In the early 2000s, I was responsible for a number of core security technologies in Windows, including cryptography. As part of that role, we had an organizational push to support “vanity” national algorithms in SChannel (and thus SSL/TLS) and CMS. Countries like Austria and China wanted a simple DLL‑drop mechanism that would allow any application built on the Windows crypto stack to instantly support their homegrown ciphers.
On paper, it sounded elegant: plug in a new primitive and voilà, national‑sovereignty protocols everywhere. In practice, however, implementation proved far more complex. Every new algorithm required exhaustive validation, introduced performance trade-offs, risked violating protocol specifications, and broke interoperability with other systems using those same protocols and formats.
Despite these challenges, the threat of regulation and litigation pushed us to do the work. Thankfully, adoption was limited and even then, often misused. In the few scenarios where it “worked,” some countries simply dropped in their algorithm implementations and misrepresented them as existing, protocol-supported algorithms. Needless to say, this wasn’t a fruitful path for anyone.
As the saying goes, “failing to plan is planning to fail.” In this case, the experience taught us a critical lesson: real success lies not in one-off plug-ins, but in building true cryptographic agility.
We came to realize that instead of chasing edge-case national schemes, the real goal was a framework that empowers operators to move off broken or obsolete algorithms and onto stronger ones as threats evolve. Years after I left Microsoft, I encountered governments still relying on those early plugability mechanisms—often misconfigured in closed networks, further fracturing interoperability. Since then, our collective expertise in protocol engineering has advanced so far that the idea of dynamically swapping arbitrary primitives into a live stack now feels not just naïve, but fundamentally impractical.
Since leaving Microsoft, I’ve seen very few platforms, Microsoft or otherwise, address cryptographic agility end-to-end. Most vendors focus only on the slice of the stack they control (browsers prioritize TLS agility, for instance), but true agility requires coordination across both clients and servers, which you often don’t own.
My Definition of Crypto Agility
Crypto agility isn’t about swapping out ciphers. It’s about empowering operators to manage the full lifecycle of keys, credentials, and dependent services, including:
Generation of new keys and credentials
Use under real-world constraints
Rotation before algorithms weaken, keys exceed their crypto period, or credentials expire
Compromise response, including detection, containment, and rapid remediation
Library & implementation updates, patching or replacing affected crypto modules and libraries when weaknesses or compromises are identified
Retirement of outdated materials
Replacement with stronger, modern algorithms
Coincidentally, NIST has since released an initial public draft titled Considerations for Achieving Crypto Agility (CSWP 39 ipd, March 5, 2025), available here. In it, they define:
“Cryptographic (crypto) agility refers to the capabilities needed to replace and adapt cryptographic algorithms in protocols, applications, software, hardware, and infrastructures without interrupting the flow of a running system in order to achieve resiliency.”
That definition aligns almost perfectly with what I’ve been advocating for years—only now it carries NIST’s authority.
Crypto Agility for the 99%
Ultimately, consumers and relying parties—the end users, application owners, cloud tenants, mobile apps, and service integrators—are the 99% who depend on seamless, invisible crypto transitions. They shouldn’t have to worry about expired credentials, lapsed crypto periods, or how to protect and rotate algorithms without anxiety, extensive break budgets or downtime.
True agility means preserving trust and control at every stage of the lifecycle.
Of course, delivering that experience requires careful work by developers and protocol designers. Your APIs and specifications must:
Allow operators to choose permitted algorithms
Enforce policy-driven deprecation
A Maturity Roadmap
To make these lifecycle stages actionable, NIST’s Crypto Agility Maturity Model (CAMM) defines four levels:
Level 1 – Possible: Discover and inventory all keys, credentials, algorithms, and cipher suites in use. Catalog the crypto capabilities and policies of both parties.
Level 2 – Prepared: Codify lifecycle processes (generation, rotation, retirement, etc.) and modularize your crypto stack so that swapping primitives doesn’t break applications.
Level 3 – Practiced: Conduct regular “crypto drills” (e.g., simulated deprecations or compromises) under defined governance roles and policies.
Level 4 – Sophisticated: Automate continuous monitoring for expired credentials, lapsed crypto-period keys, deprecated suites, and policy violations triggering remediations without human intervention.
Embedding this roadmap into your operations plan helps you prioritize inventory, modularity, drills, and automation in the right order.
My Lifecycle of Algorithm and Key Management
This operator-focused lifecycle outlines the critical phases for managing cryptographic algorithms and associated keys, credentials, and implementations, including module or library updates when vulnerabilities are discovered:
Generation of new keys and credentials
Use under real-world constraints with enforced policy
Library & Implementation Updates, to address discovered vulnerabilities
Retirement of outdated keys, credentials, and parameters
Replacement with stronger, modern algorithms and materials
Each phase builds on the one before it. Operators must do more than swap out algorithms—they must update every dependent system and implementation. That’s how we minimize exposure and maintain resilience throughout the cryptographic lifecycle.
Conclusion
What’s the message then? Well, from my perspective, cryptographic agility isn’t a feature—it’s an operational mindset. It’s about building systems that evolve gracefully, adapt quickly, and preserve trust under pressure. That’s what resilience looks like in the age of quantum uncertainty and accelerating change.
