This morning I woke up to a blog post from Melih, the founder of Comodo titled “Problem vs Solution Value mapping”.
This is a follow-up to an ongoing discussion Melih and I have been having about the value of EV, and positive trust indicators. On my blog, the conversation started July 2017 if you’re interested.
Melih’s focuses his most recent post on the assessment of “value”, correctly attempting to define it as the basis of the rest of the post. He chooses to define it as “the direct result of a resolution to a problem.” I think it is this definition is the first part of his argument I have an issue with. Namely, The Oxford Dictionary defines “value” as “the regard that something is held to deserve; the importance, worth, or usefulness of something.”
When considering “value” with this definition, I believe an analysis of “value” would start by building a case on what is “deserved”. To do that, we have to also define a context in which that value is assessed. I think this is probably the hardest part, and probably where most of the disagreement on “value” of EV stems from.
If we say the context of this assessment is “the security and privacy guarantees that can be provided to the user by user agents to users” EV’s value is no better than that of DV. It is not a hard case to make either.
The security model of the browser is based on the concept of “origin” where that origin is essentially the “hostname” that the content was retrieved from. Any external website or resource embedded in the site (with rare exception) has the same permission as the original website as a result of this model. This is how web analytics work, advertising and many other products and services that make up the web.
Until user agents required all of these entities that make up a given site to use EV and to have the legal entity in all of the associated certificates match; EV is a false flag. It says “you are talking to this legal entity” when in-fact your talking to many legal entities and any one of them could equally harm you.
The reality is that if this change were to be made that you would almost never see EV badges though. This is because virtually every site is made up of content and services from across the web and this condition would almost never be met. This is why we do not see CAs making the argument that this rule should be enforced by UAs.
If we say the context of this assessment is “the average users practical ability to protect themselves from phishing” again EV does not fair well. There have been lots of user studies done on how users do not understand positive trust indicators, and in general, do even notice them in most cases.
Furthermore, even if we disregard these well-run studies (and the associated common sense) as Ian Carroll showed with his Stripe, Inc business in Kentucky the values displayed in these indicators can trivially be made, at a very low cost and with no traceability, be made to say whatever an attacker wants. This again frames EV as a false flag because it can so easily be used to lend credence to a phisher’s site by giving them the EV badge that says the same thing as their target site.
If this was not enough, again if we disregard these well-run studies and say that people need to take the responsibility for looking at the EV badge to get confidence they are dealing with a trustworthy entity we need to look no further than the work James Burton did when he got a certificate for his business “Identity Verified”. In this case, if a user has been taught to look at the EV indicator for an abstract concept of “trustworthiness” we are back to the user being mislead.
All of this ignores another very real problem, that being most phishing sites are not bespoke sites, instead, they are sites that are hacked and re-purposed. A good example of this is this one from a few weeks ago. What we appear to have here is a company called Northern Computer Services, LLC hosting a website for a business with the domain name “stampsbyjudith.com” hosting a Bank of America phishing site.

