Public Key Infrastructure was designed for a world where identities persisted for years—employees joining a company, servers running in data centers, devices connecting to networks. In this world, the deliberate pace of certificate issuance and revocation aligned perfectly with the natural lifecycle of these long-lived identities. But today’s cloud-native workloads—containers, serverless functions, and microservices—live and die in seconds, challenging these fundamental assumptions.
Though these ephemeral workloads still rely on public key cryptography for authentication, their deployment and management patterns break the traditional model. A container that exists for mere seconds to process a single request can’t wait minutes for certificate issuance. A serverless function that scales from zero to thousands of instances in moments can’t depend on manual certificate management. The fundamental mismatch isn’t about the cryptography—it’s about the infrastructure and processes built around it.
This isn’t a problem of public key infrastructure being inadequate but rather of applying it in a way that doesn’t align with modern workload realities. These new patterns challenge us to rethink how authentication and identity management systems should work—not just to ensure security, but to support the flexibility, performance, and speed that cloud-native infrastructure demands.
Why Workloads Are Different
Unlike human or machine identities, workloads are ephemeral by design. While a human identity might persist for years with occasional role changes, and a machine identity might remain tied to a server or device for months, workloads are created and destroyed on-demand. In many cases, they live just long enough to process a task before disappearing.
Unlike human and machine identities where identifiers are pre-assigned, workload identifiers must be dynamically assigned at runtime based on what is running and where. This transient nature makes revocation—a cornerstone of traditional PKI—irrelevant. There’s no need to revoke a workload’s credentials because they’ve already expired. In fact, much like Kerberos tickets, workload credentials are short-lived by design, issued for just long enough to meet deployment SLAs.
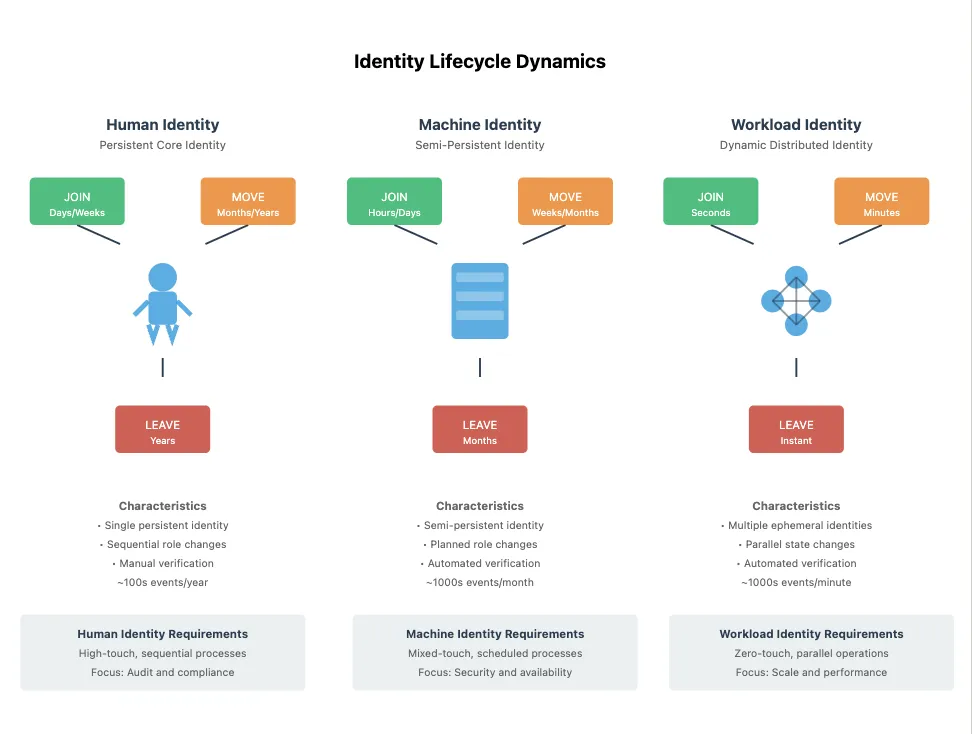
The Identity Lifecycle Dynamics graphic below illustrates these differences clearly:
- Human identities are persistent, often spanning years, with sequential changes governed by compliance and auditing processes.