“The world isn’t run by weapons anymore, or energy, or money. It’s run by little ones and zeroes, little bits of data. It’s all just electrons.” — Martin Bishop, Sneakers (1992)
I was 16 when I first watched Sneakers on a VHS tape rented from my local video store. Between the popcorn and plot twists, I couldn’t have known that this heist caper would one day seem less like Hollywood fantasy and more like a prophetic warning about our future. Remember that totally unassuming “little black box” – just an answering machine, right? Except this one could crack any code. The device that sent Robert Redford, Sidney Poitier, and their ragtag crew on a wild adventure. Fast forward thirty years, and that movie gadget gives those of us in cybersecurity a serious case of déjà vu.
Today, as quantum computing leaves the realm of theoretical physics and enters our practical reality, that fictional black box takes on new significance. What was once movie magic now represents an approaching inflection point in security – a moment when quantum algorithms like Shor’s might render our most trusted encryption methods as vulnerable as a simple padlock to a locksmith.
When Hollywood Met Quantum Reality
I’ve always found it deliciously ironic that Leonard Adleman – the “A” in RSA encryption – served as the technical advisor on Sneakers. Here was a man who helped create the mathematical backbone of modern digital security, consulting on a film about its theoretical downfall. What’s particularly fascinating is that Adleman took on this advisory role partly so his wife could meet Robert Redford! His expertise is one reason why the movie achieves such technical excellence. It’s like having the architect of a castle advising on a movie about the perfect siege engine. For what feels like forever – three whole decades – our world has been chugging along on a few key cryptographic assumptions. We’ve built trillion-dollar industries on the belief that certain mathematical problems—factoring large numbers or solving discrete logarithms—would remain practically impossible for computers to solve. Yep, our most of security is all built on these fundamental mathematical ideas. Sneakers playfully suggested that one brilliant mathematician might find a shortcut through these “unsolvable” problems. The movie’s fictional Gunter Janek discovered a mathematical breakthrough that rendered all encryption obsolete – a cinematic prediction that seemed far-fetched in 1992.
Yet here we are in the 2020s, watching quantum computing advance toward that very capability. What was once movie magic is becoming technological reality. The castle walls we’ve relied on aren’t being scaled—they’re being rendered obsolete by a fundamentally different kind of siege engine.
The Real Horror Movie: Our Security Track Record
Hollywood movies like Sneakers imagine scenarios where a single breakthrough device threatens our digital security. But here’s the kicker, and maybe the scarier part: the real threats haven’t been some crazy math breakthrough, but the everyday stuff – those operational hiccups in the ‘last mile’ of software supply chain and security management. I remember the collective panic during the Heartbleed crisis of 2014. The security community scrambled to patch the vulnerability in OpenSSL, high-fiving when the code was fixed. But then came the sobering realization: patching the software wasn’t enough. The keys – those precious secrets exposed during the vulnerability’s window – remained unchanged in countless systems. It was like installing a new lock for your door but having it keyed the same as the old one all the while knowing copies of the key still sitting under every mat in the neighborhood. And wouldn’t you know it, this keeps happening, which is frankly a bit depressing. In 2023, the Storm-0558 incident showed how even Microsoft – with all its resources and expertise – could fall victim to pretty similar failures. A single compromised signing key allowed attackers to forge authentication tokens and breach government email systems. The digital equivalent of a master key to countless doors was somehow exposed, copied, and exploited. Perhaps most illustrative was the Internet Archive breach. After discovering the initial compromise, they thought they’d secured their systems. What they missed was complete visibility into which keys had been compromised. The result? Attackers simply used the overlooked keys to walk right back into the system later. Our mathematical algorithms may be theoretically sound, but in practice, we keep stumbling at the most human part of the process: consistently managing the lifecycle of the software and cryptographic keys through theih entire lifecycle. We’re brilliant at building locks but surprisingly careless with the keys.
From Monochrome Security to a Quantum Technicolor
Think back to when TVs went from black and white to glorious color. Well, cryptography’s facing a similar leap, except instead of just adding RGB, we’re talking about a whole rainbow of brand new, kinda wild frequencies. For decades, we’ve lived in a relatively simple cryptographic world. RSA and ECC have been the reliable workhorses – the vanilla and chocolate of the security ice cream shop. Nearly every secure website, VPN, or encrypted message relies on these algorithms. They’re well-studied, and deeply embedded in our digital infrastructure. But quantum computing is forcing us to expand our menu drastically. Post-quantum cryptography introduces us to new mathematical approaches with names that sound like science fiction concepts: lattice-based cryptography, hash-based signatures, multivariate cryptography, and code-based systems. Each of these new approaches is like a different musical instrument with unique strengths and limitations. Lattice-based systems offer good all-around performance but require larger keys. Hash-based signatures provide strong security guarantees but work better for certain applications than others. Code-based systems have withstood decades of analysis but come with significant size trade-offs. That nice, simple world where one crypto algorithm could handle pretty much everything? Yeah, that’s fading fast. We’re entering an era where cryptographic diversity isn’t just nice to have – it’s essential for survival. Systems will need to support multiple algorithms simultaneously, gracefully transitioning between them as new vulnerabilities are discovered. This isn’t just a technical challenge – it’s an operational one. Imagine going from managing a small garage band to conducting a full philharmonic orchestra. The complexity doesn’t increase linearly; it explodes exponentially. Each new algorithm brings its own key sizes, generation processes, security parameters, and lifecycle requirements. The conductor of this cryptographic orchestra needs perfect knowledge of every instrument and player.
