I advised Let’s Encrypt from its early days, watching it transform the security foundation of the web. Most think it won by offering free certificates. That’s dead wrong.
Existing CAs had already enabled free certificates years earlier. GlobalSign’s CloudSSL API, launched in 2011, (in full disclosure, I was their CTO), provided the automation that allowed Cloudflare to offer free SSL to end users; other CAs offered free short-lived certificates as part of forever trials as well. By 2015, you could buy DV certificates for $3-5 from certificate resellers, it was clear people were willing to pay for support which is largely what these resellers offered. The real story is about organizational constraints and misaligned incentives.
Conway’s Law Explains Everything
Traditional certificate authorities were trapped by their own organizational structure. Their business model incentivized vendor lock-in rather than ecosystem expansion and optimization. Sales teams wanted products’ proprietary APIs to make it harder for customers to switch, and were riding the wave of internet expansion. Compliance teams’ jobs depended on defending existing processes. Engineering teams were comfortable punting all compliance work to the “compliance” department. Support teams were positioned as competitive differentiators and used to entrench customers. Their goal was maximizing revenue, defending their jobs, and maintaining the status quo, not getting the web to 100% HTTPS.
Let’s Encrypt had completely different incentives and could optimize solving the larger problems without these organizational constraints. But LE’s success went beyond solving their own problems. They systematically identified every pain point in the way of getting to 100% HTTPS and built solutions that worked for everyone.
What LE Could Do That Traditional CAs Couldn’t
