scale broke it
DNS-01 changed the question from “who answers this email” to “who can write to this DNS zone.” That is a meaningfully better question. DNS is not a signal that you control the domain. It is the domain.
The operational reality, though, is that DNS automation means DNS API credentials distributed across issuance pipelines, renewal workflows, and whatever tooling you are running at the edge. At modest scale that is manageable. At high volume, across large platforms, IoT deployments, and multi-tenant environments, the recurring DNS write per renewal starts to look like both a performance constraint and a credential sprawl problem.
The CNAME delegation pattern that became common was a partial answer, point _acme-challenge.<domain> at a zone you control more tightly, and do the proof there. It worked. It also created a new problem, multiple independent solvers fighting over a shared label.
DNS-ACCOUNT-01, which solved the CNAME collision and nothing else
DNS-ACCOUNT-01 exists to solve that specific problem. By scoping the validation label to the ACME account rather than leaving it shared, multiple delegated pipelines can coexist without colliding. Two independent issuance systems, two different cloud providers, parallel solvers during a migration. They all get their own label and can run without coordinating.
It is intentionally narrow. It does not change the underlying rhythm of fresh proof per issuance. The label is persistent, the proof is still ephemeral. A new token per order, a new DNS write per renewal. The change is only where the proof lives, so delegation can scale cleanly. DNS churn remains, because that was not the problem DNS-ACCOUNT-01 was trying to solve.
In hindsight, that narrowness reflects the world it was designed for. Certificate validity was still measured in years, then in 398 days. Renewals were infrequent enough that requiring fresh DNS proof per issuance was a manageable cost. The credential distribution problem existed, but it was not yet acute. If DNS-ACCOUNT-01 had been designed in a world where certificates expire every 47 days, which is where the CABF is now taking us, it almost certainly would have looked a lot more like DNS-PERSIST-01 from the start. That is not a criticism. You cannot see the 47-day problem from inside a 398-day world.
DNS-PERSIST-01, which the short-validity world actually requires
The CA/Browser Forum’s ongoing push to shorten maximum certificate validity, from years down to 398 days and now trending toward 47, makes the recurring-proof model increasingly painful for everyone, not just operators running at high volume. At 398-day validity, a DNS write per renewal is a minor operational cost. At 47 days, you are writing to DNS eight times a year per certificate, across every certificate in your fleet, with API credentials that have to live somewhere in that pipeline. That is not a scaling problem. That is a design problem.
The more important point is that DNS-PERSIST-01 is simply the better tool for anyone who has DNS access and a CA that supports it, regardless of volume. It subsumes what DNS-01 and DNS-ACCOUNT-01 each solve – the CNAME collision problem goes away because each account’s standing authorization is already scoped, and the credential churn problem goes away because there is no recurring write.
The useful analogy here is passwords versus passkeys. Passwords require you to re-prove the secret on every authentication. Passkeys establish a cryptographic binding once and derive proof from it. Every DNS-based ACME method before DNS-PERSIST-01 worked like a password, prove control again, on this order, right now. DNS-PERSIST-01 works like a passkey; the binding is established, scoped, and cryptographically tied to your ACME account key. You do not re-prove the same thing on every renewal. You prove you still hold the key.
Instead of proving control on every renewal cycle, you establish a standing authorization record bound to your ACME account and the CA. Set it once. Reuse it across renewals. The CABF formalized this direction in SC-088v3, which added the DNS TXT Record with Persistent Value method to the BRs.
This is not a shortcut. The standing authorization is scoped, can carry expiration, and is explicitly tied to an ACME account key. The attack surface moves from the repeated DNS transaction to the account key itself, which is the right place for it. That is why Let’s Encrypt is being deliberate, Pebble (the reference ACME test server) support is in place, client support is in progress, and the staged rollout is planned for 2026. The scope controls around wildcard policy and authorization lifetime are part of the design, not afterthoughts.
What it eliminates is the recurring DNS write requirement that turned high-volume issuance into a credential distribution problem. In a world trending toward 47-day certificates, that is not a nice-to-have. It is the method that makes the new validity regime operationally survivable for anyone running at real scale.
What actually changed
The webmaster era died because the webmaster role died. The person who answered webmaster@ in 1995 was plausibly the person responsible for the domain. By 2010, that alias might go anywhere. By 2020, it was a cassette tape. Technically still a format, functionally forgotten.
This is the same pattern that gave us a decade of SIM-swapping attacks. SMS was a convenient channel, so the industry conscripted it into an authentication role it was never designed for, and held it there long after the threat model had outgrown the assumption. Nobody decided email-to-webmaster or SMS were the right security primitives for what they were being asked to do. They were just there, they mostly worked, and changing them had cost. The failures were predictable in retrospect and ignored in practice until the losses became undeniable.
The ACME methods work because they measure what they claim to measure. HTTP-01 proves you can respond at the endpoint. DNS-01 proves you can write to the zone. TLS-ALPN-01 proves you can complete a handshake. Technical controls, not institutional proxies.
DNS-PERSIST-01 is the mature form of that idea, a standing proof of control that does not require re-proving the same thing every 90 days at the cost of DNS churn and credential distribution. It is also the method that answers the question the old system was never actually asking. The old system broke because standing assumptions about institutional stability turned out not to hold. The new system makes the standing assumption explicit, scoped, bound to a cryptographic identity, and revocable.
That is not the same mistake. That is the lesson applied.
Start here when choosing a method. If you cannot touch DNS and port 80 is open, HTTP-01 is the simplest path. If port 80 is blocked or you are terminating TLS before HTTP reaches your application, TLS-ALPN-01 validates at the TLS layer without touching HTTP handling. If you need wildcard coverage or your edge is not publicly reachable at all, DNS-01 is the right tool. If you are running multiple independent pipelines against the same domain and CNAME delegation is creating label collisions, DNS-ACCOUNT-01 solves that without changing anything else. And if you are renewing at volume in a world trending toward 47-day validity, DNS-PERSIST-01 is the method that does not eventually break you, not because the others are wrong, but because repeated proof per renewal was designed for a renewal cadence that no longer exists.
In practice, large organizations often find themselves in a catch-22 that makes the decision for them. TLS-ALPN-01 requires TLS to already be deployed and configurable at the edge, but you need the certificate to deploy TLS in the first place. DNS-01 requires writing to the zone, but DNS is owned by a different team, and the change process takes weeks. DNS-PERSIST-01 requires standing up ACME account management, but that is a security infrastructure decision that needs approval. Meanwhile, the web team controls the servers and can serve a token file over port 80 today. So HTTP-01 it is, not because anyone evaluated the options and chose it, but because it was the only method where a single team had all the permissions needed to complete validation without a cross-functional project. The decision tree above describes the technically correct path. The org chart usually picks a different one.
Like most security improvements, the arc from fax-based DCV to persistent cryptographic authorization took longer than it should have, the gap between knowing something is broken and replacing it is always larger than it looks from the outside. But the trajectory is now clear that domain control validation means proving control, not guessing at it.
Washington State is not in the middle of a single policy dispute.
It is moving through a structural sequence that has been building for nearly a century, and the density of constraint-adjacent actions has increased.
The millionaire income tax proposed in 2026, effective 2028 if enacted. The capital gains excise enacted in 2021 and upheld in 2023. The surcharge added to that excise in 2025. Pending legislation that would decouple Washington from federal Qualified Small Business Stock treatment for the first time. The repeated invalidation of voter initiatives on procedural grounds across two decades. The legislative adoption of initiatives followed by amendment within the same cycle. Dozens of emergency clauses attached to fiscal legislation in non-crisis sessions. Bills introduced to raise the cost of signature gathering. A parental rights initiative adopted unanimously by the legislature, modified the following year, and now the subject of a new citizen petition to restore it.
Individually, each of these events can be defended as constitutionally permissible. The question is not whether each action is likely legal. They probably are. The question is whether the aggregate reflects normal constitutional evolution or a consistent pattern in which available institutional tools have reduced the practical force of voter constraint while preserving formal legality.
Two patterns in particular repeat with enough consistency to warrant examination on their own terms. Voters approved caps on vehicle license fees three times across two decades. None held. Voters rejected graduated income taxation through the constitutional amendment process ten times across generations. Each time, new approaches emerged that produced similar policy outcomes while fitting within (or reclassifying) the existing constraint. These are not isolated grievances. They are the same structure applied to the same category of voter preference, across different subject areas and different decades.
Think of it this way: the user interface of democracy is still intact. The buttons are there: the ballot measure process, the referendum window, the initiative pathway. They look functional. What this piece examines is whether the backend they connect to has been rewired.
A benign model exists. Initiatives are procedurally brittle; courts enforce guardrails that exist for good reasons; emergency clauses are constitutionally authorized; legislatures must govern. On this reading, each outcome here reflects institutions functioning as designed. This piece argues that the density and directional consistency of these outcomes now exceeds what that model predicts. Normal constitutional operation produces friction in both directions. What the record below shows runs consistently one way.
This is not a claim of conspiracy or bad faith. It is a claim about system behavior. No single actor controls this. The pattern emerges from how available tools interact across courts, legislature, executive, and agencies, each operating within its own institutional logic. When multiple lawful mechanisms consistently reduce the practical force of voter constraint, legitimacy can erode even if every individual step is constitutionally defensible.
That question cannot be answered by looking at any single event. It requires watching the sequence play out over time, seeing which direction it moves, and asking whether the velocity and consistency of that direction tells you something the individual events do not. The examples that follow are not offered as an exhaustive dataset. They are offered as a representative sample of a pattern: documented, sequenced, and structurally related, not the only instances that exist.
Foundation
The Floor That Held for Ninety Years
Washington’s Constitution, ratified in 1889, imposed strict requirements on property taxation through Article VII. Section 1 mandates uniformity within property classes. Section 2 caps property tax levies. These were not minor provisions. They were structural commitments about who controls the revenue system and under what constraints.
In 1932, voters approved Initiative 69, enacting a graduated income tax.
In 1933, the Washington Supreme Court invalidated it in Culliton v. Chase, 174 Wash. 363, 25 P.2d 81 (1933). The Court held that income constitutes property under Article VII. Because property taxes must be uniform and capped, a graduated income tax violated the Constitution without amendment. The ruling was categorical and the doctrinal foundation it established was durable: income equals property; property taxes must be uniform; graduated income taxes are unconstitutional absent constitutional change.
What followed was a pattern of voter resistance that spans generations. Ballot measures to amend the Constitution and authorize a graduated income tax failed in 1936, 1938, 1940, 1942, 1944, 1970, 1973, 1975, 1982, and 2010. Ten attempts, none successful. That is not ambiguity about voter preference. That is a structural signal.
For nearly ninety years, the Culliton baseline held.
That baseline was the structural floor. Voters had set it, courts had confirmed it, and ten subsequent attempts to change it through the amendment process had each failed. The constraint was real and it was tested.
What follows is what happened as institutions pursued the same policy goals within the constraint set that voters had repeatedly declined to change.
The Procedural Record, 1999–2015
The Car Tabs: Three Votes, Zero Results
The late 1990s introduced a different kind of friction: voter-approved initiatives colliding with judicial enforcement of procedural rules.
In 1999, Initiative 695 passed with 56 percent approval. It capped vehicle license fees at $30. The Washington Supreme Court struck it down in 2000 for violating the single-subject rule and defective ballot title requirements. Amalgamated Transit Union Local 587 v. State, 142 Wn.2d 183, 11 P.3d 762 (2000).