The “Operational Gap” in Cryptographic Security
Having come of age in the late ’70s and ’80s, I’ve witnessed the entire evolution of security firsthand – from the early days of dial-up BBSes to today’s quantum computing era. The really wild thing is that even with all these fancy new mathematical tools, the core questions we’re asking about trust haven’t actually changed all that much. Back in 1995, when I landed my first tech job, key management meant having a physical key to the server room and maybe for the most sensitive keys a dedicated hardware device to keep them isolated. By the early 2000s, it meant managing SSL certificates for a handful of web servers – usually tracked in a spreadsheet if we were being diligent. These days, even a medium-sized company could easily have hundreds of thousands of cryptographic keys floating around across all sorts of places – desktops, on-premise service, cloud workloads, containers, those little IoT gadgets, and even some old legacy systems. The mathematical foundations have improved, but our operational practices often remain stuck in that spreadsheet era. This operational gap is where the next evolution of cryptographic risk management must focus. There are three critical capabilities that organizations need to develop before quantum threats become reality:
1. Comprehensive Cryptographic Asset Management
When a major incident hits – think Heartbleed or the discovery of a new quantum breakthrough – the first question security teams ask is: “Where are we vulnerable?” Organizations typically struggle to answer this basic question. During the Heartbleed crisis, many healthcare organizations spent weeks identifying all their vulnerable systems because they lacked a comprehensive inventory of where OpenSSL was deployed and which keys might have been exposed. What should have been a rapid response turned into an archaeological dig through their infrastructure. Modern key management must include complete visibility into:
Where’s encryption being used?
Which keys are locking down which assets?
When were those keys last given a fresh rotation?
What algorithms are they even using?
Who’s got the keys to the kingdom?
What are all the dependencies between these different crypto bits?
Without this baseline visibility, planning or actually pulling off a quantum-safe migration? Forget about it.
2. Rapid Cryptographic Incident Response
When Storm-0558 hit in 2023, the most alarming aspect wasn’t the initial compromise but the uncertainty around its scope. Which keys were affected? What systems could attackers access with those keys? How quickly could the compromised credentials be identified and rotated without breaking critical business functions? These questions highlight how cryptographic incident response differs from traditional security incidents. When a server’s compromised, you can isolate or rebuild it. When a key’s compromised, the blast radius is often unclear – the key might grant access to numerous systems, or it might be one of many keys protecting a single critical asset. Effective cryptographic incident response requires:
Being able to quickly pinpoint all the potentially affected keys when a vulnerability pops up.
Having automated systems in place to generate and deploy new keys without causing everything to fall apart.
A clear understanding of how all the crypto pieces fit together so you don’t cause a domino effect.
Pre-planned procedures for emergency key rotation that have been thoroughly tested, so you’re not scrambling when things hit the fan.
Ways to double-check that the old keys are completely gone from all systems.
Forward-thinking organizations conduct tabletop exercises for “cryptographic fire drills” – working through a key compromise and practicing how to swap them out under pressure. When real incidents occur, these prepared teams can rotate hundreds or thousands of critical keys in hours with minimal customer impact, while unprepared organizations might take weeks with multiple service outages.
3. Cryptographic Lifecycle Assurance
Perhaps the trickiest question in key management is: “How confident are we that this key has been properly protected throughout its entire lifespan?” Back in the early days of security, keys would be generated on secure, air-gapped systems, carefully transferred via physical media (think floppy disks!), and installed on production systems with really tight controls. These days, keys might be generated in various cloud environments, passed through CI/CD pipelines, backed up automatically, and accessed by dozens of microservices. Modern cryptographic lifecycle assurance needs:
Making sure keys are generated securely, with good randomness.
Storing keys safely, maybe even using special hardware security modules.
Automating key rotation so humans don’t have to remember (and potentially mess up).
Keeping a close eye on who can access keys and logging everything that happens to them.
Securely getting rid of old keys and verifying they’re really gone.
Planning and testing that you can actually switch to new crypto algorithms smoothly.
When getting ready for post-quantum migration, organizations often discover keys in use that were generated years ago under who-knows-what conditions, leading to them discovering that they need to do a complete overhaul of their key management practices.
Business Continuity in the Age of Cryptographic Change
If there’s one tough lesson I’ve learned in all my years in tech, it’s that security and keeping the business running smoothly are constantly pulling in opposite directions. This tension is especially noticeable when we’re talking about cryptographic key management. A seemingly simple crypto maintenance task can also turn into a business disaster because you have not properly tested things ahead of time, leaving you in a state where you do not understand the potential impact if these tasks if things go wrong. Post-quantum migration magnifies these risks exponentially. You’re not just updating a certificate or rotating a key – you’re potentially changing the fundamental ways systems interoperate all at once. Without serious planning, the business impacts could be… well, catastrophic. The organizations that successfully navigate this transition share several characteristics:
They treat keeping crypto operations running as a core business concern, not just a security afterthought.
