There is a class of problems in information security that are intractable. This is often because they have conflicting non-negotiable requirements.
A good example of this is what I like to call the “re-entry” problem. For instance, let’s say you operated a source control service, let’s call it “SourceHub”. To increase adoption you need “SourceHub” to be quick and easy for anyone to join and get up and running.
But some users are malicious and will do nefarious things with “SourceHub” which means that you may need to kick them off and keep them off of your service in a durable way.
These two requirements are in direct conflict, the first essentially requires anonymous self-service registration and the second requires strong, unique identification.
The requirement of strong unique identification might seem straightforward on the surface but that is far from the case. For example, in my small social circle, there are four “Natallia’s” who are often are at the same gatherings, everyone must qualify which one we are talking to at these events. I also used to own ryanhurst.com but gave it up because of the volume of spam I would get from fans of Ryan Hurst the actor because spam filters would fail to categorize this unique mail as spam due to the nature of its origin.
Some might say this problem gets easier when dealing with businesses but unfortunately, that is not the case. Take for example the concept of legal identity in HTTPS certificates — we know that business names are not globally unique, they are not even unique within a country which often makes the use of these business names as an identifier useless.
We also know that the financial burden to establish a “legal business” is very low. For example in Kentucky, it costs $40 to open a business. The other argument I often hear is that despite the low cost of establishing the business the time involved is just too much for an attacker to consider. The problem with this argument is the registration form takes minutes to fill out and if you toss in an extra $40 the turnaround time goes from under 3 weeks to under 2 days — not exactly a big delay when looking at financially incentified attackers.
To put this barrier in the context of a real-world problem let’s look at Authenticode signing certificates. A basic organizationally validated Authenticode code signing certificate costs around $59, With this certificate and that business registration, you can get whatever business name and application name you want to show in the install prompt in Windows.
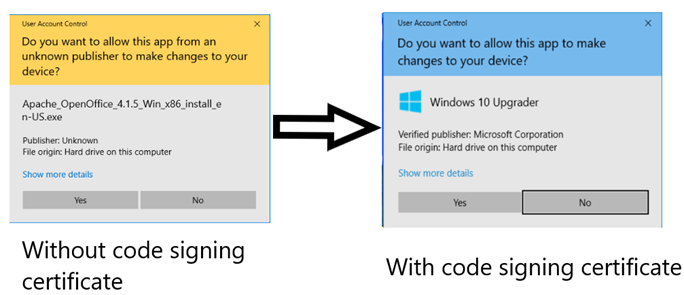
This sets the bar to re-enter this ecosystem once evicted to around $140 dollars and a few days of waiting.
But what about Authenticode EV code signing? By using an EV code signing certificate you get to start with some Microsoft Smart Screen reputation from the get-go – this certainly helps grease the skids for getting your application installed so users don’t need to see a warning.
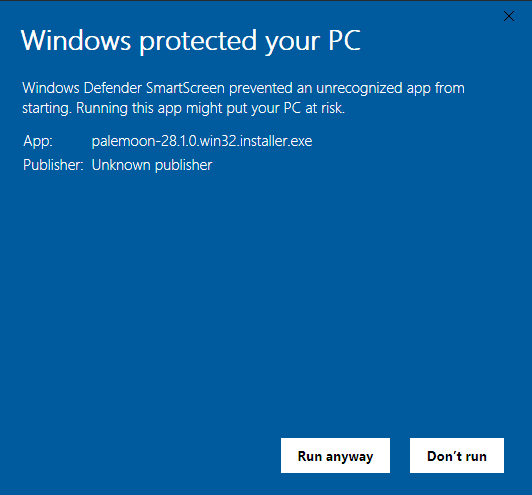
But does this reduce the re-entry problem further? Well, the cost for an EV code signing certificate is around $219 which does take the financial burden for the attacker to about $300. That is true at least for the first time – about $50 of that first tome price goes to a smart card like the SafeNet 5110cc or Yubikey 5. Since the same smart card can be used for multiple certificates that cost goes down to $250 per re-entry. It is fair to say the complication of using a smart card for key management also slows the time it takes to get the first certificate, this gets the timeline from incorporation to having an EV code signing certificate in hand to about 1.5 weeks.
These things do represent a re-entry hurdle, but when you consider that effective Zero Day vulnerabilities can net millions of dollars I would argue not a meaningful one. Especially when you consider the attacker is not going to use their own money anyway.
You can also argue that it offers some rate-limiting value to the acquisition pipeline but since there are so many CAs capable of issuing these certificates you could register many companies, somewhat like Special Purpose Acquisition Companies (SPAC) in the stock market, so that when the right opportunity exists to use these certificates it’s ready and waiting.
This hurdle also comes at the expense of adoption of code signing. This of course begs the question of was all that hassle was worth it?
Usually the argument made here is that since the company registration took place we can at least find the attacker at a later date right? Actually no, very few (if any) of these company registrations verify the address of the applicant.
As I stated, in the beginning, this problem isn’t specific to code signing but in systems like code signing where the use of the credential has been separated from the associated usage of the credential, it becomes much harder to manage this risk.
To keep this code signing example going let’s look at the Apple Store. They do code-signing and use certificates that are quite similar to EV code-signing certificates. What is different is that Apple handles the entire flow of entity verification, binary analysis, manual review of the submission, key management, and signing. They do all of these things while taking into consideration the relationship of each entity and by considering the entire history available to them. This approach gives them a lot more information than you would have if you did each of these things in isolation from each other.
While there are no silver bullets when it comes to problems like this getting the abstractions at the right level does give you a lot more to work with when trying to defend from these attacks.