- Machine identities are semi-persistent, lasting weeks or months, with planned updates and automated renewals sometimes tied to devices or hardware lifetimes.
- Workload identities, by contrast, are ephemeral. They join and leave almost instantly, with lifespans measured in minutes and operations occurring at massive scale.
Compounding this difference is the scale and speed at which workloads operate. It’s not unusual for thousands of workloads to be created simultaneously, each requiring immediate authentication. Traditional PKI processes, designed for slower-moving environments, simply can’t keep up. And workloads don’t just operate in isolation—they’re often distributed across multiple regions to minimize latency and avoid unnecessary points of failure. This means the supporting credentialing infrastructure must also be distributed, capable of issuing and verifying credentials locally without introducing bottlenecks or dependency risks.
Governance adds another layer of complexity. While human and machine identities are often subject to compliance-driven processes focused on auditability and security, workloads are governed by operational priorities:
- Zero downtime: Workloads must scale rapidly and without disruption.
- Regional performance: Authentication systems must match the workloads’ regional deployments to avoid latency.
- Developer flexibility: Identity systems must integrate with whatever technology stacks developers are already using.
The lifecycle of a workload identity reflects the immediacy of software deployment cycles, rather than the structured schedules of hardware or personnel management.
Rethinking Identity Infrastructure for Workloads
The traditional PKI model isn’t going away—it remains essential for the stable, predictable environments it was designed to support. But workloads require a shift in approach. They demand systems capable of:
- Dynamic credential issuance: Credentials must be created on-demand to support rapid scaling, with automated identifier assignment based on runtime context and workload characteristics.
- Ephemeral lifecycles: Workload credentials should expire automatically, eliminating the need for revocation, with lifecycle durations matched to actual workload runtime requirements.
- Multi-factor workload authentication: Something the workload has (hardware roots of trust, cryptographic keys), something the workload knows (runtime configuration), something the workload is (attestation data, container hashes, process metadata).
- Distributed infrastructure: Regional authentication systems ensure low latency and high availability, with local credential issuance capabilities.
- Massive scalability: Systems must support thousands of identity events per minute, operating across clouds or hybrid environments, with automated identifier management at scale.
- Runtime identifier assignment based on: What is running (container hashes, process information), Where it’s running (environment context, runtime attestation), how it’s running (execution environment verification).
As highlighted in the lifecycle comparison, workload identities aren’t simply a smaller, faster version of machine identities. Their governance models reflect their role in delivering business-critical objectives like seamless scaling and developer empowerment.
Perhaps the most significant difference is the role of developers. Workload identity systems can’t impose rigid, one-size-fits-all requirements. Developers need the freedom to:
- Work with existing technology stacks.
- Seamlessly integrate identity management into their workflows.
- Build and deploy at the speed demanded by modern infrastructure.
In this way, workload identity management becomes not just a security task but a foundational enabler of innovation and efficiency.
Taking the First Step with SPIFFE
SPIFFE (Secure Production Identity Framework For Everyone) is an open standard designed to enable workloads to automatically acquire identities, certificates, and OIDC tokens for secure zero-trust communication between services. Rather than retrofitting existing systems, look for upcoming greenfield deployments where you can engage early in the design phase. This allows you to build SPIFFE’s workload identity patterns in from the start—solving different problems than traditional PKI, not competing with it. Use this greenfield project to demonstrate how PKI as a technology via SPIFFE can help solve additional problems for production environments.
Final Thoughts
Workloads have redefined how we think about identity. They operate at a speed and scale that traditional PKI never anticipated, governed by different priorities and lifecycles that reflect the realities of modern software. While PKI will continue to serve as a critical component of authentication, it must evolve to meet the unique demands of ephemeral, distributed workloads.
This isn’t about abandoning the tools we rely on but about adapting them for a world where zero downtime, developer flexibility, and seamless scalability are non-negotiable. The future of identity isn’t static or centralized—it’s dynamic, distributed, and built to support workloads that define modern infrastructure.
For organizations looking to implement these patterns quickly and efficiently, SPIRL (a company I advise) provides tools to make workload identity management straightforward and accessible.