They use “cryptographic parallel pathing” – basically running the old and new crypto methods side-by-side during the switch.
They put new crypto systems through really rigorous testing under realistic conditions before they go live.
They roll out crypto changes gradually, with clear ways to measure if things are going well.
They have solid backup plans in case the new crypto causes unexpected problems.
Some global payment processors have developed what some might call “cryptographic shadow deployments” – they run the new crypto alongside the old for a while, processing the same transactions both ways but only relying on the old, proven method for actual operations. This lets them gather real-world performance data and catch any issues before customers are affected.
From Janek’s Black Box to Your Security Strategy
As we’ve journeyed from that fictional universal codebreaker in Sneakers to the very real quantum computers being developed today, it strikes me how much the core ideas of security haven’t actually changed. Back in the 1970s security was mostly physical – locks, safes, and vaults. The digital revolution just moved our valuables into the realm of ones and zeros, but the basic rules are still the same: figure out what needs protecting, control who can get to it, and make sure your defenses are actually working. Post-quantum cryptography doesn’t change these fundamentals, but it does force us to apply them with a whole new level of seriousness and sophistication. The organizations that suceed in this new world will be the ones that use the quantum transition as a chance to make their cryptographic operations a key strategic function, not just something they do because they have to. The most successful will:
Get really good at seeing all their crypto stuff and how it’s being used.
Build strong incident response plans specifically for when crypto gets compromised.
Make sure they’re managing the entire lifecycle of all their keys and credentials properly.
Treat crypto changes like major business events that need careful planning.
Use automation to cut down on human errors in key management.
Build a culture where doing crypto right is something people value and get rewarded for.
The future of security is quantum-resistant organizations.
Gunter Janek’s fictional breakthrough in Sneakers wasn’t just about being a math whiz – it was driven by very human wants. Similarly, our response to quantum computing threats won’t succeed on algorithms alone; we’ve got to tackle the human and organizational sides of managing crypto risk. As someone who’s seen the whole evolution of security since the ’70s, I’m convinced that this quantum transition is our best shot at really changing how we handle cryptographic key management and the associated business risks.
By getting serious about visibility, being ready for incidents, managing lifecycles properly, and planning for business continuity, we can turn this challenge into a chance to make some much-needed improvements. The black box from Sneakers is coming – not as a device that instantly breaks all encryption, but as a new kind of computing that changes the whole game.
The organizations that come out on top won’t just have the fanciest algorithms, but the ones that have the discipline to actually use and manage those algorithms and associated keys and credentials effectively.
So, let’s use this moment to build security systems that respect both the elegant math of post-quantum cryptography and the wonderfully messy reality of human organizations.
We’ve adapted before, and we’ll adapt again – not just with better math, but with better operations, processes, and people. The future of security isn’t just quantum-resistant algorithms; it’s quantum-resistant organizations.
What took the telecommunications industry a century to experience—the full evolution from groundbreaking innovation to commoditized utility status—cloud computing is witnessing in just 15 years. This unprecedented compression isn’t merely faster; it represents a significant strategic challenge to cloud providers who believe their operational expertise remains a durable competitive advantage.
The historical parallel is instructive, yet nuanced. While telecom’s path offers warnings, cloud providers still maintain substantial advantages through their physical infrastructure investments and service ecosystems.
Telecom’s Transformation: Lessons for Cloud Providers
In 1984, AT&T was the undisputed titan of American business—a monopolistic giant controlling communication infrastructure so vital that it was deemed too essential to fail. Its operational expertise in managing the world’s most complex network was unmatched, its infrastructure an impenetrable competitive moat, and its market position seemingly unassailable.
Four decades later, telecom companies have been substantially transformed. Their networks, while still valuable assets, no longer command the premium they once did. The 2024 Salt Typhoon cyberattacks revealed vulnerabilities in these once-impregnable systems—targeting nine major US telecom providers and compromising systems so thoroughly that the FBI directed citizens toward encrypted messaging platforms instead of traditional communication channels.
This transformation contains critical lessons for today’s cloud providers.
Telecom’s journey followed a predictable path:
Innovation to Infrastructure: Pioneering breakthroughs like the telephone transformed into sprawling physical networks that became impossible for competitors to replicate.
Operational Excellence as Moat: By mid-century, telecom giants weren’t just valued for their copper wire—their ability to operate complex networks at scale became their true competitive advantage.
Standardization and Erosion: Over decades, standardization (TCP/IP protocols) and regulatory action (AT&T’s breakup) gradually eroded these advantages, turning proprietary knowledge into common practice.
Value Migration: As physical networks became standardized, value shifted to software and services running atop them. Companies like Skype and WhatsApp captured value without owning a single mile of cable.
Security Crisis: Commoditization led to chronic underinvestment, culminating in the catastrophic Salt Typhoon vulnerabilities that finally shattered the public’s trust in legacy providers.
Cloud providers are accelerating through similar phases, though with important distinctions that may alter their trajectory.
