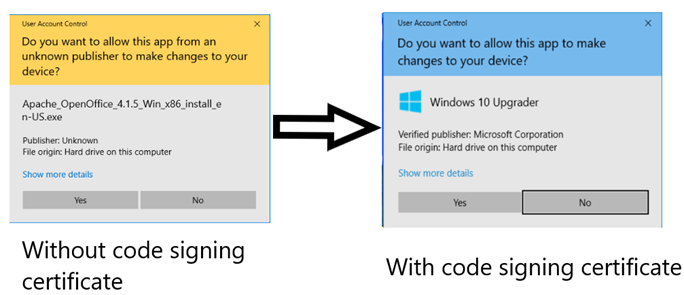
In the early 2000s, Microsoft mandated that all CAs in its root program would need to be audited for conformity to WebTrust For CAs (WebTrust), It was the first root program to do so and I was the root program manager that rolled out that change.
For those who are interested Web Trust for CAs is an audit that looks back at a period of past behavior to assess conformity to a set of criteria specific to certificate authorities. Only approved auditors are allowed to officially perform these assessments.
The decision to require the WebTrust audit was pretty simple, there was literally no other independent standard that attempted to assess the operational readiness and security of certificate authorities, and as far as such standards went it was more good than it was bad.
The other root programs didn’t have objective criteria, some operated on a pay-to-play model with virtually no requirements, while others simply wanted a management assertion of conformity to a small list of requirements and a contract signed.
The idea of working with an independent group that had a vested interest in creating a baseline standard for the operation of CAs, that would be able to evolve over time, seemed like a no-brainer given how poor and inconsistent CA practices were at the time.
Nearly two decades later the CA/Browser Forum is where the AICPA and others go to discuss how the audit criteria should evolve over time. It’s objectively a success in that today there is quite a bit of uniformity in the operational practices that CAs have and its existence has led to many improvements to the WebPKI.
With that said, if we go back to first principles today I think I would take a different approach. I would design a root program that was heavily based on technical security controls, and behaviors that can be verified externally continuously.
If we’re going first principles then let’s take a step back at what responsibility a CA has on the internet. A TLS certificate does one thing fundamentally, it binds a domain name to a public key. It does this so that user agents (browsers) can verify that the server on the other end can verify that they are talking to the right server.
This user agent believes this certificate is telling the truth because the browser operators will remove CAs that demonstrate they are not trustworthy.
Today I would guess 60-70% of the certificates on the web are issued via the ACME (RFC 8555) protocol. this protocol has a handful of methods it allows a requestor to use to prove they control the domain name (for example DNS-01, HTTP-01, and TLS-ALPN-02).
What this means is if ACME is the only way you can get a certificate from a CA, it also means that it is possible to externally test how the CA performs domain control verification.
There has been another innovation in this space, we now have Certificate Transparency, this is a community of append-only ledgers that in union contain all of the WebPKI certificates. If a certificate does not get logged to the CT ledgers then users with major browsers (Safari, Chrome, Edge, etc) will see an error when the user visits the associated site.
This now gets us a list of all the things, with this list we can programmatically review 100% of the certificate issuance to ensure that they meet the externally visible technical requirements. This already happens today in the WebPKI thanks to the excellent Zlint.
What about how the CAs key material is protected? I love a good HSM too! Well, some HSMs already support attestations about the keys they are protecting, for example, Google Cloud, and Amazon Web Services use Marvel HSMs in their cloud offering and those devices offer hardware attestations about how a given key is protected.
What about the software that makes up the service? Well, some languages make naturally reproducible builds, for example, Go. This means that you could conceptually run CA software on hardware capable of making attestations about what it is running and from that attestation and if that software was open source you could audit the behavior of that software for security and conformity criteria.
You could even go so far as incorporating these attestations into certificate transparency pre-certificates along with how the domain control verification was performed for the “final” certificate so these things could be audited on a per certificate basis.
You could take the additional step of schematizing all of the audit logs that each of these CAs is required to produce and require them to make them public and verifiable via something like an append-only ledger.
We could even go so far as to eliminate the need for revocation checking by adopting very short-lived certificates as a mandate.
Now don’t get me wrong, this isn’t a complete list, and I doubt there is any set of technical controls that would totally eliminate the need for onsite independent visits but I would argue that they could be more frequent or technically deeper if as an industry we could asses much of the conformity of CAs in real-time and track the changes to their infrastructure.
This sounds like a big lift, after all, there is a top of CAs that exist in the WebPKI, the reality is that the large majority of these don’t focus on TLS as demonstrated by the fact that 5 CAs issue 98.59% of all TLS certificates. This means that you wouldn’t need to get many entities to embrace this new model to cover most of the internet.
If you had enough participants this new root program could be very agile for this new root program. After a short period of initial automated testing and a signed letter of conformity from an auditor, you could automate the inclusion processes. Should the continental monitoring find an issue you could automate the reporting to the CA and even automate the distrust of the CA in some cases.
This new WebPKI would need to exist in parallel to the old one for a long time, in particular, the existence of all of the embedded devices without reasonable firmware update would hold back its total adoption as websites need certificates that work everywhere but you can see a path to an agile, continually verified web PKI that leveraged more of these technical controls rather than all of the manual and procedural verification that is involved today.
I want to be clear, the above is a thought exercise, I am not aware of anyone planning on doing anything like the above, but I do think after 20 years it is entirely reasonable to rethink the topic of what the WebPKI looks like and we don’t need to rest on old patterns “just because that’s how it is done” — we have come a long distance in the last couple of decades and it’s worth looking at back these problems now and again.