In 2002, Initiative 776 passed with 51 percent approval, again targeting vehicle license fees. The Court upheld core provisions but preserved preexisting Sound Transit taxes, limiting the measure’s practical reach. Pierce County v. State, 159 Wn.2d 16, 150 P.3d 86 (2006).
In 2019, Initiative 976 passed with 53 percent approval, once more capping car tabs. The Supreme Court invalidated it unanimously in 2020, citing single-subject violations and misleading ballot language. Garfield County Transportation Authority v. State, 196 Wn.2d 814, 479 P.3d 1169 (2020).
From a judicial standpoint, these rulings enforced procedural safeguards embedded in Article II, Section 19. They are defensible on those grounds.
From a voter standpoint, materially similar policy outcomes were approved by majorities three times across two decades. None endured.
Durability is not owed. But repeated invalidation of the same voter preference, for reasons that feel technical to laypeople, creates a predictable legitimacy gap. Neither interpretation is irrational. But the perception gap (between what voters believe they decided and what institutional processes allowed to persist) became part of Washington’s governance environment. That gap does not close simply because the legal analysis is correct. It accumulates.
The car tabs sequence established one pattern. The same years produced another.
Property Taxes: The Pattern Extends
In 2000, Initiative 722 passed with 57 percent approval, establishing a two percent limit on property tax levy increases. The Supreme Court struck it down in 2001 for embodying unrelated subjects in violation of Article II, Section 19. City of Burien v. Kiga, 144 Wn.2d 819, 31 P.3d 659 (2001).
In 2001, Initiative 747 passed with 58 percent approval, reducing the general limit on property tax levy increases from six percent to one percent. The Supreme Court invalidated it in 2007 for violating Article II, Section 37, which requires amendatory laws to set forth the amended law at full length. Washington Citizens Action of Washington v. State, 162 Wn.2d 142, 171 P.3d 486 (2007).
These rulings applied established constitutional provisions. Yet they represent another instance where voter-approved fiscal constraints were nullified on procedural grounds, extending the pattern to property taxation.
Judicial review was not the only institutional lever available.
The Executive Lever
In Washington State Grange v. Locke, 153 Wn.2d 475, 105 P.3d 9 (2005), the Supreme Court upheld Governor Locke’s veto of sections within Engrossed Senate Bill 6453. That bill had enacted a “top two” primary system alongside a “Montana-style” alternative. The veto eliminated the top-two option, leaving the alternative in place amid challenges under Article III, Section 12 and Article II, Sections 19 and 38.
The Court sustained the exercise of executive discretion.
The structural effect was that a legislative choice about election architecture was altered by veto without returning the question to voters. Whether the outcome was correct as policy is separate from what it illustrates about the mechanics available to institutional actors when they want to shape structural outcomes.
The Emergency That Wasn’t
Initiative 960, approved in 2007, required supermajority legislative approval or voter ratification for tax increases and established advisory votes to give citizens a nonbinding voice on tax matters. It took effect under Laws of 2008, Chapter 1.
In 2023, the Legislature repealed the advisory vote requirement through Senate Bill 5082. The bill included an emergency clause, making it effective immediately and blocking referendum.
Article II, Section 1(b) of the Washington Constitution permits emergency clauses. Courts have granted broad deference to legislative declarations of emergency. CLEAN v. State, 133 Wn.2d 455, 928 P.2d 1054 (1997). The constitutional standard for challenging an emergency designation is high.
The structural point is not that the emergency clause was illegal. It was not.
The structural point is that a voter-enacted fiscal accountability mechanism, advisory votes, which gave citizens a nonbinding voice on legislative tax decisions, was repealed under emergency designation. There was no crisis. No disaster. No immediate fiscal collapse that required blocking the 90-day referendum window.
The emergency clause did not just accelerate the bill’s effective date. It foreclosed citizen review of the decision to remove a citizen-review mechanism.
Judicial invalidation continued alongside these new tools.
Charter Schools: The Pattern Beyond Taxes
In 2012, Initiative 1240 passed with 51 percent approval, authorizing up to forty charter schools and designating them as common schools eligible for dedicated funding under Article IX.
The Supreme Court struck down the Act in 2015, holding that charters lacked the voter-elected boards required for common schools, rendering their funding unconstitutional. League of Women Voters of Washington v. State, 184 Wn.2d 607, 355 P.3d 1131 (2015). Because common school funds were central to the Act, the court invalidated it entirely.
Another voter-approved reform nullified on constitutional grounds, adding to the accumulating record of procedural barriers overriding popular mandates.
By 2015, the pattern of post-passage judicial invalidation was well established. What developed next was different. New mechanisms emerged that did not require judicial action at all. The distance between what voters authorized and what they received could now be generated before a court ever got involved.
Sound Transit: The Gap Inside the Framework
In 2015, the Legislature authorized Sound Transit to levy an increased Motor Vehicle Excise Tax as part of the Sound Transit 3 package. Voters approved ST3 in November 2016 with 54 percent approval. The package totaled $54 billion and was funded in part through an MVET increase from 0.3 to 1.1 percent.
The valuation method for the MVET was set by the authorizing legislation. Rather than using current fair market value, Sound Transit applied a 1996 depreciation schedule based on Manufacturer’s Suggested Retail Price, not updated since the 1990s. A ten-year-old vehicle might be assessed at 85 percent of original MSRP rather than its actual depreciated worth. Annual tabs came in hundreds of dollars higher than what many voters expected when they approved ST3.
A class-action lawsuit challenged the MVET on constitutional grounds. The Washington Supreme Court upheld the tax in 2020, finding no constitutional violation. Sound Transit’s counsel stated before the Court that no fraud or deception had occurred. The Court agreed.
The structural observation is narrower than the legal ruling. The valuation methodology was a technical implementation choice embedded in the authorizing legislation. Voters approved the ST3 package as presented. The tab amounts they encountered after passage reflected valuation assumptions not prominently disclosed in ballot materials. In 2021, the Legislature passed SB 5326 phasing in Kelley Blue Book valuations, reducing average tabs by approximately 30 percent, conditioned on delaying certain ST3 capital projects to offset lost revenue.
This instance does not fit the procedural invalidation or adopt-and-amend patterns. No initiative was struck down. No emergency clause was invoked. The mechanism is different: a voter-approved framework produced outcomes materially different from voter expectations through implementation choices made in enabling legislation, upheld by courts, and partially corrected through subsequent legislation conditioned on trade-offs.
A different mechanism was operating at the same time, working not through enabling legislation but through the initiative process itself.
Adopt and Amend
Initiative 940 passed in 2018 with 59 percent approval, mandating police de-escalation training and modifying standards for use of deadly force. The Legislature adopted it directly through the initiative-to-legislature process, avoiding a ballot campaign under the two-thirds amendment threshold. It became law under Laws of 2019, Chapter 1.
Shortly thereafter, the Legislature amended it through Engrossed Second Substitute House Bill 1064, modifying liability provisions.
Legislative authority to amend statutes is unambiguous. The legal analysis is clean.
The structural pattern is what matters here. An initiative qualifies. The Legislature adopts it rather than sending it to the ballot, a choice that prevents public referendum and bypasses the two-thirds threshold for same-session amendment. The Legislature then amends it. The citizen-initiated content is altered without the public engagement the initiative process was designed to enable.
When this cycle repeats, and in Washington it has repeated, it raises a governance design question: Is the initiative-to-legislature pathway functioning as a genuine alternative route for voter expression, or as a mechanism that routes popular measures through an institutional process more permeable to subsequent modification?
New Mechanisms Emerge, 2015–2023
The Capital Gains Pivot
This section requires close attention because it is the doctrinal hinge for everything that follows.
In 2021, the Legislature enacted ESSB 5096, a 7 percent tax on long-term capital gains above $250,000. Codified at RCW 82.87, it was structured not as an income tax but as an excise tax imposed on the sale or exchange of capital assets. That framing was not accidental. The bill’s sponsors stated explicitly that the excise structure was chosen to work within Washington’s constitutional constraints on income taxation rather than challenge them directly.
A Douglas County Superior Court struck it down in 2022, treating it as an unconstitutional income tax.
In March 2023, the Washington Supreme Court reversed in Quinn v. State, 1 Wn.3d 453, 526 P.3d 25 (2023), a 7-2 decision. The Court held that the tax was imposed on a transaction, the act of sale or exchange, rather than on the ownership or receipt of income. That made it an excise tax, not a property tax subject to Article VII’s uniformity and cap requirements. The Court preserved Culliton nominally while narrowing its practical scope. The U.S. Supreme Court denied certiorari in 2024, leaving the ruling intact.
This is a doctrinal realignment.
For nearly ninety years, the rule was clear: income is property; property taxation must be uniform; graduated rates are unconstitutional. After Quinn, at least some forms of realized income, specifically long-term gains upon sale of capital assets, are classified as excise events outside that framework.
The Court’s distinction is grounded in recognized excise doctrine. Washington has long upheld excise taxes on transactions. Real estate excise taxes. Business and occupation taxes. The doctrinal parallel is not invented.
But the boundary matters enormously.
The critical question is not whether Quinn was correctly decided. It is what principle limits the excise classification going forward. The court held that the taxable incident is the act of sale or exchange. But if the legislature can define the taxable incident with sufficient granularity, what prevents increasingly ordinary economic receipts from being labeled transactional events rather than income? How much transactionality is required? What keeps “receipt” from being reframed as “event”?
Quinn did not answer that. SB 6346, which taxes the “receipt of income” rather than a discrete sale, tests whether the current court will hold the line Quinn drew or treat the excise frame as scalable to ordinary income. The boundaries remain untested.
That ambiguity is not a flaw in this analysis. It is the structural vulnerability.
This is not a theoretical framework. It is a description of what happened with capital gains, and it frames what is now being attempted with the proposed millionaire income tax.
The Acceleration, 2023–2026
The Pattern Beyond Tax Doctrine
Two additional invalidations in this period extend the pattern beyond tax doctrine.
In 2023, Spokane voters approved Proposition 1 with 75 percent approval, banning camping near schools, parks, and playgrounds. The Washington Supreme Court invalidated it in 2025, ruling that it exceeded local initiative scope under RCW 35A.11.090 and violated single-subject requirements.
In 2024, Initiative 2066 passed statewide. It aimed to preserve natural gas access by rolling back energy code changes favoring heat pumps. A King County Superior Court invalidated it in March 2025 for single-subject violations under Article II, Section 19 and failure to include full statutory text of altered laws. The case advanced to the Supreme Court in 2025 with arguments heard but no final ruling as of this writing.
Both invalidations followed recognized procedural doctrines.
Both overrode clear popular majorities.
The accumulation of instances, car tabs, Spokane Prop 1, Initiative 2066, is not evidence of conspiracy. It is evidence of a recurring structural dynamic: voter-approved measures reaching courts on procedural grounds and failing. Whether that reflects rigorous constitutional enforcement or selective application is a question courts themselves may eventually have to address as the pattern becomes harder to characterize as coincidental.
Absorb Rather Than Fight
In 2024, Initiative 2111 was filed to prohibit state and local personal income taxes, defined through federal gross income. Rather than sending it to the ballot, the Legislature adopted it directly under the initiative-to-legislature framework. It passed with bipartisan support, House 76-21, Senate 38-11, and took effect June 6, 2024.