Cloud’s Compressed Evolution: 7x Faster Than Telecom
The cloud industry is experiencing its innovation-to-commoditization cycle at hyperspeed. What took telecom a century is unfolding for cloud in approximately 15 years—a roughly 7-fold acceleration—though the endgame may differ significantly.
Consider the timeline compression:
What took long-distance calling nearly 50 years to transform from premium service to essentially free, cloud storage accomplished in less than a decade—with prices dropping over 90%.
Features that once justified premium pricing (load balancing, auto-scaling, managed databases) rapidly became table stakes across all providers.
APIs and interfaces that were once proprietary differentiators are now essentially standardized, with customers demanding cross-cloud compatibility.
This accelerated commoditization has forced cloud providers to rely heavily on their two enduring advantages:
Massive Infrastructure Scale: The capital-intensive nature of global data center networks
Operational Excellence: The specialized expertise required to run complex, global systems reliably
The first advantage remains formidable—the sheer scale of hyperscalers’ infrastructure represents a massive barrier to entry that will endure. The second, however, faces new challenges.
The Evolving Moat: How AI is Transforming Operational Expertise
Cloud providers’ most valuable operational asset has been the expertise required to run complex, distributed systems at scale. This knowledge has been nearly impossible to replicate, requiring years of specialized experience managing intricate environments.
AI is now systematically transforming this landscape:
AI-Powered Operations Platforms: New tools are encapsulating advanced operational knowledge, enabling teams to implement practices once reserved for elite cloud operations groups.
Cross-Cloud Management Systems: Standardized tools and AI assistance are making it possible for organizations to achieve operational excellence across multiple cloud providers simultaneously—an important shift in vendor dynamics.
Democratized Security Controls: Advanced security practices once requiring specialized knowledge are now embedded in automated tools, making sophisticated protection more widely accessible.
AI is transforming operational expertise in cloud computing. It isn’t eliminating the value of human expertise but rather changing who can possess it and how it’s applied. Tasks that once took years for human operators to master can now be implemented more consistently by AI systems. However, these systems have important limitations that still require human experts to address. While AI reduces the need for certain routine skills, it amplifies the importance of human experts in strategic oversight, ensuring that AI is used effectively and ethically.
The New Infrastructure Reality: Beyond Provider Lock-In
The fundamental value of cloud infrastructure isn’t diminishing—in fact, with AI workloads demanding unprecedented compute resources, the physical footprint of major providers becomes even more valuable. What’s changing is the level of provider-specific expertise required to leverage that infrastructure effectively.
The Multi-Cloud Opportunity
AI-powered operations are making multi-cloud strategies increasingly practical:
Workload Portability: Organizations can move applications between clouds with reduced friction
Best-of-Breed Selection: Companies can choose optimal providers for specific workloads
Cost Optimization: Customers can leverage price competition between providers more effectively
Risk Mitigation: Businesses can reduce dependency on any single provider
This doesn’t mean companies will abandon major cloud providers. Rather, they’ll be more selective about where different workloads run and more willing to distribute them across providers when advantageous. The infrastructure remains essential—what changes is the degree of lock-in.
The New Challenges: Emerging Demands on Cloud Operations
As operational advantages evolve, cloud providers face several converging forces that will fundamentally reshape traditional models. These emerging challenges extend beyond conventional scaling issues, creating qualitative shifts in how cloud infrastructure must be designed, managed, and secured.
The Vibe Coding Revolution
“Vibe coding” transforms development by enabling developers to describe problems in natural language and have AI generate the underlying code. This democratizes software creation while introducing different infrastructure demands:
Applications become more dynamic and experimental, requiring more flexible resources
Development velocity accelerates dramatically, challenging traditional operational models
Debugging shifts from code-focused to prompt-focused paradigms
As newer generations of developers increasingly rely on LLMs, critical security challenges emerge around software integrity and trust. The abstraction between developer intent and implementation creates potential blind spots, requiring governance models that balance accessibility with security.
Meanwhile, agentic AI reshapes application deployment through autonomous task orchestration. These agents integrate disparate services and challenge traditional SaaS models as business logic migrates into AI. Together, these trends accelerate cloud adoption while creating challenges for conventional operational practices.
The IoT and Robotics Acceleration
The Internet of Things is creating unprecedented complexity with over 30 billion connected devices projected by 2026. This expansion fragments the operational model, requiring seamless management across central cloud and thousands of edge locations. The boundary between edge and cloud creates new security challenges that benefit from AI-assisted operations.
Robotics extends this complexity further as systems with physical agency:
Exhibit emergent behaviors that weren’t explicitly programmed
Create operational challenges where physical and digital domains converge
Introduce security implications that extend beyond data protection to physical safety
Require real-time processing with strict latency guarantees that traditional cloud models struggle to address
The fleet management of thousands of semi-autonomous systems requires entirely new operational paradigms that bridge physical and digital domains.