Now EV proponents surely see this as an example of EV working but if you look at it critically you will see it is exactly the opposite. First, could a customer believe that this “Northern Computer Services” is somehow a service provider to Bank of America? It seems reasonable to assume that the average user does not know anything about the way Bank Of America operates its services. In-fact even if you do have some level of understanding it’s incredibly common for banks to use service providers for different capabilities, maybe this Northern Computer Services hosts the BoFa website or provide billpay or mortgage services. How is the average user to know?
But what about the URL? There is no plausible way Bank Of America is hosting their site on the domain stampsbyjudith.com! Your absolutely right! it’s a fair expectation of us that if a user happens to look at the address bar that they should be able to figure that out. This is of course something you get when you use DV though, no EV necessary. Then there is the issue that studies also show that users do not look at the address bar either.
This is why Microsoft has created SmartScreen and Google has created Safe Browsing. These solutions utilize the massive scale and technology depth of these organizations along with machine learning and other advanced techniques to find phishing sites. As a result when a user navigates to a site similar to this one they get a interstitial warning them about proceeding.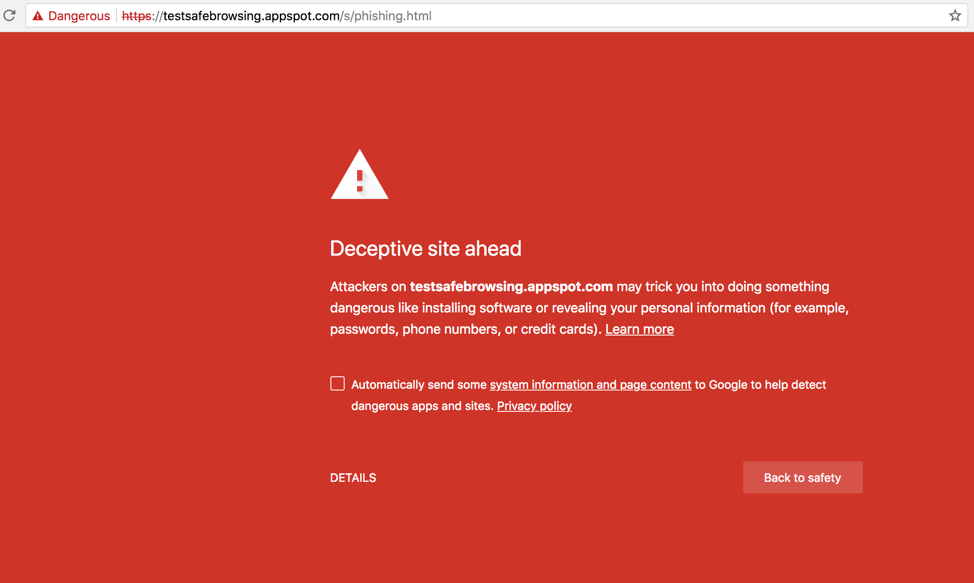
In summary, in this context, I would argue that as EV exists today it actually makes things harder on the user and easier on the attacker.
With that context in mind let’s explore each of the arguments that Melih makes.
Users want protection from Transit Providers. Sure they do but I would say the if a user framed the topic this way it would demonstrate the how little they actually understand of the problem in question. It is not just “transit providers” they need protection from, it is every entity other than those that are necessary to serve the application hosted at a domain.
Networking is so complex it is not possible to expect even some of the most technical users to understand all of the nuances involved here.
I would like to point out that Melih again attempts to redefine terms, this time in a disingenuous way. Specifically, in this part of his post suggest there is some common understanding that there is a difference between “encipherment” and “encryption”.
Let’s again take a look at what the Oxford Dictionary says:
Encryption – The process of converting information or data into a code, especially to prevent unauthorized access.
Encipherment – Convert (a message or piece of text) into a coded form.
As you can see, these words mean the same thing. The only difference being the example use case in one of the definitions. But maybe this inconsistency is use is because the Oxford Dictionary does not address a cryptographers view on these words? Unfortunately, that is not the case either, if you were to look at books like Serious Cryptography, Cryptography and Network Security, or even the very dated Applied Cryptography you will find no usage of these terms in this way.
What Melih has suggested in the past, and continues to do so in this section is that somehow if you authenticate only the domain and use that authentication as the basis for the session protection that this is not “encryption”.
Going so far to suggest that it is only encryption if you authenticate the legal entity. This is frankly ludicrous and I can not even respond to this more than I just have here.
I can say, that redefining a term, especially in such a specious way devalues any other valid points he may have.
But what about the users! The users want to know who they are dealing with! I actually agree with this but I also think it is far more complicated than users actually understand. So much so I would argue it is not possible to do in most cases. As a father when I run into situations where my kids want things that are not possible I sometimes joke with them and say “Well I want a pony!”.

It feels to me this is probably a case where that response is appropriate. The reality is there is not a globally unique business name, this is also the case with logos. Probably the best mainstream examples of this are the fake Starbucks stores and the notorial “Apple Stores” of Asia.


This is the nature of brand names, in-fact there is an entire discipline of law (Trademark Law) dedicated to this topic and multilateral international agreements on how such disputes are to be handled.
So in the context of the url, does EV as it stands today add or remove value? From my perspective, it seems to me at a minimum in this context it provides no value but I could also make a reasonable argument it makes things worse here as well due to the introduction of more surface area for confusion.
User’s want to know if its “safe” to interact with the website! Again I can agree with this, the problem is names do not harm — we even teach our kids rhymes to remind them of this fact:
Sticks and stones may break my bones, but names can never hurt me.
To keep users safe we have to look at far more than the name a website is hosted under; there are literally thousands of features that a solution intending to protect users safety need to consider and I would not be surprised to find out that the name is one of the least important.
This is, again, why we have solutions like SmartScreen and Safe Browsing these solutions are constantly watching feeds of data to determine if a website is safe or not. It is not possible to solve the “safety” problem in any meaningful way without similar techniques.
But user’s want to be able to trust the content they see! Again, I also think this is something that users want, I just don’t think they can have everything they want.
But before I talk about this I want to talk about how Melih is redefining a term again, he suggests that “trust” means “having the ability to validate VISA, Paypal logo etc”. The oxford dictionary defines trust as “Firm belief in the reliability, truth, or ability of someone or something.”
With that, I would think that it would be more correct to say that they want to believe what they see. This is of course a very natural thing, something scammers have taken advantage of since the dawn of time.

When considering this desire I think we have to ask ourselves what the best way we have to service the desire. We also have to acknowledge that malicious content is everywhere in the world (don’t forget our Fake Starbucks and Apple Stores from above) that the best we can do is provide a speedbump.
This is, again, why we have solutions like SmartScreen and Safe Browsing as they were designed, engineered and continually evolve to address these risks.
In closing, I believe EV as it stands today is a round peg in a square hole. This does not mean there is not value in knowing the legal identity of the organization who operates a website, it is also not because these third-parties can’t do more to help users manage the risks they are exposed to.

It is because EV is being sold as something it is not, a anti-phishing tool. Simply put it is not well suited to help with that problem and I would go so far that when we teach users to see it as such it even helps phishers.