The adoption reflected durable political reality. Income tax prohibition remains one of the few consistent cross-partisan commitments in Washington electoral history. The Legislature, by adopting rather than fighting the initiative, avoided a ballot campaign it would likely have lost.
But adoption through the initiative-to-legislature pathway does something that ballot adoption does not. It converts a citizen-initiated measure into a regular statute, amendable by simple legislative majority in future sessions. The two-thirds threshold that would otherwise protect same-session amendments does not apply once the session in which the initiative was adopted has ended.
SB 6346 in 2026 proposes to amend Initiative 2111 directly.
Across decades, the pattern runs in one direction. Voters signal clear opposition to income taxes, repeatedly. The Legislature adopts the initiative rather than fight it. Then the Legislature proposes to amend what it just adopted.
That sequence can be read as institutional adaptation. It can also be read as tactical sequencing.
The Parents’ Bill: Adopted, Then Amended
Initiative 2081, the “Parents’ Bill of Rights,” was certified in January 2024 with over 449,000 signatures. It enumerated fifteen rights for parents of public school children including rights to review curriculum, receive notifications about student health matters, and opt out of certain instruction. The Legislature adopted it in March 2024, House 82-15, Senate 49-0, unanimous in the upper chamber, effective June 6, 2024.
Twelve months later, HB 1296 amended it.
Signed by Governor Bob Ferguson in May 2025, the amendment eliminated prior notification requirements for certain medical services and added gender-inclusive policy provisions. A companion bill, SB 5181, modified records access provisions. HB 1296 included an emergency clause, making it effective immediately and blocking referendum on the amendment.
The pattern here is not subtle. A measure that passed 49-0 in the Senate was adopted without a ballot fight, precisely because unanimous opposition would have made a ballot fight futile. The following session, it was amended under emergency designation, foreclosing citizen review of that amendment.
Republicans including Representative Skyler Rude described it as a bait-and-switch: adopt to prevent a ballot supermajority threshold from triggering, then amend. That characterization is politically charged. Adoption followed by emergency-shielded amendment within one legislative cycle compresses the window in which citizens can respond through normal democratic channels.
In 2026, Initiative IL26-001 was certified with over 418,000 signatures to restore the original I-2081. The Legislature has declined hearings. If not adopted, it proceeds to the November 2026 ballot.
The cycle continues.
Excise Expansion and the QSBS Gap
After Quinn, the capital gains framework did not remain static.
In 2025, ESSB 5813 added a 2.9 percent surcharge on capital gains exceeding $1 million, effective January 1, 2025, producing a combined 9.9 percent rate on excess amounts.
The federal Qualified Small Business Stock exclusion under IRC Section 1202 allows founders and early investors to exclude up to 100 percent of gains on qualifying stock held more than five years in a C-corporation with assets under $50 million at issuance. Startups are high-risk. Section 1202 is a mechanism to make that risk economically reasonable.
Washington currently conforms to the federal QSBS exclusion by design. Because Washington’s capital gains excise begins with federal net long-term capital gain, gains excluded federally under Section 1202 never enter the Washington tax base. The Washington Department of Revenue confirms this explicitly: qualifying QSBS gains excluded from federal net long-term capital gain are not subject to Washington’s excise. A founder who qualifies for the federal exclusion pays $0 in Washington state capital gains tax on that exit.
That is the current state of the law.
Senate Bill 6229 and companion House Bill 2292, introduced in January 2026, would change this. They propose requiring taxpayers to add back Section 1202 excluded gains when calculating Washington’s capital gains excise — effectively decoupling Washington from the federal QSBS treatment for the first time. At a January 2026 hearing, startup founders and venture capitalists testified against the bills. The bills remain in committee as of this writing.
If enacted, a founder with a $2 million qualifying exit would owe $0 in additional federal tax and $151,500 in Washington state capital gains tax on the same gain. Under current law, the state tax is also $0.
This is not a gap that has existed since the excise was enacted. It is a proposed expansion of the excise base to capture gains that federal policy deliberately exempts. It illustrates the doctrinal point precisely: the excise classification established in Quinn has proven expansible without additional constitutional challenge. The limiting principle that was left untested in Quinn has not constrained subsequent legislative proposals.
This matters for Washington’s competitiveness in technology and life sciences. It matters for founders and early-stage investors making location decisions. And it matters doctrinally because the same mechanism that produced the capital gains excise is now being proposed as the vehicle for taxing gains that Congress specifically chose not to tax.
Raising the Cost of the Petition
In 2025, SB 5382 required signature gatherers to personally certify the validity of each signature under penalty of perjury. Proponents argued it reduced fraud. Opponents argued it would triple qualification costs, based on analogous experience in Oregon, and expose gatherers to legal liability without evidentiary basis. The bill died in committee.
In 2026, SB 5973 proposed to ban per-signature compensation, require hourly or salaried payment for gatherers, and mandate 1,000 qualifying signatures before the Secretary of State would issue a ballot title, a requirement that would force organizers to fund significant signature collection before even knowing the official title under which they were collecting. Lead sponsor Senator Javier Valdez described the legislation as targeting “aggressive, misleading tactics” incentivized by per-signature pay models. The bill died February 17, 2026 without a floor vote, the deadline for non-budget legislation. Senator Valdez indicated plans to revisit the restrictions in 2027.
The 2025 legislative session recorded approximately 47 bills carrying emergency clauses, a frequency that exceeds historical norms for non-crisis years. Among them: emergency clauses on fiscal and policy legislation where no immediate exigency was apparent from the record.
Senator Pedersen, as Senate Majority Leader, stated publicly that the Legislature would not pass the 2026 initiatives on parental rights restoration and girls’ sports, effectively signaling that those measures would bypass committee review and proceed directly to the ballot. House Speaker Laurie Jinkins provided similar signals. These are procedural choices that, individually, are within legislative discretion. As a pattern, they communicate something about how leadership views citizen-initiated policy as distinct from legislative policy.
The Millionaire Tax: Where It All Converges
SB 6346 proposes a 9.9 percent tax on income above $1 million, effective 2028. It passed the Senate on February 16, 2026, 27-22, along party lines. It is now in the House.
The bill explicitly amends Initiative 2111 to exempt this tax from the income tax prohibition. It projects approximately $3.4 billion annually, attributable to roughly 21,000 filers.
It includes an emergency clause.
Article II, Section 1(b) exempts from referendum laws deemed necessary for the immediate preservation of the public peace, health, or safety, or for the support of the state government and its existing public institutions, and courts grant broad deference to legislative declarations.
The millionaire income tax did not arise from a natural disaster, a public health emergency, or an imminent fiscal collapse. Washington is not in a state of fiscal crisis that forecloses a 90-day referendum window. The emergency clause on this bill removes the referendum option before citizens who opposed the measure in Senate testimony, over 61,000 signed against it in hearings, can exercise their constitutional right to challenge it at the ballot.
Here is what that bypass layer looks like structurally:
The emergency clause is almost certainly constitutionally authorized. Courts will likely defer. That is not the question.
The question is what purpose it serves when applied to a contested major tax bill with no emergency justification in the record. When emergency clauses become a routine tool for shielding controversial fiscal legislation from citizen review, the referendum power remains on paper while diminishing in function. The emergency clause is increasingly used as a referendum-avoidance mechanism on contested issues where the urgency is political rather than operational.
What the Sequence Reveals
The Routing Map
When all the institutional mechanisms described above operate in the same political environment, Washington’s governance system functions as a multi-layer routing engine. Citizen participation is not blocked, it is channeled through paths that are longer, more expensive, more procedurally vulnerable, and more readily preempted.
When all the institutional mechanisms described above operate in the same political environment, Washington’s governance system functions as a multi-layer routing engine. Citizen participation is not blocked, it is channeled through paths that are longer, more expensive, more procedurally vulnerable, and more readily preempted.
Every branch of this diagram is legally defensible. None requires misconduct. The system routes the way it routes because the mechanisms available to institutional actors are more numerous and more resilient than the mechanisms available to citizens.
The system still accepts input, but it has become increasingly resistant to correction.
The Sequence Assembled
Laid out chronologically, what has occurred is this:
In 1933, the Culliton court classified income as property and barred graduated income taxation absent constitutional amendment. Voters confirmed that barrier by rejecting amendment across a generation. In 1999, 2002, and 2019, voters approved caps on vehicle license fees. Courts invalidated all three on procedural grounds. In 2007, voters enacted supermajority requirements for tax increases and advisory votes. In 2018, voters approved a police accountability initiative that was adopted and amended within one cycle. In 2021, the Legislature enacted a capital gains tax structured as an excise on transactions, a framing chosen, by the sponsors’ own account, to work within the Culliton constraint rather than challenge it. In 2023, the Supreme Court upheld the excise classification in Quinn, narrowing the Culliton barrier without overruling it. In 2024, voters’ proxy initiative banning income taxes was adopted legislatively, and the bill that would amend it arrived the following year. Also in 2024, a parental rights initiative was adopted unanimously and amended the following session under emergency clause. Also in 2024, Initiative 2066 on natural gas access was approved by voters and invalidated at the superior court level in 2025 on procedural grounds, with Supreme Court review pending as of this writing. Spokane’s Proposition 1 followed the same arc. In 2025 and 2026, bills to restrict initiative mechanics were introduced. In 2026, the Legislature passed a millionaire income tax bill that amends the income tax prohibition initiative and includes an emergency clause to foreclose referendum.
Each step is individually defensible.
The accumulation moves consistently in one direction.
Cumulatively, they trace a directional line: nominal retention of the Culliton income barrier; excise classification expanding to absorb realized gains; startup gains taxable without federal alignment; voter initiatives repeatedly invalidated or amended post-adoption; initiative mechanics facing proposed restriction; emergency clauses shielding contested legislation from referendum review; and a velocity of activity in the 2023–2026 period that substantially exceeds the pace of prior decades.
That acceleration matters. The density of constraint-adjacent activity in recent years is not consistent with gradual constitutional evolution. It is consistent with institutional urgency.
The Counterarguments
This analysis has a responsibility to engage the strongest counterarguments.
On Quinn: The majority distinguished realized capital gains from general income on the grounds that the taxable incident is the transaction, not the ownership or receipt. That distinction has doctrinal support in Washington excise law and was applied carefully. Mahler v. Tremper, 40 Wn.2d 405, 243 P.2d 627 (1952), recognized excises on the exercise of property rights. The question is not whether Quinn was a plausible application of excise doctrine. It was. The question is whether its limiting principle, transactional framing as the determinative factor, is robust enough to contain what comes next. SB 6346 applies to the “receipt of income,” not to a discrete sale event. That distinction should, under Quinn‘s own logic, make SB 6346 more vulnerable. Whether the current court treats it that way is an open question.
On emergency clauses: Courts defer broadly. CLEAN v. State established that standard clearly. The constitutional text provides no objective threshold for what constitutes an emergency. The remedy for abuse, if abuse is occurring, is political rather than judicial in most cases. The structural critique is not that courts will or should intervene, they probably won’t, but that institutional actors understand this and factor it into their choices. Routine use of emergency clauses for non-emergency policy is a rational institutional strategy precisely because it is judicially durable. In 2025 alone, 47 such clauses were enacted. Washington averaged fewer than 15 emergency clauses per session in the decade prior to 2020. The frequency has more than tripled.