The AI Compute Demand
AI training and inference are reshaping infrastructure requirements in ways that differ fundamentally from traditional workloads. Large language model training requires unprecedented compute capacity, while inference workloads demand high availability with specific performance characteristics. The specialized hardware requirements create new operational complexities as organizations balance:
Resource allocation between training and inference
Specialized accelerators with different performance characteristics
Cost optimization as AI budgets expand across organizations
Dynamic scaling to accommodate unpredictable workload patterns
These represent fundamentally different resource consumption patterns that cloud architectures must adapt to support—not simply larger versions of existing workloads.
The Security Imperative
As systems grow more complex, security approaches must evolve beyond traditional models. The attack surface has expanded beyond what manual security operations can effectively defend, while AI-powered attacks require equally sophisticated defensive capabilities. New security challenges include:
Vibe-coded applications where developers may not fully understand the generated code’s security implications
Robotics systems with physical agency creating safety concerns beyond data protection
Emergent behaviors in AI-powered systems requiring dynamic security approaches
Compliance requirements across jurisdictions demanding consistent enforcement at scale
Current cloud operations—even with elite human teams—cannot scale to these demands. The gap between operational requirements and human capabilities points toward AI-augmented security as the only viable path forward.
The Changing Competitive Landscape: A 5-10 Year Horizon
Over the next 5-10 years, these technological shifts will create significant changes in the cloud marketplace. While the timing and magnitude of these changes may vary, clear patterns are emerging that will reshape competitive dynamics, pricing models, and value creation across the industry.
Value Migration to Orchestration and Agentic Layers
Just as telecom saw value shift from physical networks to OTT services, cloud is experiencing value migration toward higher layers of abstraction. Value is increasingly found in:
Multi-cloud management platforms that abstract away provider differences
AI-powered operations tools that reduce the expertise barrier
Specialized services optimized for specific workloads or regulatory regimes
AI development platforms that facilitate vibe coding approaches
Agentic AI systems that can autonomously orchestrate tasks across multiple services
Hybrid SaaS/AI solutions that combine traditional business logic with intelligent automation
This doesn’t eliminate infrastructure’s value but alters competitive dynamics and potentially compresses margins for undifferentiated services. As Chuck Whitten noted regarding agentic AI’s impact on SaaS: “Transitions lead not to extinction but to transformation, adaptation, and coexistence.”
Increased Price Sensitivity for Commodity Services
As switching costs decrease through standardization and AI-powered operations, market dynamics shift significantly. We’re seeing:
Basic compute, storage, and networking becoming more price-sensitive
Value-added services facing more direct competition across providers
Specialized capabilities maintaining premium pricing while commoditized services face margin pressure
This creates a strategic landscape where providers must carefully balance commoditized offerings with differentiated services that address specific performance, security, or compliance requirements.
The Rise of Specialized Clouds
The market is evolving toward specialization rather than one-size-fits-all solutions. Three key categories are emerging:
Industry-specific clouds optimized for particular regulatory requirements in healthcare, finance, and government
Performance-optimized environments for specific workload types like AI, HPC, and real-time analytics
Sovereignty-focused offerings addressing geopolitical concerns around data governance and control
These specialized environments maintain premium pricing even as general-purpose computing becomes commoditized, creating opportunities for focused strategies that align with specific customer needs.
Salt Typhoon as a Cautionary Tale
The telecom industry’s commoditization journey reached a critical inflection point with the 2024-2025 Salt Typhoon cyberattacks. These sophisticated breaches targeted nine major US telecommunications companies, including giants like Verizon, AT&T, and T-Mobile, compromising sensitive systems and exposing metadata for over a million users. This crisis revealed how commoditization had led to chronic underinvestment in security innovation and resilience.
The aftermath was unprecedented: the FBI directed citizens toward encrypted messaging platforms as alternatives to traditional telecommunication—effectively steering users away from legacy infrastructure toward newer, more secure platforms. This government-endorsed abandonment of core telecom services represented the ultimate consequence of commoditization. Just as commoditization eroded telecom’s security resilience, cloud providers risk a similar fate if they grow complacent in an increasingly standardized market.
While cloud providers currently prioritize security more than telecom historically did, the Salt Typhoon incident illustrates the dangers of underinvestment in a commoditizing field. With innovation cycles compressed roughly 7-fold compared to telecom—meaning cloud technologies evolve at a pace telecom took decades to achieve—they have even less time to adapt before facing similar existential challenges. As AI agents and orchestration platforms abstract cloud-specific expertise—much like telecom’s reliance on standardized systems—security vulnerabilities could emerge, mirroring the weaknesses Salt Typhoon exploited.
Stakeholder Implications
The accelerating commoditization of cloud services transforms the roles and relationships of all stakeholders in the ecosystem. Understanding these implications is essential for strategic planning.
For Operations Teams
The shift from hands-on execution to strategic oversight represents a fundamental change in skill requirements. Engineers who once manually configured infrastructure will increasingly direct AI systems that handle implementation details. This evolution mirrors how telecom network engineers transitioned from hardware specialists to network architects as physical infrastructure became abstracted.
Success in this new paradigm requires developing expertise in:
AI oversight and governance
Cross-cloud policy management
Strategic technology planning
Risk assessment and mitigation
Rather than platform-specific implementation knowledge, the premium skills become those focused on business outcomes, security posture, and strategic optimization.
