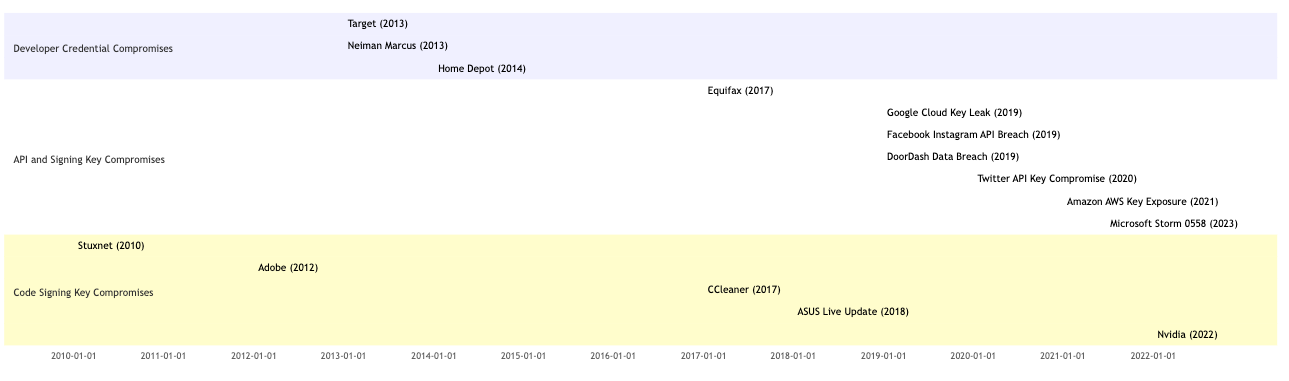
Incident response is notoriously challenging, and with the rise in public reporting obligations, the stakes have never been higher. In the WebPKI world, mishandling incidents can severely damage a company’s reputation and revenue, and sometimes even end a business. The Cyber Incident Reporting for Critical Infrastructure Act of 2022 has intensified this pressure, requiring some companies to report significant breaches to CISA within 72 hours. This isn’t just about meeting deadlines. The stakes are high, and the pressure is on. Look at the recent actions of the Cyber Safety Review Board (CSRB), which investigates major cyber incidents much like how plane crashes are scrutinized. The recent case of Entrust’s cascade of incidents in the WebPKI ecosystem, and the scrutiny they have gone under as a result, shows how critical it is to respond professionally, humbly, swiftly, and transparently. The takeaway? If you don’t respond adequately to an incident, someone else might do it for you, and even if not, mishandling can result in things spiraling out of control.
The Complexity of Public Reporting
Public reports attract attention from all sides—customers, investors, regulators, the media, and more. This means your incident response team must be thorough and meticulous, leaving no stone unturned. Balancing transparency with protecting your organization’s image is critical. A well-managed incident can build trust, while a poorly handled one can cause long-term damage.
Public disclosures also potentially come with legal ramifications. Everything must be vetted to ensure compliance and mitigate potential liabilities. With tight timelines like the CISA 72-hour reporting requirement, there’s little room for error. Gathering and verifying information quickly is challenging, especially when the situation is still unfolding. Moreover, public reporting requires seamless coordination between IT, legal, PR, and executive teams. Miscommunication can lead to inconsistencies and errors in the public narrative.
The Role of Blameless Post Mortems
Blameless post-mortems are invaluable. When there’s no fear of blame, team members are more likely to share all relevant details, leading to a clearer understanding of the incident. These post-mortems focus on systemic issues rather than pointing fingers, which helps prevent similar problems in the future. By fostering a learning culture, teams can improve continuously without worrying about punitive actions.
It’s essential to identify the root causes of incidents and ensure they are fixed durably across the entire system. When the same issues happen repeatedly, it indicates that the true root causes were not addressed. Implementing automation and tooling wherever possible is crucial so that you always have the information needed to respond quickly. Incidents that close quickly have minimal impact, whereas those that linger can severely damage a business.
Knowing they won’t be blamed, team members can contribute more calmly and effectively, improving the quality of the response. This approach also encourages thorough documentation, creating valuable resources for future incidents.
Evolving Public Reporting Obligations
New regulations demand greater transparency and accountability, pushing organizations to improve their security practices. With detailed and timely information, organizations can better assess and manage their risks. The added legal and regulatory pressure leads to faster and more comprehensive responses, reducing the time vulnerabilities are left unaddressed. However, these strict timelines and detailed disclosures increase stress on incident response teams, necessitating better support and processes. Additionally, when there are systemic failures in an organization, one incident can lead to others, overwhelming stakeholders and making it challenging to prioritize critical issues.