On initiative invalidation: The single-subject rule and ballot title requirements serve genuine constitutional purposes. Logrolling, combining unrelated provisions to build coalitions that wouldn’t otherwise exist, is a real concern that courts are right to police. There is also a defensible design rationale for applying these rules more strictly to citizen initiatives than to legislative enactments: initiatives are drafted outside the committee process, without the vetting that filters imprecision before a bill reaches the floor. Stricter procedural scrutiny of citizen-drafted law is not inherently arbitrary, it reflects a structural difference in how the two types of law are produced.
That rationale, however, does not dissolve the asymmetry, it explains its origin. The result in practice is that the same procedural standards that citizen measures must survive are not consistently applied to legislative alternatives that combine multiple subjects, attach emergency clauses to combined-purpose bills, or amend initiatives in ways that substantially alter their scope. The asymmetry may have a legitimate genealogy. Its cumulative effect on the balance between citizen and legislative authority is the same regardless.
On QSBS: Washington currently conforms to the federal QSBS exclusion implicitly, by starting from federal net long-term capital gain. The structural point is that SB 6229 would deliberately decouple that conformity — not to close an oversight, but to expand the excise base. That is a different kind of action than a pre-existing gap.
The thesis is falsifiable. If emergency clauses were rare and tied to demonstrable urgency, if excise classification remained narrowly confined to discrete sales events, if initiative amendments were infrequent and substantively limited, and if initiative restrictions were introduced in periods of political calm rather than during active citizen contestation, the pattern described here would dissolve. The argument depends on the pattern’s density, velocity, and directional consistency.
Disdain or Design?
Disdain in constitutional governance rarely appears as open contempt. It does not require a recorded statement or an explicit intent to override voter will. It appears as patterned reliance on procedural mechanisms that reduce the practical force of direct democratic constraint while preserving formal legality.
The sequence described in this piece supports two interpretations.
The first: Washington’s institutions are navigating a genuine structural tension between a nineteenth-century constitutional framework and twenty-first-century fiscal demands. The excise classification in Quinn reflects legitimate doctrinal development. Emergency clauses are almost certainly constitutionally authorized. Initiative invalidations enforce procedural requirements. The Legislature has authority to amend what it adopts. None of these actions individually represents a departure from constitutional design.
The second: The aggregation of these mechanisms, particularly their density in the 2023–2026 period and their consistent directional effect of narrowing voter constraint, reflects something beyond coincidence. Whether that reflects explicit coordination or emergent institutional preference for policy control over consent legitimacy is a harder question. But the outcome is the same either way.
Others looking at this sequence have read it as evidence of intent. That reading is available. This analysis does not rely on it. The argument stands on mechanism and documented effect. Intent would make the pattern more troubling. The absence of intent would not make it less real.
What this piece asserts is that the pattern exists, that its velocity has increased, and that the mechanisms employed produce a consistent result: each one individually lawful, each one incrementally reducing the friction that direct democracy applies to legislative outcomes.
The Systemic Hazard
The risk this piece is concerned with is not taxation.
Washington will raise or lower taxes. Courts will continue to apply constitutional standards. Initiatives will qualify or fail. These are normal features of a functioning state.
The risk is something more durable and more difficult to reverse: legitimacy erosion.
This is the backend problem. The user interface of democracy still renders correctly. The initiative process exists. The referendum window exists. The constitutional amendment pathway exists. Citizens can still vote. Their votes still count. But the mechanisms that translate those votes into durable policy outcomes have been progressively routed around, reclassified, absorbed, or shielded, each step individually legal, the cumulative effect something different.
Constitutional systems depend on a belief that constraints are real, that when voters say no, it means something; that when citizens sign an initiative and see it pass, it will not be reliably nullified, adopted-and-amended, or shielded from referendum in the same cycle; that emergency powers are for emergencies; that doctrinal interpretation is disciplined rather than instrumental.
When lawful tools are repeatedly used in ways that make major decisions difficult to reverse through normal citizen checks, elected office can remain representative in form while becoming directive in function.
When that belief weakens, formal legality becomes insufficient. Citizens who believe that participation is performative rather than determinative do not simply become disengaged, they become available to alternatives that promise to bypass the institutions they no longer trust. That dynamic has played out in other contexts and at other scales. Washington is not immune to it.
The nearest documented precedent is California’s Proposition 13 in 1978. Voters passed a hard cap on property tax increases via ballot measure. The legislature responded with fees, bonds, and special assessment districts that produced equivalent revenue through mechanisms the cap did not reach. The cap remained on paper. The constraint it represented eroded in practice. Trust in the fiscal system declined. The state’s budget architecture became progressively less legible to ordinary citizens. That outcome was not the result of a single bad actor or a single bad decision. It was the cumulative product of institutions finding lawful paths around a voter-imposed constraint, each path individually defensible, the aggregate effect something the voters who passed Proposition 13 did not authorize and could not easily reverse.
The hazard is not the millionaire income tax in isolation. It is not Quinn. It is not any single initiative invalidation or emergency clause.
It is the accumulation of technical compliance in service of functional constraint erosion. This critique applies regardless of which side benefits in a given cycle. The hazard is the precedent and the tool normalization, mechanisms that outlast any particular majority and remain available to whoever holds them next.
Washington is not unique in this dynamic. It may be ahead of the curve. The same interaction between initiative processes, judicial review, and legislative absorption is visible in other states at earlier stages. What makes Washington worth examining now is the velocity, the compression of decades of incremental drift into a few legislative sessions.
Constitutional systems do not usually fail through overt violation. They fail through incremental, lawful actions that alter the practical balance of power without amending the text that describes it.
That is the unmitigated risk.
Not the bill.
Not the case.
The sequence.
Related Reading
This piece connects to patterns documented elsewhere on this site.
Washington’s Housing Affordability Crisis examines how a similar structure operates in land use: individually defensible zoning rules, permitting requirements, and fees whose cumulative effect is an outcome no single rule intended. The mechanism is the same. Individual legality, aggregate impossibility.
“A Few Hours” and the Slow Erosion of Auditable Commitments documents how institutions in regulated industries rationally optimize for the vaguest compliance commitment that still passes audit when the standard for review is subjective rather than measurable. Emergency clause declarations without defined thresholds follow the same logic.
The Impossible Equation covers the collapse of the global internet’s legitimacy as a shared system, how a structure that worked because participants believed in its integrity erodes once enough of them stop. The domain is different. The mechanism is not.
Chamath posted this week: “Is on-premise the new cloud? I’m beginning to think yes. It’s the only way for companies to not blow themselves up and have some semblance of capability in an AI world.” Jason Fried dropped a link to Basecamp’s cloud exit and five words: “Saving us $10M, at least.”
Most people read this as a cost conversation. It’s not. Cost is the part that’s easy to measure. The structural problem underneath is harder to see and harder to fix. The cloud lets you rent compute and keep control. AI doesn’t offer that deal.
The cloud deal changed
Cloud worked because compute was deterministic. Both sides ran code. AWS ran millions of lines of service code. You ran your application. When something broke, you could trace it. Their bug or your bug, but someone’s bug, and the behavior was reproducible. The shared responsibility model worked because the boundary was clear. Provider secures the infrastructure; you secure what runs on it. Both sides knew which side of the line they were on.
AI breaks that. Not because there’s suddenly code you don’t control. That was always true in cloud. What’s new is behavior that isn’t traceable to anyone’s code in the traditional sense. A provider updates the model, and your system behavior changes. The model isn’t buggy. It’s probabilistic. Nobody wrote a line of code that says “produce this different output.” New failure modes show up without any deployment on your end. Pricing shifts once you’re locked in. Your data may be training their next competitive advantage. The model’s behavior isn’t infrastructure, and it isn’t your code. It’s a third thing, and it doesn’t fit on either side of the old responsibility boundary.
This isn’t renting infrastructure anymore. It’s renting capability. And the difference matters, because when AI becomes core to the product, whoever owns the capability layer owns the product. Everything else is a wrapper.
Liability doesn’t outsource
When your upstream model changes behavior and you violate a regulation, misprice risk, or produce unlawful output, that’s your problem. Not the API provider’s. Control and responsibility don’t decouple just because you didn’t train the weights.
Courts are already working through this, and the early results are clarifying.
In January 2026, the consolidated NYT v. OpenAI copyright litigation produced a discovery order compelling OpenAI to hand over 20 million anonymized ChatGPT logs. OpenAI had proposed the sample size itself, then tried to walk it back to keyword-filtered subsets. The court said no. Users who voluntarily submit conversations to a third-party platform have limited privacy protections over those interactions. Twenty million logs, 0.5% of the tens of billions OpenAI retains, and the court found that proportional.
Every conversation your team has with a hosted model is a record on someone else’s infrastructure, subject to someone else’s legal disputes.
Then on February 10, Judge Rakoff ruled in United States v. Heppner that 31 documents a defendant created using a commercial AI tool and shared with his defense attorneys aren’t privileged. Not attorney-client privilege, not work product. The court found “not remotely any basis” for protection. The AI platform isn’t an attorney; its terms disclaim any such relationship, and sending pre-existing unprivileged documents to a lawyer doesn’t retroactively create privilege. The government compared it to Google searches. Running a search and sharing results with your attorney doesn’t make the search history privileged.
Same direction, both cases. When you run your thinking through a third-party AI platform, you create discoverable records on infrastructure you don’t control, under terms you probably haven’t read carefully, with no privilege protection even if you later involve counsel.
Externalize capability. Retain liability.
Competing on rented capability
There’s a reason major retailers avoid AWS. Amazon is their competitor. Running your recommendation engine, pricing logic, or supply chain optimization on a competitor’s infrastructure isn’t philosophical. It’s operational. They see your usage patterns, your scale, your growth trajectories.
The same dynamic is showing up with AI providers. Build differentiated capabilities on a hosted model, and the provider has visibility into what you’re building and how. Your usage patterns become their product intelligence, whether or not they train on your data directly. You’re renting AI capabilities from the same companies you’re trying to compete with. Hard to build moats on someone else’s foundation.
Confidential compute solves one dimension
The obvious technical response to the privacy problem is confidential computing. Run the model inside a hardware enclave so even the infrastructure operator can’t see your data.
Moxie Marlinspike launched Confer in December. The Signal playbook applied to AI. End-to-end encrypted inference inside a Trusted Execution Environment. The host never sees your conversations. Architecturally private, not policy-private. As Marlinspike put it, AI chat logs reveal how you think, and once advertising arrives (it already has at OpenAI), “it will be as if a third party pays your therapist to convince you of something.”
Tinfoil takes a more general approach, building a confidential computing platform on NVIDIA’s Hopper and Blackwell GPUs with open-source verification and cryptographic attestation. They’re collaborating with Red Hat on open-source confidential AI infrastructure and recently joined the Confidential Computing Consortium. Privacy of on-prem, convenience of cloud, backed by hardware rather than promises.
Apple’s Private Cloud Compute is the big-company version. Extend the device security model to cloud inference with attestable guarantees about what code handles your request.
All serious work. All a long road.
The hardware foundations keep getting hit. Intel SGX has been battered by years of side-channel attacks. AMD SEV has had its own issues. Intel TDX, the newer play, just went through a joint security review with Google’s bug hunters that surfaced real problems. Each generation improves. None are yet where you’d stake regulatory compliance on the enclave boundaries holding against a motivated attacker with physical access.