For Customers & End Users
The democratization of operational expertise through AI fundamentally transforms the customer’s role in the cloud ecosystem. Just as telecom users evolved from passive consumers of fixed telephone lines to active managers of their communication tools, cloud customers are transitioning from consumers of provider expertise to directors of AI-powered operations.
Enterprise teams no longer need specialized knowledge for each platform, as AI agents abstract away complexity. Decision-making shifts from “which cloud provider has the best expertise?” to “which orchestration layer best manages our multi-cloud AI operations?” This democratization dramatically reduces technical barriers to cloud migration and multi-cloud strategies, accelerating adoption while increasing provider switching frequency.
For Security Posture
The Salt Typhoon breach offers a sobering lesson about prioritizing efficiency over security innovation. The democratization of operational expertise through AI creates a paradox: security becomes both more challenging to maintain and more essential as a differentiator.
Organizations that can augment AI-driven security with human expertise in threat hunting and response will maintain an edge in an increasingly commoditized landscape. Without this focus, cloud providers risk becoming the next victims of a Salt Typhoon-scale breach that could potentially result in similar government recommendations to abandon their services for more secure alternatives.
For the Industry as a Whole
The drastic compression of innovation cycles means even foundational assets—massive infrastructure and deep operational expertise—face unprecedented pressure. Cloud providers must simultaneously integrate new AI capabilities while preserving their core strengths.
The rapid emergence of third-party orchestration layers is creating a new competitive battleground above individual clouds. This mirrors how over-the-top services disrupted telecom’s business model. Cloud providers that fail to adapt to this new reality risk following the path of telecom giants that were reduced to “dumb pipes” as value moved up the stack.
The Strategic Imperative: Evolution, Not Extinction
Cloud providers face a significant strategic challenge, but not extinction. The way forward requires evolution rather than entrenchment, with four key imperatives that can guide successful adaptation to this changing landscape. These strategies recognize that cloud’s value proposition is evolving rather than disappearing.
Embrace AI-Enhanced Operations
Providers that proactively integrate AI into their operational models gain significant advantages by:
Delivering higher reliability and security at scale
Reducing customer operational friction through intelligent automation
Focusing human expertise on high-value problems rather than routine tasks
Creating self-service experiences that democratize capabilities while maintaining differentiation
The competitive advantage comes not from simply adopting AI tools, but from reimagining operations with intelligence embedded throughout the stack—transforming how services are delivered, monitored, and optimized.
Lead the Multi-Cloud Transition
Rather than resisting multi-cloud adoption, forward-thinking providers are positioning themselves to lead this transition by:
Creating their own cross-cloud management capabilities
Optimizing for specific workloads where they excel
Developing migration paths that make them the preferred destination for critical workloads
Building partnership ecosystems that enhance their position in multi-cloud environments
The goal is becoming the strategic foundation within a multi-cloud strategy, rather than fighting against the inevitable trend toward workload distribution and portability.
Invest in Infrastructure Differentiation
Physical infrastructure remains a durable advantage when strategically positioned. Differentiation opportunities include:
Specialization for emerging workloads like AI
Optimization for performance characteristics that matter to key customer segments
Strategic positioning to address sovereignty and compliance requirements
Energy efficiency design in an increasingly carbon-conscious market
Architecture to support real-time processing demands of robotics and autonomous systems
Ultra-low latency capabilities for mission-critical applications
Infrastructure isn’t becoming irrelevant—it’s becoming more specialized, with different characteristics valued by different customer segments.
Develop Ecosystem Stickiness
Beyond technical lock-in, providers can build lasting relationships through ecosystem investments:
Developer communities that foster innovation and knowledge sharing
Education and certification programs that develop expertise
Partner networks that create business value beyond technical capabilities
Industry-specific solutions that address complete business problems
This ecosystem approach recognizes that relationships and knowledge investments often create stronger bonds than technical dependencies alone, leading to more sustainable competitive advantages over time.
The Path Forward: Three Strategic Options
Cloud providers have three strategic options to avoid the telecom commoditization trap as I see it right now:
Vertical integration into industry-specific solutions that combine infrastructure, expertise, and deep industry knowledge in ways difficult to commoditize. This approach focuses on value creation through specialized understanding of regulated industries like healthcare, finance, and government.
Specialization in emerging complexity areas where operational challenges remain high and AI assistance is still developing. These include domains like quantum computing, advanced AI training infrastructure, and specialized hardware acceleration that resist commoditization through continuous innovation.
Embracing the orchestration layer by shifting focus from infrastructure to becoming the universal fabric that connects and secures all computing environments. Rather than fighting the abstraction trend, this strategy positions providers at the center of the multi-cloud ecosystem.
Conclusion
Cloud providers face a clear choice, continue investing solely in operational excellence that is gradually being democratized by AI, or evolve their value proposition to emphasize their enduring advantages while embracing the changing operational landscape.
For cloud customers, the message is equally clear: while infrastructure remains critical, the flexibility to leverage multiple providers through AI-powered operations creates new strategic options. Organizations that build intelligence-enhanced operational capabilities now will gain unprecedented flexibility while potentially reducing costs and improving reliability.