True standardization. Before ACME (the protocol that automates certificate requests), every major CA had incompatible automation systems. Comodo, DigiCert, GlobalSign and others each had proprietary approaches that required custom integration and as a result, had inherent switching costs; they saw no incentive to work together to standardize as a result. LE led the creation of ACME as an open standard that made switching CAs as simple as changing a configuration setting.
This enabled applications like Caddy and Google Cloud Load Balancer to handle certificates automatically for their customers without vendor-specific code. Once cloud platforms could flip switches to HTTPS-by-default, network effects became unstoppable.
Ecosystem-wide solutions. When LE felt coordination pain from renewal spikes and incident-related revocations, they created ACME Renewal Information (ARI, a protocol extension that helps coordinate renewal timing) so all CAs could prevent renewal storms. Traditional CAs couldn’t build these solutions because their org charts prevented optimizing for competitors’ success and instead focused on riding the internet expansion.
Engineering-driven compliance. Instead of compliance teams reviewing certificates after issuance, LE built policy compliance directly into certificate generation pipelines. Violations became orders of magnitude harder rather than detectable. Traditional CAs couldn’t eliminate their compliance departments because those jobs justified organizational overhead.
The Market Found Natural Segments
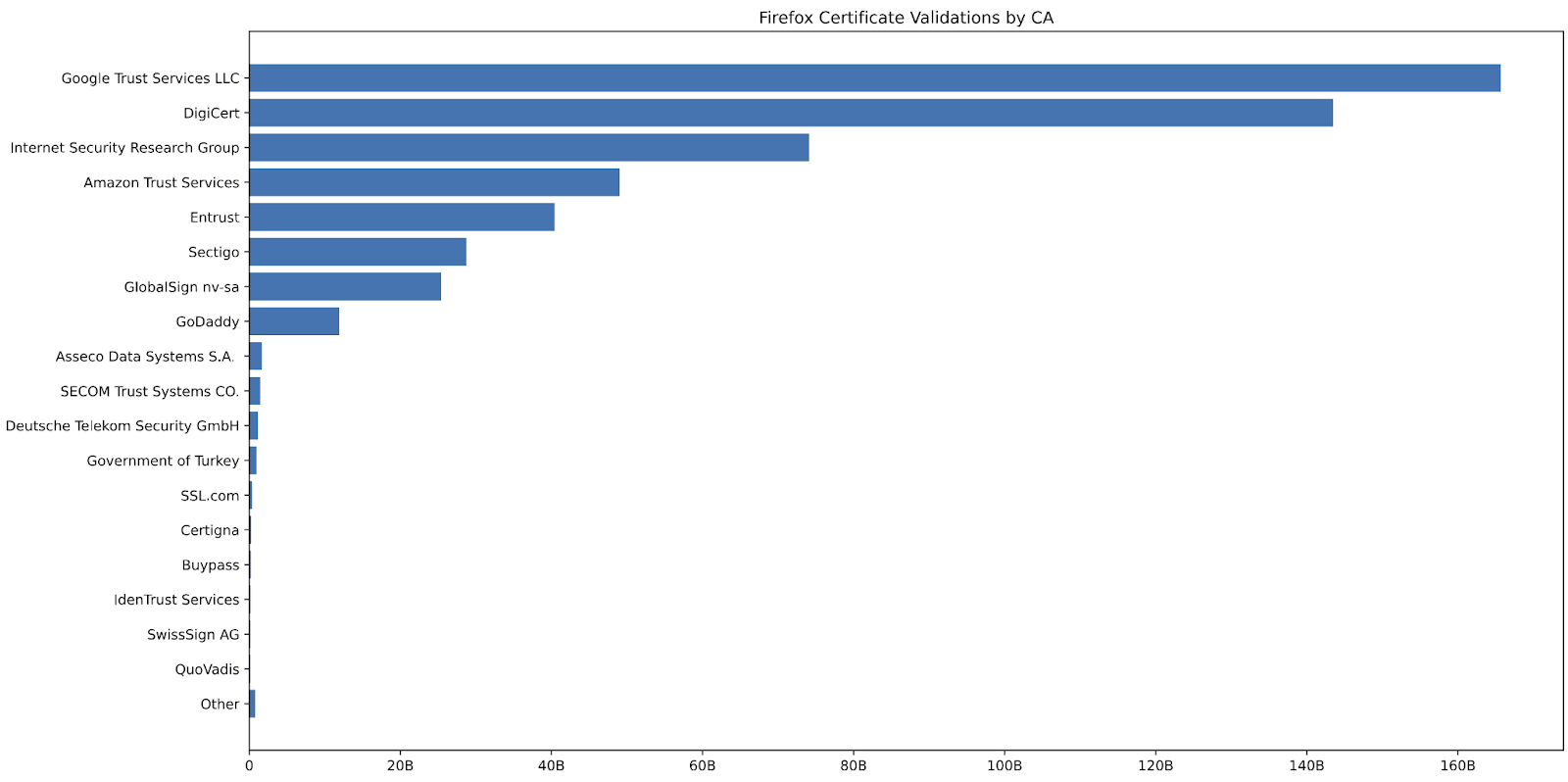
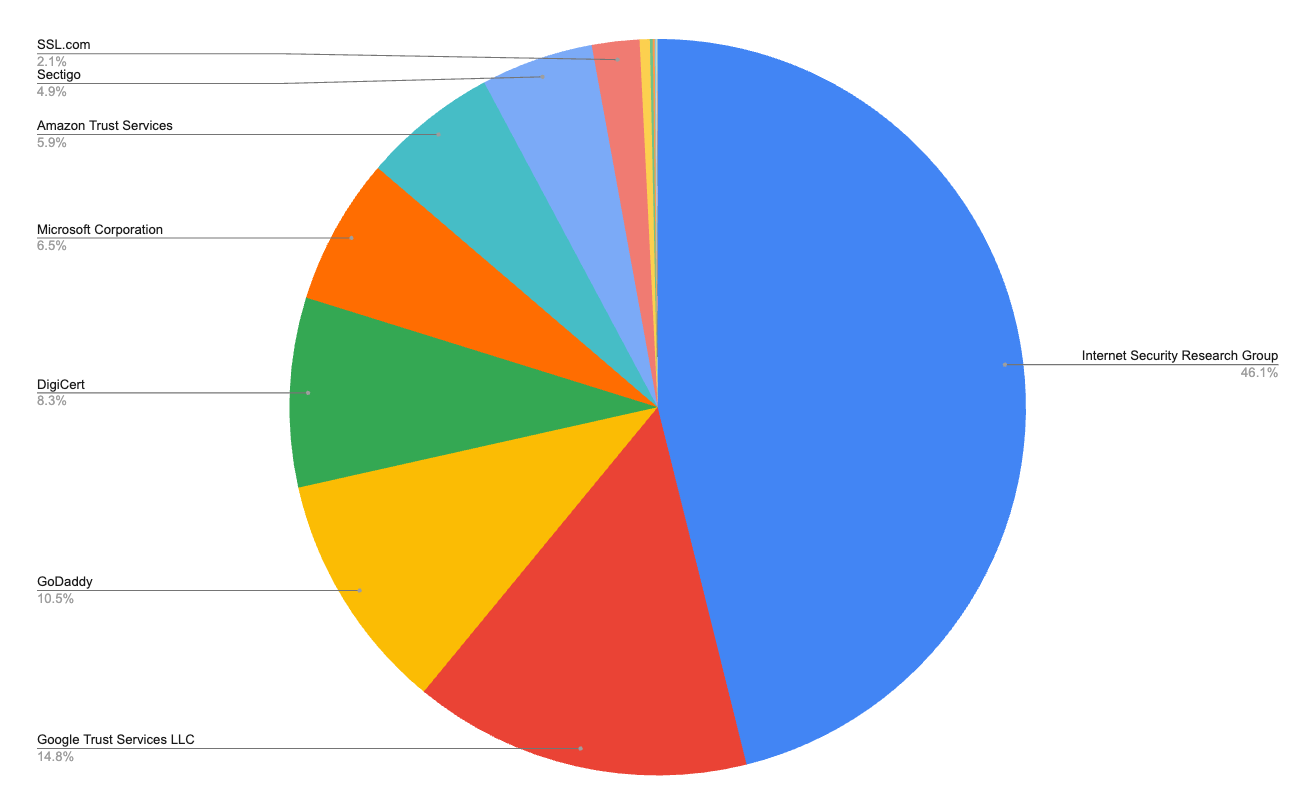
Mozilla telemetry reveals exactly what happened. Let’s Encrypt dominates issuance at 46.1% of certificates but ranks third in Firefox usage. LE democratized HTTPS for the long tail: domain parking networks, no-code builders, shared hosting platforms serving millions of low-traffic sites.