But even if confidential compute fully matures, even if you can cryptographically guarantee nobody sees your data during inference, you’ve only solved one dimension of the problem.
Data privacy doesn’t fix model behavior. A provider pushes an update, your outputs change, and confidential compute didn’t help. Your data was private the whole time. Your system still broke.
Privacy is necessary. Ownership is the harder problem.
The infrastructure is catching up
The historical objection to “just run it yourself” was operational. Cloud won because it made infrastructure someone else’s problem. APIs, elastic scaling, managed services, no procurement cycles. Going on-prem meant going backward on developer experience and velocity.
That gap is closing. Oxide builds rack-scale systems that bring cloud architecture to hardware you own. API-driven infrastructure, elastic storage, integrated networking. Not commodity servers you’re left to assemble, but a single integrated system purpose-built from hardware through operating system. They’ve raised roughly $300 million to date and their customers include Lawrence Livermore National Laboratory and CoreWeave.
Bryan Cantrill, Oxide’s CTO, resists the term “private cloud.” He calls it “on-premises elastic infrastructure” because private cloud historically meant duct-taping multi-vendor stacks together and hoping. Oxide was built from scratch, so the operational model actually works.
37signals proved the economics. Moving seven applications off AWS onto their own hardware saved $10 million over five years on a hardware investment that paid for itself in six months. But cost was always the easy argument. The harder one, the one Chamath is circling, is about control over what actually makes your product work. Not just the servers. The model versioning, the update cadence, the safety filters, the logging policy, and the alignment decisions. Capability evolution on your timeline, not someone else’s. Enterprise contracts can promise some of this. Version pinning, indemnification, non-training guarantees. But contractual assurances are not the same as technical control over capability evolution. A contract says they won’t change your model without notice. Ownership means they can’t.
The common middle ground is hybrid. Train in the cloud, run inference on-prem. That works for latency and cost. It doesn’t solve the ownership problem. If you’re still pulling model updates from an upstream provider, you’ve moved the compute but not the dependency. The failure mode is the same. It just happens on your hardware.
There’s a harder version of this objection. Model capabilities are still compounding. If you pin an open-weights model on your own rack for stability and control, but your competitor rides the frontier API curve, they’re accepting volatility in exchange for raw intelligence. Stability is the right metric for infrastructure. For capability, sometimes you need the smartest model available, even if it’s unpredictable. The on-prem bet only works long-term if open-weights models keep pace with closed-source APIs. If they don’t, ownership becomes a stability play at the cost of falling behind the intelligence frontier.
And for most companies, training or fine-tuning a frontier model isn’t realistic. They don’t have the data, the talent, or the compute budget. The API dependency isn’t a bad decision. It’s the only one available. Which means this isn’t a trade-off most organizations can avoid. It’s one they need to understand clearly, because the costs of not understanding it are compounding in courtrooms and competitive markets right now.
The access problem
If the answer to AI privacy and control is “own the infrastructure,” we already know who can afford that and who can’t.
Enterprises with budget and technical depth will run their own inference on their own hardware. They’ll pin model versions, control their data, keep their logs out of other people’s lawsuits. The well-resourced get privacy, control, and capability independence.
Everyone else gets the free tier. Their conversations live on someone else’s servers, train someone else’s models, show up in someone else’s discovery obligations, and get monetized through advertising that knows exactly how they think. This is the most intimate technology ever built, and access to the private version of it tracks directly to the ability to pay.
This pattern isn’t new. Same split as healthcare, education, and legal representation. But AI sharpens it because the privacy gap isn’t about what you can afford to buy. It’s about what you’re forced to reveal by using the product at all.
The consumer version plays out in personal AI. Local models on personal hardware will happen. They’re already happening. But the timeline to frontier parity is longer than the optimists claim, and the cost of the hardware isn’t trivial. The people who can afford local inference or premium privacy tiers will opt out of the surveillance model. Everyone else won’t have the choice.
This is where confidential compute matters most. Not for enterprises, who solve the problem with hardware and headcount, but for the everyone-else case. If Confer or Tinfoil, or Apple PCC can make private inference the default rather than the premium option, if the cryptographic guarantees get strong enough that you don’t need to own the rack to own your data, that changes the access equation.
It doesn’t solve the capability ownership problem. Companies building products on AI will still need to control their model stack. But it could mean that using AI doesn’t require surrendering the record of how you think to whoever runs the server.
That’s one leg of the problem. A meaningful one. The other legs, model behavior stability, capability independence, and liability alignment, still require ownership for anyone building on top of these systems.
Where this goes
The cloud era trained everyone to think of infrastructure as a commodity you rent. For deterministic compute, that was right. The cycles did what you told them. Responsibility was clear.
AI couples capability to liability in a way cloud computing never did. The compute isn’t just running your logic. It’s making decisions, generating records, and creating obligations that follow you regardless of where the model runs or who trained it.
Ownership is becoming the default for anything that touches the capability layer. The infrastructure to make that viable is catching up. The open-weights ecosystem has to keep pace for it to work. And the question of who gets access to the private, controlled version of AI versus who’s stuck with the surveilled version will define the next decade of policy fights.
Renting capability means renting decisions you don’t control while keeping consequences you can’t outsource.
This is a long one. But as a great man once said, forgive the length, I didn’t have time to write a short one.
The industry has been going back and forth on where agent identity belongs. Is it closer to workload identity (attestation, pre-enumerated trust graphs, role-bound authorization) or closer to human identity (delegation, consent, progressive trust, session scope)? The answer from my perspective is human identity. But the reason isn’t what most people think.
The usual argument goes like this. Agents exercise discretion. They interpret ambiguous input. They pick tools. They sequence actions. They surprise you. Workloads don’t do any of that. Therefore agents need human-style identity.
That argument is true but it’s not the load-bearing part. The real reason is simpler and more structural.
Think about it this way. A robot arm on an assembly line is bolted to the floor. It’s “Arm #42.” It picks up a bolt from Bin A and puts it in Hole B. If it tries to reach for Bin Z, the system shuts it down. It has no reason to ever touch Bin Z. That’s workload identity. It works because the environment is closed and architected.
Now think about a consultant hired to “fix efficiency.” They roam the entire building. They’re “Alice, acting on behalf of the CEO.” They don’t have a list of rooms they can enter. They have a badge that says “CEO’s Proxy.” When they realize the problem is in the basement, the security guard checks their badge and lets them in, even though the CEO didn’t write “Alice can go to the basement” on a list that morning. The badge isn’t unlimited access. It’s a delegation primitive combined with policy. That’s human identity. It works because the environment is open and emergent.
Agents are the consultant, not the robot arm. Workload identity is built for maps: you know the territory, you draw the routes, if a service goes off-route it’s an error. Agent identity is built for compasses: you know the destination, but the route is discovered at runtime. Our identity infrastructure needs to reflect that difference.
To be clear, I am not suggesting agents are human. This isn’t about moral equivalence, legal personhood, or anthropomorphism. It’s about principal modeling. Agents occupy a similar architectural role to humans in identity systems. Discretionary actors operating in open ecosystems under delegated authority. That’s a structural observation, not a philosophical claim.
A fair objection is that today’s agents mostly work on concrete, short-lived tasks. A coding agent fixes a bug. A support agent resolves a ticket. The autonomy they exercise is handling subtle variance within a well-defined scope, not roaming across open ecosystems making judgment calls. That’s true, and in those cases the workload identity model is a reasonable fit.
But the majority of the value everyone is chasing accrues when agents can act for longer periods of time on more open-ended problems. Investigate why this system is slow. Manage this compliance process. Coordinate across these teams to ship this feature. And the longer an agent runs, the more likely it is to need permissions beyond what anyone anticipated at the start. That’s the nature of open-ended work.
The longer the horizon and the more open the problem space, the more the identity challenges described here become real engineering constraints rather than theoretical concerns. What follows is increasingly true as agents move in that direction, and every serious investment in agent capability is pushing them there.
Workload Identity Was Built for Closed Ecosystems
Think about how workload identity actually works in practice. You know which services are in your infrastructure. You know which service talks to which service. You pre-provision the credentials or you set up attestation so that the right code running in the right environment gets the right identity at boot time. SPIFFE loosened some of the static parts with dynamic attestation, but the mental model is still the same: I know what’s in my infrastructure, and I’m issuing identity to things I control.
That model works because workloads operate in closed ecosystems. Your Kubernetes cluster. Your cloud account. Your service mesh. The set of actors is known. The trust relationships are pre-defined. The identity system’s job is to verify that the thing asking for access is the thing you already decided should have access.
Agents broke that assumption.
An MCP client can talk to any server. An agent operating on your behalf might need to interact with services it was never pre-registered with. Trust relationships may be dynamic, not pre-provisioned, and the more open-ended the task the more likely that is true. The authorization decisions are contextual. Sometimes a human needs to approve what’s happening in real time. An agent might need to negotiate access to a resource that neither you nor the agent anticipated when the mission started.
None of that fits the workload model. Not because agents think or exercise judgment, but because the ecosystem they operate in is open. Workload identity was built for closed ecosystems. The more capable and autonomous agents become, the less they stay inside them.
Discovery Is the Problem Nobody Wants to Talk About
The open ecosystem problem goes deeper than just “agents interact with arbitrary services.” The whole point of an agent is to find paths you didn’t anticipate. Tell an agent “go figure out why certificate issuance is broken” and it might follow a trail from CT logs to a CA status page to vendor Slack to a three-year-old wiki page to someone’s personal notes. That path isn’t architected. It emerges from the agent reasoning about the problem.
Every existing authorization model assumes someone already enumerated what exists.
System
Resource Space
Discovery Model
Auth Timing
Trust Model
SPIFFE
Closed, architected
None, interaction graph is designed
Deploy-time
Static, identity-bound
OAuth
Bounded by pre-registered integrations
None, API contracts exist
Integration-time + user consent
Static after consent
IAM
Closed, catalogued
None, administratively maintained
Admin-time
Static, role-bound
Zero Trust
Bounded by inventory and policy plane
None, known endpoints
Per-request
Session-scoped, contextual
Browser Security
Open, unbounded
Full, arbitrary traversal
Per-request, per-capability
None, no accumulation
Agentic Auth (needed)
Open, task-emergent
Reasoning-driven, discovered at runtime
Continuous, intra-task
Accumulative, task-scoped
Every model except browser security assumes a closed resource space. Browser security is the only open-space model, but it doesn’t accumulate trust. Agents need open-space discovery with accumulative trust. Nothing in the current stack does both.
Structured authorization models assume you can enumerate the paths. But enumeration kills emergence. If you have to pre-authorize every possible resource an agent might touch, you’ve pre-solved the problem space. That defeats the purpose of having an agent explore it.
The security objection here is obvious. An agent “discovering paths you didn’t anticipate” sounds a lot like lateral movement. The difference is authorization. An attacker discovers paths to exploit vulnerabilities. An agent discovers paths to find capabilities, under a delegation, subject to policy, with every step logged. The distinction only holds if the governance layer is actually doing its job. Without it, agent discovery and attacker reconnaissance are indistinguishable. That’s not an argument against discovery. It’s an argument for getting the governance layer right.
The Authorization Direction Is Inverted
Workload identity is additive. You enumerate what’s permitted. Here’s the role, here’s the scope, here’s the list of services this workload can talk to. Everything outside that list is denied.
