As they say, Those who cannot remember the past are condemned to repeat it, as we look back at the last decade, it seems we are caught in our own little Groundhog Day, reexperiencing the consequences of weak authentication and poor key management over and over.
It is not that we don’t know how to mitigate these issues; it’s more that, as organizations, we tend to avoid making uncomfortable changes. For example, the recent spate of incidents involving Snowflake customers being compromised appears to be related to Snowflake not mandating multi-factor authentication or a strong hardware-backed authenticator like Passkeys for its customers.
At the same time, not all of these key and credential thefts are related to users; many involve API keys, signing keys used by services, or code signing keys. Keys we have been failing to manage appropriately to the risks they represent to our systems and customers.
Timeline of Notable Incidents
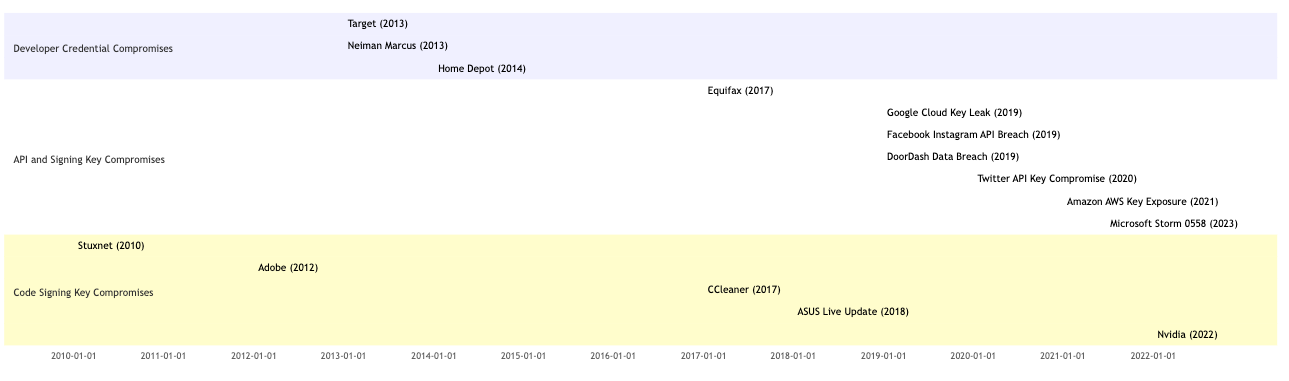
Table of Incidents
| Incident | Type of Compromise | Description |
|---|---|---|
| Stuxnet (2010) | Code Signing Keys | Utilized stolen digital certificates from Realtek and JMicron to authenticate its code, making it appear legitimate. |
| Adobe (2012) | Code Signing Keys | Attackers compromised a build server and signed malware with valid Adobe certificates. |
| Target (2013) | Developer Credentials | Network credentials stolen from a third-party HVAC contractor via malware on an employee’s home computer. |
| Neiman Marcus (2013) | Developer Credentials | Malware installed on systems, possibly through compromised credentials or devices from third-party vendors. |
| Home Depot (2014) | Developer Credentials | Malware infected point-of-sale systems, initiated by stolen vendor credentials, potentially compromised via phishing. |
| Equifax (2017) | API Keys | Exploitation of a vulnerability in Equifax’s website application exposed API keys used for authentication. |
| CCleaner (2017) | Code Signing Keys | Attackers inserted malware into CCleaner’s build process, distributing malicious versions of the software. |
| Ticketmaster (2018) | Developer Credentials | Malware from a third-party customer support product led to the compromise of payment information. |
| ASUS Live Update (2018) | Code Signing Keys | Attackers gained access to ASUS’s code signing keys and distributed malware through the update mechanism. |
| Google Cloud Key Leak (2019) | API Keys | Internal tool inadvertently exposed customer API keys on the internet, leading to potential data exposure. |
| Facebook Instagram API Breach (2019) | API Keys | Plaintext passwords were accessible to employees due to misuse of an internal API. |
| DoorDash Data Breach (2019) | API Keys | Unauthorized access to systems included the compromise of API keys, exposing sensitive customer data. |
| Mission Lane (2020) | Developer Credentials | Malware introduced into the development environment from a developer’s compromised personal device. |
| BigBasket (2020) | Developer Credentials | Data breach with over 20 million customer records exposed, suspected initial access through compromised developer credentials. |
| Twitter API Key Compromise (2020) | API Keys | Attackers gained access to internal systems, possibly compromising API keys or administrative credentials. |
| Amazon AWS Key Exposure (2021) | API Keys | Misconfigured AWS S3 bucket led to the exposure of API keys and sensitive customer data. |
| Nvidia (2022) | Code Signing Keys | Stolen code signing certificates were used to sign malware, making it appear legitimate. |
| Microsoft Storm 0558 (2023) | Signing Keys | Attackers gained access to email accounts of government agencies and other organizations by forging authentication tokens using a stolen Microsoft signing key. |
When we look at these incidents we see a few common themes including:
- Repetitive Failures in Security Practices:
- Despite awareness of the issues, organizations continue to face the same security breaches repeatedly. This suggests a reluctance or failure to implement effective long-term solutions.
- Resistance to Necessary Changes:
- Organizations often avoid making uncomfortable but necessary changes, such as enforcing multi-factor authentication (MFA) or adopting stronger authentication methods like Passkeys, and adopting work This resistance contributes to ongoing vulnerabilities and compromises.
- Diverse Sources of Compromise:
- Key and credential thefts are not solely due to user actions but also involve API keys, service signing keys, and code signing keys. This highlights the need for comprehensive key management and protection strategies that cover all types of keys.
- Broader Key Management Practices:
- Moving from shared secrets to asymmetric credentials for workloads and machines can significantly enhance security. Asymmetric credentials, especially those backed by hardware, are harder to steal and misuse compared to shared secrets. Techniques like attestation, which is the device equivalent of MFA, can provide additional security by verifying the authenticity of devices and systems.
- Third-Party Risks:
- Even if we deploy the right technologies in our own environment, we often ignore the security practices of our upstream providers. Several incidents involved third-party vendors or services (e.g., Target, Home Depot), highlighting the critical need for comprehensive third-party risk management. Organizations must ensure that their vendors adhere to strong security practices and protocols to mitigate potential risks.
- Mismanagement of API and Signing Keys:
- Incidents such as the Google Cloud Key Leak and Amazon AWS Key Exposure point to misconfigurations and accidental exposures of API keys. Proper configuration management, continuous monitoring, and strict access controls are essential to prevent these exposures.
- Importance of Multi-Factor Authentication (MFA):
- The absence of MFA has been a contributing factor in several breaches. Organizations need to mandate MFA to enhance security and reduce the risk of credential theft.
- Need for Secure Code Signing Practices:
- The use of stolen code-signing certificates in attacks like Stuxnet and Nvidia underscores the importance of securing code-signing keys. Implementing hardware security modules (HSMs) for key storage and signing can help mitigate these risks.
Conclusion
Looking back at the past decade of key and credential compromises, it’s clear that we’re stuck in a loop, facing the same issues repeatedly. It’s not about knowing what to do—we know the solutions—but about taking action and making sometimes uncomfortable changes.
Organizations need to step up and embrace multi-factor authentication, adopt strong hardware-backed authenticators like Passkeys, and move workloads from shared secrets to hardware-backed asymmetric credentials for better security. We also can’t overlook the importance of managing third-party risks and ensuring proper configuration and monitoring to protect our API and signing keys.
Breaking free from this cycle means committing to these changes. By learning from past mistakes and taking a proactive approach to key and credential management, we can better protect our systems and customers – It’s time to move forward.