Meanwhile, high-traffic sites gravitated toward CAs like Google Trust Services (in full disclosure, I was responsible for creation of this service) that lead usage, as its used by large sites that value high availability and performance, leading to more relying party reliance despite lower issuance volumes, or established players like DigiCert and Sectigo that focus on supporting large enterprise customers. These sites need commercial support and accountability when things go wrong. The market is segmented around operational needs: the long tail valued automation over accountability, while major platforms needed enterprise support and someone to support them when something goes wrong.
Once long-tail providers flipped to HTTPS-by-default, encrypted pages became the norm. Google’s Transparency Report shows 99% of Chrome page-loads now occur over HTTPS, a transformation that began when Let’s Encrypt launched in April 2016.
The Industry Finally Admitted LE Was Right
Here’s the ultimate vindication: in 2025, the CA/Browser Forum mandated 47-day maximum certificate validity by 2029, with Chrome requiring automation from every public CA. Let’s Encrypt didn’t follow industry trends. The industry now follows Let’s Encrypt.
What seemed like LE’s “unusual” 90-day lifespans in 2016 became conservative by 2025. The mandate’s technical reasoning mirrors what LE pioneered: short-lived certificates reduce dependence on revocation checking, reduce key compromise windows, and force automated resilient infrastructure.
Leading organizations moved even further ahead. Netflix runs 30-day certificates in production, Google issues 7-day certificates for infrastructure, and Let’s Encrypt will introduce 6-day certificates by end of 2025. The mandates aren’t pushing innovation forward; they’re codifying where leaders already operate.
Why This Matters Beyond Certificates
Let’s Encrypt proved that critical internet infrastructure could be reimagined from first principles rather than optimized around legacy organizational constraints and practices. But the implications go deeper than certificate automation.
Traditional CAs were fundamentally vetting authorities with deep expertise in legal requirements for vetting people and businesses worldwide. They should have owned the remote identity verification market that exploded with digital transformation. Instead, they remained myopically focused on public trust-based certificate products while companies like Jumio and Onfido captured those opportunities. At the same time, they missed the massive expansion of machine and workload identity because they were ignoring private PKI use cases. They weren’t just leaving money on the table; they were failing to build a resilient business and neglecting the foundation for the trust infrastructure they supposedly managed.
The same organizational constraints that prevented CAs from building ACME also blinded them to adjacent markets that were natural extensions of their core competencies. They were too focused on maintaining certificate revenue streams and too constrained by existing structures to recognize how the world was shifting from hosting providers to cloud to SaaS.
ACME became the standard not because it was technically superior to existing APIs, though it was, but because it was designed for portability rather than lock-in. ARI emerged because LE experienced ecosystem pain and could fix it without navigating corporate bureaucracy or competitive concerns.
The complexity and friction we’d accepted for decades weren’t inherent to certificate management. It was the byproduct of organizational structures optimizing for vendor revenue rather than user adoption.
Today’s 47-day mandate represents more than policy evolution. It’s the industry formally acknowledging that Let’s Encrypt defined the correct approach for internet trust infrastructure. Conway’s Law isn’t destiny, but escaping it requires the courage to rebuild systems around user needs rather than organizational convenience.