Agents need something different. Not pure positive enumeration, but mixed constraints: here’s the goal, here’s the scope you’re operating in, here’s what’s off limits, here’s when you escalate. Access outside the defined scope isn’t default-allowed. It’s negotiable through demonstrated relevance and appropriate oversight.
That’s goal-scoped authorization with negative constraints rather than positive enumeration. And before the security people start hyperventilating, this doesn’t mean “default allow with a blacklist.” That would be insane. Nobody is proposing that.
What it actually looks like is how we scope human delegation in practice. When a company hires a consultant and says “fix our efficiency problem,” they don’t hand them a list of every room they can enter, every file they can read, every person they can talk to. They give them a badge, a scope of work, a set of boundaries (don’t access HR records, don’t make personnel decisions), escalation requirements (get approval before committing to anything over $50k), and monitoring (weekly check-ins, expense reports, audit trail). That’s not default allow. It’s delegated authority with boundaries, escalation paths, and oversight.
The constraints are a mix of positive (here’s your scope), negative (here’s what’s off limits), and procedural (here’s when you need to ask). To be fair, no deployed identity protocol fully supports this mixed-constraint model today. OAuth scopes are basically positive enumeration. RBAC is positive enumeration. Policy grammars that can express mixed constraints exist (Cedar and its derivatives can express allow, deny, and escalation rules against the same resource), but nobody has deployed them for agent governance yet.
The mixed-constraint approach is how we govern humans organizationally, with identity infrastructure providing one piece of it. But the human identity stack is at least oriented in this direction. It has the concepts of delegation, consent, and conditional access. The workload identity stack doesn’t even have the vocabulary for it, because it was never designed for actors that discover their own paths.
The workload model can’t support this because it was designed to enumerate. The human model is oriented toward it because humans were the first actors that needed to operate in open, unbounded problem spaces with delegated authority and loosely defined scope.
The Human Identity Stack Got Here First
The human identity stack evolved these properties because humans needed them. Delegation exists because users interact with arbitrary services and need to grant scoped authority. Federation exists because trust crosses organizational boundaries. Consent flows exist because sometimes a human needs to approve what’s happening. Progressive auth exists because different operations require different levels of assurance, though in practice it’s barely deployed because it’s hard to implement well.
That last point matters. Progressive auth has been a nice-to-have for human identity, something most organizations skip because the friction isn’t worth it for human users who can just re-authenticate. For agents, it becomes essential. The more emergent the expectations, the more you need the ability to step up trust dynamically. Agents make progressive auth a requirement, not an aspiration.
And unlike the human case, progressive auth for agents is more tractable to build. The agent proposes an action, a policy engine or human approves, the scope expands with full audit. The governance gates can be automated. The building blocks exist. The composition is the work.
The human stack built these primitives because humans operate in open, dynamic ecosystems. Workloads historically didn’t. Now agents do. And agents are going to force the deployment of progressive auth patterns that the human stack defined but never fully delivered on.
And you can see this playing out in real time. Every serious attempt to solve agent identity reaches for human identity concepts, not workload identity concepts. Dick Hardt built AAuth around delegation, consent, progressive trust, and token exchange. Not because those are OAuth features, but because those are the properties agents need, and the human identity stack is where they were first defined. Microsoft’s Entra Agent ID uses On-Behalf-Of flows, confidential clients, and delegation patterns. Google’s A2A protocol uses OAuth, task-based delegation, and agent cards for discovery.
You can stretch SPIFFE or WIMSE to cover simple agent automation. But once agents operate across discovered systems rather than pre-enumerated ones, the model starts to strain. That’s not because those are bad technologies. It’s because they solve a different layer. Agent auth lives above attestation, in the governance layer, and the concepts that keep showing up there, delegation, consent, session scope, progressive trust, all originate on the human side.
That’s not a coincidence. The people building the protocols are voting with their architecture, and they’re voting for the human side. They’re doing it because that’s where the right primitives already exist.
“Why Not Just Extend Workload Identity?”
The obvious counterargument is that you could start from workload identity and extend it to cover agents. It’s worth taking seriously.
SPIFFE is good technology and it works well where it fits. Cloud-native environments, Kubernetes clusters, modern service meshes. In those environments, SPIFFE’s model of dynamic attestation and identity issuance is exactly right. The problem isn’t SPIFFE. The problem is that you don’t get to change all the systems.
That’s why WIMSE exists. Not because SPIFFE failed, but because the real world has more environments than SPIFFE was designed for. Legacy systems, hybrid deployments, multi-cloud sprawl, enterprise environments that aren’t going to rearchitect around SPIFFE’s model. WIMSE is defining the broader patterns and extending the schemes to fit those other environments. That work is important and it’s still in progress.
There’s also a growing push to treat agents as non-human identities and extend workload identity with agent-specific attributes. Ephemeral provisioning, delegation chains, behavioral monitoring. The idea is that agents are just advanced NHIs, so you start from the workload stack and bolt on what’s missing. I understand the appeal. It lets you build on existing infrastructure without rethinking the model.
But what you end up bolting on is delegation, consent, session scope, and progressive trust. Those aren’t workload identity concepts being extended. Those are human identity concepts being retrofitted onto a foundation that was never designed for them. You’re starting from attestation and trying to work your way up to governance. Every concept you need to add comes from the other stack. At some point you have to ask whether you’re extending workload identity or just rebuilding human identity with extra steps.
Agent Identity Is a Governance Problem
Now apply that same logic to agents more broadly. Agents don’t operate in a world where every system speaks SPIFFE, or WIMSE, or any single workload identity protocol. They interact with whatever is out there. SaaS APIs. Legacy enterprise systems. Third-party services they discover at runtime. The environments agents operate in are even more heterogeneous than the environments WIMSE is trying to address.
And many of those systems don’t support delegation at all. They authenticate users with passwords and passkeys, and that’s it. No OBO flows, no token exchange, no scoped delegation. In those cases agents will need to fully impersonate users, authenticating with the user’s credentials as if they were the user. That’s not the ideal architecture. It’s the practical reality of a world where agents need to interact with systems that were built for humans and haven’t been updated. The identity infrastructure has to treat impersonation as a governed, auditable, revocable act rather than pretending it won’t happen.
I want to be honest about the contradiction here. The moment an agent injects Alice’s password into a legacy SaaS app, all of the governance properties this post argues for vanish. Principal-level accountability, cryptographic provenance, session-scoped delegation — none of it survives that boundary. The legacy system sees Alice. The audit log says Alice. There’s no way to distinguish Alice from an agent acting on Alice’s behalf. You can’t revoke the agent’s access without changing Alice’s password. I don’t have a good answer for that. It’s a real gap, and it will exist for as long as legacy systems do. The faster the world moves toward agent-native endpoints, the smaller this governance black hole gets. But right now it’s large.
At the same time, the world is moving toward agent-native endpoints. I’ve written before about a future where DNS SRV records sit right next to A records, one pointing at the website for humans and one pointing at an MCP endpoint for agents. That’s the direction. But identity infrastructure has to handle the full spectrum, from legacy systems that only understand passwords to native agent endpoints that support delegation and attestation natively. The spectrum will exist for a long time.
More than with humans or workloads, agent identity turns into a governance problem. Human identity is mostly about authentication. Workload identity is mostly about attestation. Agent identity is mostly about governance. Who authorized this agent. What scope was it given. Is that scope still valid. Should a human approve the next step. Can the delegation be revoked right now. Those are all governance questions, and they matter more for agents than they ever did for humans or workloads because agents act autonomously under delegated authority across systems nobody fully controls.
And unlike humans, agents possess neither liability nor common sense. A human with overly broad access still has judgment that says “this is technically allowed but clearly a bad idea” and faces personal consequences for getting it wrong. Agents have neither brake. The governance infrastructure has to provide externally what humans provide partially on their own.
For humans and workloads, identity and authorization are cleanly separable layers. For agents, they converge. An agent’s identity without its delegation context is meaningless, and its delegation context is authorization. Governance is where those two layers collapse into one.
The reason is structural. Workloads act on behalf of the organization that deployed them. The operator and the principal are the same entity. Agents introduce a new actor in the chain. They act on behalf of a specific human who delegated specific authority for a specific task. That “on behalf of” is simultaneously an identity fact and an authorization fact, and it doesn’t exist in the workload model at all.
That’s why the human identity stack keeps winning this argument.
Meanwhile, human identity concepts are deployed at planetary scale. Delegation and consent are mature, well-understood patterns with decades of deployment experience. Progressive trust is defined but barely deployed. Multi-hop delegation provenance is still being figured out. It’s an incomplete picture, but here’s the thing: the properties that are missing from the human side don’t even have definitions on the workload side. That’s still a decisive advantage.
But I want to be clear. The argument here is about properties, not protocols. I don’t think OAuth is the answer, even with DPoP. OAuth was designed for a world of pre-registered clients and tightly scoped API access. DPoP bolts on proof-of-possession, but it doesn’t change the fundamental model.
When Hardt built AAuth, he didn’t extend OAuth. He started a new protocol. He kept the concepts that work (delegation, consent, token exchange, progressive trust) and rebuilt the mechanics around agent-native patterns. HTTPS-based identity without pre-registration, HTTP message signing on every request, ephemeral keys, and multi-hop token exchange. That’s telling. The human identity stack has the right concepts, but the actual protocols need to be rebuilt for agents. The direction is human-side. The destination is something new.
This isn’t about which stack is theoretically better. It’s about which stack has the right primitives deployed in the environments agents actually operate in. The answer to that question is the human identity stack.
Discretion Makes It Harder, But It’s Not the Main Event
The behavioral stuff still matters. It’s just downstream of the structural argument.
Workloads execute predefined logic. You attest that the right code is running in the right environment, and from there you can reason about what it will do. Agents don’t work that way. When you give an autonomous AI agent access to your infrastructure with the goal of “improve system performance,” you can’t predict whether it will optimize efficiency or find creative shortcuts that break other systems. We’ve already seen models break out of containers by exploiting vulnerabilities rather than completing tasks as intended. Agents optimize objectives in ways that can violate intent unless constrained. That’s not a bug. It’s the expected behavior of systems designed to find novel paths to goals.
That means you can’t rely on code measurement alone to govern what an agent does. You also need behavioral monitoring, anomaly detection, conditional privilege, and the ability to put a human in the loop. Those are all human IAM patterns. But you need them because the ecosystem is open and the behavior is unpredictable. The open ecosystem is the first-order problem. The unpredictable behavior makes it worse.
And this is where the distinction between guidance and enforcement matters. System instructions are suggestions. An agent can be told “don’t access production data” in its prompt and still do it if a tool call is available and the reasoning chain leads there. Prompt injections can override instructions entirely. Policy enforcement is infrastructure. Cryptographic controls, governance layers, and authorization gates that sit outside the agent’s context and can’t be talked around. Agents need infrastructure they can’t override through reasoning, not instructions they’re supposed to follow.
What Agents Actually Need From the Human Stack
Session-scoped authority. I’ve written about this with the Tron identity disc metaphor. Agent spawns, gets a fresh disc, performs a mission, disc expires. That’s session semantics. It exists because the trust relationship is bounded and temporary, the way a user’s interaction with a service is bounded and temporary, not the way a workload’s persistent role in a service mesh works.