Importance of a Strong Communication Strategy
Maintaining trust and credibility through transparent and timely communication is essential. Clear messaging prevents misinformation and reduces panic, ensuring stakeholders understand the situation and response efforts. Effective communication can mitigate negative perceptions and protect your brand, even in the face of serious incidents. Proper communication also helps ensure compliance with legal and regulatory requirements, avoiding fines and legal issues. Keeping stakeholders informed supports overall recovery efforts by maintaining engagement and trust.
Implementing Effective Communication Strategies
Preparation is key. Develop a crisis communication plan that outlines roles, responsibilities, and procedures. Scenario planning helps anticipate and prepare for different types of incidents. Speed and accuracy are critical. Provide regular updates as the situation evolves to keep stakeholders informed.
Consistency in messaging is vital. Ensure all communications are aligned across all channels and avoid jargon. Transparency and honesty are crucial—acknowledge the incident and its impact, and explain the steps being taken to address it. Showing empathy for those affected and offering support and resources demonstrates that your organization cares. Keep employees informed about the incident and the organization’s response through regular internal briefings to ensure all teams are aligned and prepared to handle inquiries.
Handling Open Public Dialogues
Involving skilled communicators who understand both the technical and broader implications of incidents is crucial. Coordination between legal and PR teams ensures that messaging is clear and accurate. Implement robust systems to track all public obligations, deadlines, and commitments, with regular audits to ensure compliance and documentation. Prepare for potential delays or issues with contingency plans and pre-drafted communications, and proactively communicate if commitments cannot be met on time.
- Communication with Major Customers: It often becomes necessary to keep major customers in the loop, providing them with timely updates and reassurances about the steps being taken. Build plans for how to proactively do this successfully.
- Clear Objectives and Measurable Criteria: Define clear and measurable criteria for what good public responses look like and manage to this. This helps ensure that all communications are effective and meet the required standards.
- External Expert Review: Retain external experts to review your incidents with a critical eye whenever possible. This helps catch misframing and gaps before you step into a tar pit.
- Clarity for External Parties: Remember that external parties won’t understand your organizational structure and team dynamics. It’s your responsibility to provide them with the information needed to interpret the report the way you intended.
- Sign-Off Process: Have a sign-off process for stakeholders, including technical, business, and legal teams, to ensure the report provides the right level of information needed by its readers.
- Track Commitments and Public Obligations: Track all your commitments and public obligations and respond by any committed dates. If you can’t meet a deadline, let the public know ahead of time.
In the end, humility, transparency, and accountability are what make a successful public report.
Case Study: WoSign’s Non-Recoverable Loss of Trust
Incident: WoSign was caught lying about several aspects of their certificate issuance practices, leading to a total non-recoverable loss of trust from major browsers and ultimately their removal from trusted root stores.
Outcome: The incident led to a complete loss of trust from major browsers.
Impact: This example underscores the importance of transparency and honesty in public reporting, as once trust is lost, it may never be regained.
Case Study: Symantec and the Erosion of Trust
Incident: Symantec, one of the largest Certificate Authorities (CAs), improperly issued numerous certificates, including test certificates for domains not owned by Symantec and certificates for Google domains without proper authorization. Their non-transparent, combative behavior, and unwillingness to identify the true root cause publicly led to their ultimate distrust.
Outcome: This resulted in a significant loss of trust in Symantec’s CA operations. Both Google Chrome and Mozilla Firefox announced plans to distrust Symantec certificates, forcing the company to transition its CA business to DigiCert.
Impact: The incident severely damaged Symantec’s reputation in the WebPKI community and resulted in operational and financial setbacks, leading to the sale of their CA business.
Conclusion
Navigating public reporting obligations in WebPKI and other sectors is undeniably complex and challenging. However, by prioritizing clear, honest communication and involving the right professionals, organizations can effectively manage these complexities. Rigorous tracking of obligations, proactive and transparent communication, and a robust incident response plan are critical. Case studies like those of WoSign and Symantec underscore the importance of transparency and honesty—once trust is lost, it may never be regained.
To maintain trust and protect your brand, develop a crisis communication plan that prioritizes speed, accuracy, and empathy. Consistent, transparent messaging across all channels is vital, and preparing for potential incidents with scenario planning can make all the difference. Remember, how you handle an incident can build or break trust. By learning from past mistakes and focusing on continuous improvement, organizations can navigate public reporting obligations more effectively, ensuring they emerge stronger and more resilient.