Think about what happens without it. An agent gets database write access for a migration task. Task completes. The credentials are still live. The next task is unrelated, but the agent still has write access to that database. A poisoned input, a bad reasoning chain, or just an optimization shortcut the agent thought was clever, and it drops a table. Not because it was malicious. Because it had credentials it no longer needed for a task it was no longer doing. That’s the agent equivalent of Bobby Tables, and it’s entirely preventable.
The logical endpoint of session-scoped authority is zero standing permissions. Every agent session starts empty. No credentials carry over from the last task. The agent accumulates only what it needs for this specific mission, and everything resets when the mission ends.
For humans, zero standing permissions is aspirational but rarely practiced because the friction isn’t worth it. Humans don’t want to re-request access to the same systems every morning. Agents don’t have that problem. They can request, wait, and proceed programmatically. The friction that makes zero standing permissions impractical for humans disappears for agents.
The hard question is how permissions get granted at runtime. Predefined policy handles the predictable paths. Billing agent gets billing APIs. That works, but it’s enumeration, and enumeration breaks down for open-ended tasks. Human-gated expansion handles the unpredictable paths, but it kills autonomy.
The mechanism that would actually make zero standing permissions work for emergent behavior is goal-scoped evaluation. Does this request serve the stated goal within the stated boundaries. That’s the same unsolved problem the rest of this piece keeps circling. Zero standing permissions is the right ideal. It’s achievable today for the predictable portion of agent work. The gap is the same gap.
Delegation with provenance. Agents are user agents in the truest sense. They carry delegated user authority into digital systems. AAuth formalizes this with agent tokens that bind signing keys to identity. The question “who authorized this agent to do this?” is a delegation question. Delegation is a human identity primitive because humans were the first actors that operated across trust boundaries and needed to grant scoped authority to others.
Chaining that delegation cryptographically across multi-hop paths, from user to agent to tool to downstream service while maintaining proof of the original user’s intent, is genuinely hard. Standard OBO flows are often too brittle for this. This is where the industry needs to go, not where it is today.
Progressive trust. AAuth lets a resource demand anything from a signed request to verified agent identity to full user authorization. That gradient only makes sense when the trust relationship is negotiated dynamically. Workloads don’t negotiate trust. They either have a role or they don’t.
Accountability at the principal level. When an agent approves a transaction, files a regulatory report, or alters infrastructure state, the audit question is “who authorized this and was it within scope?” Today’s logs can’t answer that. The log says an API token performed a read on a customer record. That token is shared across dozens of agents. Which agent? Acting on whose delegation? For what task? The log can’t say.
And even if it could identify the agent, there’s nothing connecting that action to the human authorization that allowed it. Nobody asks “which Kubernetes pod approved this wire transfer.” Governance frameworks reason about actors. That’s why every protocol effort maps agent identity to principal identity.
Goal-scoped authorization. Agents need mixed constraints rather than pure positive enumeration. Define the scope, set the boundaries, establish the escalation paths, delegate the goal, let the agent figure out the path. That’s how we’ve governed human actors in organizations for centuries. The identity and authorization infrastructure to support it exists in the human stack because that’s where it was needed first.
But I’ll be direct. Goal-scoped authorization is the hardest unsolved engineering problem in this space. The fundamental tension is temporal. Authorization happens before execution, but agents discover what they need during execution. Current authorization systems operate on verbs and nouns (allow this action on this resource). They don’t understand goals. Translating “fix the billing error” into a set of allowed API calls at runtime, without the agent hallucinating its way into a catastrophe, requires a just-in-time policy layer that doesn’t exist yet.
Progressive trust gets us part of the way there. The agent proposes an action, a policy engine, or a human approves the specific derived action before it executes. But the full solution is ahead of us, not behind us.
I know how this sounds to security people. “Goal-based authorization” sounds like the agent decides what it needs based on its own interpretation of a goal. That’s terrifying. It sounds like self-authorizing AI. But the alternative is pretending we can enumerate every action an agent might need in advance, and that fails silently. Either the agent operates within the pre-authorized list and can’t do its job, or someone over-provisions “just in case” and the agent has access to things it shouldn’t. Both are security failures. One just looks tidy on paper. Goal-based auth at least makes the governance visible. The agent proposes, the policy evaluates, the decision is logged. The scary part isn’t that we need goal-based auth. The scary part is that we don’t have it yet, so people are shipping agents with over-provisioned static credentials instead.
And there’s a deeper problem I want to name honestly. The only thing capable of evaluating whether a specific API call serves a broader goal is another LLM. And that means putting a probabilistic, hallucination-prone, high-latency system into the critical path of every infrastructure request. You’re using the thing you’re trying to govern as the governance mechanism. That’s not just an engineering gap waiting to be filled. It’s a fundamental architectural tension that the industry hasn’t figured out how to resolve. Progressive trust with human-gated escalation is the best interim answer, but it’s a workaround, not a solution.
This Isn’t About Throwing Away Attestation
I want to be clear about something because readers will assume otherwise. This argument is not “throw away workload identity primitives.” I’ve spent years arguing that attestation is MFA for workloads. I’ve written about measured enclaves, runtime attestation, and hardware-rooted identity extensively. None of that goes away.
You absolutely need attestation to prove the agent is running the right code in the right environment. You need runtime measurement to detect tampering. You need hardware roots of trust. If a hacker injects malicious code into an agent that has broad delegated authority, you need to know. That’s the workload identity stack doing its job.
In fact, attestation isn’t just complementary to the governance layer. It’s prerequisite. You can’t safely delegate authority to something you can’t verify. All the governance, delegation, and consent primitives in the world are meaningless if the code executing them has been tampered with. Attestation is the foundation the governance layer stands on.
But attestation alone isn’t enough. Proving that the right code is running doesn’t tell you who authorized this agent to act, what scope it was delegated, whether it’s operating within that scope, or whether a human needs to approve the next action. Those are delegation, consent, and governance questions. Those live in the human identity stack.
What agents actually need is both. Workload-style attestation as the foundation, with human-style delegation, consent, and progressive trust built on top.
I’ve argued before that attestation is MFA for workloads. It proves code integrity, runtime environment, and platform state, the way MFA proves presence, possession, and freshness for humans. For agents, we need to extend that into principal-level attestation. Not just “is this the right code in the right environment?” but also “who delegated authority to this agent, under what policy, with what scope, and is that delegation still valid?”
That’s multi-factor attestation of an acting principal. Code integrity from the workload stack, delegation provenance from the human stack, policy snapshot and session scope binding the two together. Neither stack delivers that alone today.
The argument is about where the center of gravity is, not about discarding one stack entirely. And the center of gravity is on the human side, because the hard problems for agents are delegation and governance, not runtime measurement.
Where the Properties Actually Align (And Where They Don’t)
I’ve been arguing agents are more like humans than workloads. That’s true as a center-of-gravity claim. But it’s not total alignment, and pretending otherwise invites the wrong criticisms. Here’s where the properties actually land.
What agents inherit from the human side:
Delegation with scoped authority. Session-bounded trust. Progressive auth and step-up. Cross-boundary trust negotiation. Principal-level accountability. Open ecosystem discovery. These are the properties that make agents look like humans and not like workloads. They’re also the properties that are hardest to solve and least mature.
What agents inherit from the workload side:
Code integrity attestation. Runtime measurement. Programmatic credential handling with no human in the authentication loop. Ephemeral identity that doesn’t persist across sessions. These are well-understood, and the workload identity stack handles them. Agents don’t authenticate the way humans do. They don’t type passwords or touch biometric sensors. They prove what code is running and in what environment. That’s attestation, and it stays on the workload side.
What neither stack gives them:
This is the part nobody is talking about enough. Agents have properties that don’t map cleanly to either the human or workload model.
Accumulative trust within a task that resets between tasks. Human trust accumulates over a career and persists. Workload trust is static and role-bound. Agent trust needs to build during a mission as the agent demonstrates relevance and competence, then reset completely when the mission ends. Nothing in either stack supports that lifecycle.
Goal-scoped authorization with emergent resource discovery. I’ve already called this the hardest unsolved problem. Current auth systems operate on verbs and nouns. Agents need auth systems that operate on goals and boundaries. Neither stack was designed for this.
Delegation where the delegate doesn’t share the delegator’s intent. Every existing delegation protocol assumes the delegate understands and shares the user’s intent. When a human delegates to another human through OAuth, both parties generally understand what “handle my calendar” means and what it doesn’t.
An agent doesn’t share intent. It shares instructions. It will pursue the letter of the delegation through whatever path optimizes the objective, even if the human would have stopped and said “that’s not what I meant.” This isn’t a philosophy problem. It’s a protocol-level assumption violation. No existing delegation framework accounts for delegates that optimize rather than interpret.
Simultaneous proof of code identity and delegation authority. Agents need to prove both what they are (attestation) and who authorized them to act (delegation) in a single transaction. Those proofs come from different stacks with different trust roots. A system can check both sequentially, verify the attestation, then verify the delegation, and that’s buildable today. But binding them together cryptographically into a single verifiable object so a relying party can verify both at once without trusting the binding layer is an unsolved composition problem.
Vulnerability to context poisoning that persists across sessions. I’ve written about the “Invitation Is All You Need” attack where a poisoned calendar entry injected instructions into an agent’s memory that executed days later. Humans can be socially engineered, but they don’t carry the payload across sessions the way agents do. Workloads don’t accumulate context at all. Agent session isolation is a new problem that needs new primitives.
The honest summary is this. Agents inherit their governance properties from the human side and their verification properties from the workload side, but neither stack addresses the properties that are unique to agents. The solution isn’t OAuth with attestation bolted on. It’s something new that inherits from both lineages and adds primitives for accumulative task-scoped trust, goal-based authorization, and session isolation. That thing doesn’t exist yet.
Where This Framing Breaks
Saying “agents are like humans” implies the workload stack fails because workloads lack something agents have. Discretion, autonomy, behavioral complexity. That’s the wrong diagnosis. The workload stack fails because it was built for a world of pre-registered clients, tightly bound server relationships, and closed trust ecosystems. The more capable agents become, the less they stay in that world.
The human identity stack fits better not because agents are human-like, but because it’s oriented toward the structural properties agents need. Open ecosystems. Dynamic trust negotiation. Delegation across boundaries. Session-scoped authority. Progressive assurance. Not all of these are fully deployed today. Some are defined but immature. Some don’t exist as protocols yet. But the concepts, the vocabulary, and the architectural direction all come from the human side. The workload side doesn’t even have the vocabulary for most of them.
Those properties exist in the human stack because humans needed them first. Now agents need them too.
The Convergence We’ve Already Seen
My blog has traced this progression for a while now. Machines were static, long-lived, pre-registered. Workloads broke that model with ephemeral, dynamic, attestation-based identity. Each step in that evolution adopted identity properties that were already standard in human identity systems. Dynamic issuance. Short credential lifetimes. Context-aware access. Attestation as MFA for workloads. Workload identity got better by becoming more like user identity.
Agents are the next step in that same convergence. They don’t just need dynamic credentials and attestation. They need delegation, consent, progressive trust, session scope, and goal-based authorization. The most complete and most deployed versions of those primitives live in the human stack. Some exist in other forms elsewhere (SPIFFE has trust domain federation, capability tokens like Macaroons exist independently), but the human stack is where the broadest set of these concepts has been defined, tested, and deployed at scale.
The Actual Claim
Agent identity is a governance problem. Not an authentication problem, not an attestation problem. The hard questions are all governance questions. Who delegated authority. What scope. Is it still valid. Should a human approve the next step. For humans and workloads, identity and authorization are separate layers. For agents, they collapse. The delegation is the identity.
The human identity stack is where principal identity primitives live. Not because agents are people, but because people were the first actors that needed identity in open ecosystems with delegated authority and unbounded problem spaces.
Every protocol designer who sits down to solve agent auth rediscovers this and reaches for human identity concepts, not workload identity concepts. The protocols they build aren’t OAuth. They’re something new. But they inherit from the human side every time. That convergence is the argument.
The delegation and governance layer is buildable today. Goal-scoped authorization and intent verification are ahead of us. The first generation of agent identity systems will solve governance. The second will solve intent.
There’s a pattern that plays out across every regulated industry. Requirements increase. Complexity compounds. The people responsible for compliance realize they can’t keep up with manual processes. So instead of building the capacity to meet the rising bar, they quietly lower the specificity of their commitments.
It’s rational behavior. A policy that says “we perform regular reviews” can’t be contradicted the way a policy that says “we perform reviews every 72 hours” can. The less you commit to on paper, the less exposure you carry.
The problem is that this rational behavior, repeated across enough organizations and enough audit cycles, hollows out the entire compliance system from the inside. Documents stop describing what organizations actually do. They start describing the minimum an auditor will accept. The gap between documentation and reality widens. Nobody notices until something breaks.
Amazon Trust Services disclosed that their Certificate Revocation Lists sometimes backdate a timestamp called “thisUpdate” by up to a few hours. The practice itself is defensible. It accommodates clock skew in client systems. When they updated their policy document to disclose the behavior, they described it as CRLs “may be backdated by up to a few hours.”
A community member pointed out the obvious. “A few hours” is un-auditable. Without a defined upper bound, there’s no way for an auditor, a monitoring tool, or a relying party to evaluate whether any given CRL falls within the CA’s stated practice. Twelve hours? Still “a few.” Twenty-four? Who decides?
When pressed, Amazon’s response was telling. They don’t plan to add detailed certificate profiles back into their policy documents. They believe referencing external requirements satisfies their disclosure obligations. We’ll tell you we follow the rules, but we won’t tell you how.
Apple, Mozilla, and Google’s Chrome team then independently pushed back. Each stated that referencing external standards is necessary but not sufficient. Policy documents must describe actual implementation choices with enough precision to be verifiable.
Apple’s Dustin Hollenback was direct. “The Apple Root Program expects policy documents to describe the CA Owner’s specific implementation of applicable requirements and operational practices, not merely incorporate them by reference.”
Mozilla’s Ben Wilson went further, noting that “subjective descriptors without defined bounds or technical context make it difficult to evaluate compliance, support audit testing, or enable independent analysis.” Mozilla has since opened Issue #295 to strengthen the MRSP accordingly.
Chrome’s response summarized the situation most clearly:
We consider reducing a CP/CPS to a generic pointer where it becomes impossible to distinguish between CAs that maintain robust, risk-averse practices and those that merely operate at the edge of compliance as being harmful to the reliable security of Chrome’s users.
They also noted that prior versions of Amazon’s policy had considerably more profile detail, calling the trend of stripping operational commitments “a regression in ecosystem transparency.”
The Pattern Underneath
What makes PKI useful as a case study isn’t that certificate authorities are uniquely bad at this. It’s that their compliance process is uniquely visible. CP/CPS documents are public. Incident reports are filed in public Bugzilla threads. Root program responses are posted where anyone can read them. The entire negotiation between “what we do” and “what we’re willing to commit to on paper” plays out in the open.
In most regulated industries, you never see this. The equivalent conversations in finance, FedRAMP, healthcare, or energy happen behind closed doors between compliance staff and auditors. The dilution is invisible to everyone outside the room. A bank’s internal policies get vaguer over time and nobody outside the compliance team and their auditors knows it happened. A FedRAMP authorization package gets thinner and the only people who notice are the assessors reviewing it. The dynamic is the same. The transparency isn’t.
So when you watch a CA update its policy with “a few hours” and three oversight bodies publicly push back, you’re seeing something that happens constantly across every regulated domain. You’re just not usually allowed to watch.
Strip away the PKI details and the pattern is familiar to anyone who has worked in compliance. An organization starts with detailed documentation of its practices. Requirements grow. Maintaining alignment between what the documents say and what the systems actually do gets expensive. Someone realizes that vague language creates less exposure than specific language. Sometimes it’s the compliance team running out of capacity. Sometimes it’s legal counsel actively advising against specific commitments, believing that “reasonable efforts” is harder to litigate against than “24 hours.” Either way, they’re trading audit risk for liability risk and increasing both. The documents get trimmed. Profiles get removed. Temporal commitments become subjective. “Regularly.” “Promptly.” “Periodically.” Operational descriptions become references to external standards.
Each individual edit is defensible. Taken together, they produce a document that can’t be meaningfully audited because there’s nothing concrete to audit against. One community member in the Amazon thread called this “Compliance by Ambiguity,” the practice of using generic, non-technical language to avoid committing to specific operational parameters. It’s a perfect label for a pattern that shows up everywhere.
This is the compliance version of Goodhart’s Law. When organizations optimize their policy documents for audit survival rather than operational transparency, the documents stop serving any of their original functions. Auditors can’t verify practices against vague commitments. Internal teams can’t use the documents to understand what’s expected of them. Regulators can’t evaluate whether the stated approach actually manages risk. The document becomes theater. And audits are already structurally limited by point-in-time sampling, auditee-selected scope, and the inherent conflict of the auditor working for the entity being audited. Layering ambiguous commitments on top of those limitations removes whatever verification power the process had left.
And it’s accelerating. Financial services firms deal with overlapping requirements from dozens of jurisdictions. Healthcare organizations juggle HIPAA, state privacy laws, and emerging AI governance frameworks simultaneously. Even relatively narrow domains like certificate authority operations have seen requirement growth compound year over year as ballot measures, policy updates, and regional regulations stack on top of each other. The manual approach to compliance documentation was already strained a decade ago. Today it’s breaking.
In PKI alone, governance obligations have grown 52-fold since 2005. The pattern is similar in every regulated domain that has added frameworks faster than it has added capacity to manage them.
Most organizations choose dilution. Not because they’re negligent, but because the alternative barely exists yet. There is no tooling deployed at scale that continuously compares what a policy document says against what the infrastructure actually does. No system that flags when a regulatory update creates a gap between stated practice and new requirements. No automated way to verify that temporal commitments (“within 24 hours,” “no more than 72 hours”) match operational reality. So people do what people do when workload exceeds capacity. They cut corners on the parts that seem least likely to matter this quarter. Policy precision feels like a luxury when you’re scrambling to meet the requirements themselves.
What Vagueness Actually Costs
The short-term calculus makes sense. The long-term cost doesn’t.
I went back and looked at public incidents in the Mozilla CA Program going back to 2018. Across roughly 500 cases, about 70% fall into process and operational failures rather than code-level defects. A large portion trace back to gaps between what an organization actually does and what its documents say it does. The organizations that ultimately lost trust follow a consistent pattern. Documents vague enough to avoid direct contradiction, but too vague to demonstrate that operations stayed within defined parameters. The decay is always gradual. The loss of trust always looks sudden.
The breakdown is telling. Of the four major incident categories, Governance & Compliance failures account for roughly half of all incidents, more than certificate misissuance, revocation failures, and validation errors combined. The primary cause isn’t code bugs or cryptographic weaknesses. It’s administrative oversight. Late audit reports, incomplete analysis, delayed reporting. The stuff that lives in policy documents and process descriptions, not in code.
The distribution looks like this:
This holds outside PKI. The financial institutions that get into the worst trouble with regulators aren’t usually the ones doing something explicitly prohibited. They’re the ones whose internal documentation was too vague to prove they were doing what they claimed. Read the details behind SOX failures, GDPR enforcement actions, and FDA warning letters, and you’ll find the same structural problem. Stated practices didn’t match reality, and nobody caught it because the stated practices were too imprecise to evaluate.
Vagueness also creates operational risk that has nothing to do with regulators. When your own engineering, compliance, and legal teams can’t look at a policy document and know exactly what’s expected, they fill in the gaps with assumptions. Different teams make different assumptions. Practices diverge. The organization thinks it’s operating one way because that’s what the document sort of implies. The reality is something else. And the gap only surfaces when an auditor, a regulator, or an incident forces someone to look closely.
The deeper issue is that vagueness removes auditability as a control surface. When commitments are measurable, deviations surface automatically. A system can check whether a CRL was backdated by more than two hours the same way it checks whether a certificate was issued with the wrong key usage extension. The commitment is binary. It either holds or it doesn’t. When commitments are subjective, deviations become interpretive. “A few hours” can’t be checked by a machine. It can only be argued about by people. That shifts risk detection from systems to negotiation. Negotiation doesn’t scale, produces inconsistent outcomes, and worst of all, it only happens between the auditee and the auditor. The regulators and the public who actually bear the risk aren’t in the room.
That spectrum is the diagnostic. Everything to the right of “machine-checkable” is a gap waiting to be exploited by time pressure, turnover, or organizational drift.
What Would Have to Change
Solving this means treating compliance documentation as infrastructure rather than paperwork. In the same way organizations moved from manual deployments to CI/CD pipelines, compliance needs to move from static documents reviewed annually to living systems verified continuously.
The instinct is to throw AI at it, and that instinct is half right. LLMs are good at ingesting unstructured policy documents. But compliance verification isn’t a search problem. It’s a systematic reasoning problem. You need to trace requirements through hierarchies, exceptions, and precedence rules, then compare them against operational evidence. Recent research shows that RAG-based approaches still hallucinate 17-33% of the time on legal and compliance questions, even with domain-specific retrieval. The failure mode isn’t bad prompting. It’s architectural. You cannot train a model to strictly verify “a few hours” any better than you can train an auditor.
The fix isn’t better retrieval. It’s decomposing complex compliance questions into bounded sub-queries against explicit structures that encode regulatory hierarchy and organizational context, keeping the LLM’s role narrow enough that its errors can be isolated and reviewed.
That means tooling that ingests policy documents and maps commitments to regulatory requirements. Systems that flag language failing basic auditability checks, like temporal bounds described with subjective terms instead of defined thresholds. Automated comparison of stated practices against actual system behavior, running continuously rather than at audit time.
In the Amazon case, a system like this would have caught “a few hours” before it was published. Not because backdating is prohibited, but because the description lacks the specificity needed for anyone to verify compliance with it. The system wouldn’t need to understand CRL semantics. It would just need to know that temporal bounds in operational descriptions require defined, measurable thresholds to be auditable.
Scale that across any compliance domain. Every vague commitment is a gap. Every gap is a place where practice can diverge from documentation without detection. Every undetected divergence is risk accumulating quietly until something forces it into the open.
The Amazon incident is useful because it forced the people who oversee trust decisions to say out loud what has been implicit for years. The bar for documentation specificity is rising, and organizations that optimize for minimal disclosure are optimizing for the wrong thing. That message goes well beyond certificate authorities. The ones that keep diluting their commitments will discover that vagueness isn’t a shield. It’s a slow-moving liability that compounds until it becomes an acute one.
The regulatory environment isn’t going to get simpler. The organizations that treat policy precision as optional will discover that ambiguity scales faster than governance, and that systems which cannot be automatically verified will eventually be manually challenged.