The pattern differs meaningfully from telecom. While telecommunications became true commodities with minimal differentiation, cloud infrastructure maintains significant differentiation potential through performance characteristics, geographic distribution, specialized capabilities, and ecosystem value. The challenge for providers is to emphasize these differences while adapting to a world where operational expertise becomes more widely distributed through AI.
The time to embrace this transition isn’t in some distant future—it’s now. Over the next 5-10 years, the providers who recognize these shifts early and adapt their strategies accordingly will maintain leadership positions, while those who resist may find their advantages gradually eroding as customers gain more options through AI-enhanced operations.
The evolution toward AI-enhanced operations isn’t just another technology trend—it’s a significant shift in how cloud value is created and captured. The providers who understand this transformation will be best positioned to thrive in the next phase of cloud’s rapid evolution.
When selling security solutions to enterprises, understanding who makes purchasing decisions is critical to success. Too often, security vendors aim their messaging at the wrong audience or fail to recognize how budget authority flows in organizations. This post tries to break down the essential framework for understanding enterprise security buyer dynamics.
While this framework provides a general structure for enterprise security sales, industry-specific considerations require adaptation. Regulated industries like healthcare, finance, and government have unique compliance requirements, longer approval cycles, and additional stakeholders (e.g., legal, risk committees).
The Buyer Hierarchy
The first key concept to understand is the buyer hierarchy in enterprise security.
Figure 1: The Buyer Hierarchy
This pyramid structure represents who typically makes purchasing decisions at different price points:
At the base of the pyramid are Security and IT Managers. These individuals make most purchase decisions, particularly for:
Standard solutions with established budget lines
Renewals of existing products
Smaller ticket items
Solutions addressing immediate operational needs
Moving up the pyramid, we find Security and IT Directors who typically approve:
Larger deals requiring more significant investment
In security sales, it’s crucial to distinguish between two key players:
The Champion: This person is chartered to solve the problem. They’re typically your main point of contact and technical evaluator – often a security engineer, DevOps lead, or IT admin. They’ll advocate for your solution but rarely control the budget.
The Buyer: This is the person who owns the budget. Depending on the size of the deal, this could be a manager, director, or in some cases, the CISO. They make the final purchasing decision.
Understanding this dynamic is critical. Too many sales efforts fail because they convinced the champion but never engaged the actual buyer.
The Budget Factor
Another critical dimension is whether your solution is:
Pre-budgeted: Already planned and allocated in the current fiscal year
Unbudgeted: Requires new budget allocation or reallocation from other initiatives
Figure 2: Budgetary Timing Diagram
This distinction dramatically impacts who needs to approve the purchase. Unbudgeted items almost always require higher-level approval – typically at the CISO level for any significant expenditure, as they have the authority to reallocate funds or tap into contingency budgets.
The Cross-Organizational Challenge
A critical dimension often overlooked in enterprise security sales is cross-organizational dynamics.
When security purchases span multiple departments (e.g., budget from Compliance, implementation by Engineering), the buyer hierarchy becomes more complex. Moving funds between departmental budgets often requires executive approval above the standard buyer level.
Different departments operate with separate success metrics, priorities, and approval chains. What solves one team’s problems may create work for another with no benefit to their goals. These cross-organizational deals typically extend sales cycles by 30-50%.
For vendors navigating these scenarios, success depends on mapping all stakeholders across departments, creating targeted value propositions for each group, and sometimes elevating deals to executives who can resolve cross-departmental conflicts.
The Cost of Sale Framework
As solutions become more enterprise-focused, the cost of sale increases dramatically.
Figure 3: Cost of Sale Diagram
This framework illustrates a critical principle: The cost of sale must be aligned with the buyer level.
For solutions with a higher cost of sale (requiring more sales personnel time, longer sales cycles, more supporting resources), vendors must sell higher in the organization to ensure deal sizes justify these costs.
Key components affecting cost of sale include:
Sales personnel salary
Number of accounts per sales rep
Sales cycle length
Supporting resources required
This explains why enterprise security vendors selling complex solutions must target the CISO budget – it’s the only way to recoup their significant cost of sale.
Relationship Dynamics and Timing Considerations
While understanding the buyer hierarchy is essential, most successful enterprise security deals don’t happen solely through identifying the right level in an organization.
Figure 4: Cost of Sale Diagram
Two critical factors often determine success:
Relationship Development: Successful sales rarely happen in a transactional manner. They require:
Building trust through consistent value delivery before the sale
Understanding the internal politics and relationships between champions and buyers
Developing multiple organizational touchpoints beyond just the champion
Recognizing the personal career motivations of both champions and buyers
Timing Alignment: Even perfect solutions fail when timing is wrong:
Budget cycle alignment is critical – engage 3-6 months before annual planning
Crisis or incident response periods can accelerate purchases or freeze them
Organizational changes (new leadership, restructuring) create both opportunities and risks
Regulatory deadlines often drive urgent security investments
The most effective security vendors don’t just target the right level in the hierarchy – they strategically time their engagements and invest in relationship development that transcends organizational charts.
Practical Application
For security vendors, this framework provides practical guidance:
Know your buyer level: Based on your solution’s price point and complexity, identify your primary buyer persona (Manager, Director, or CISO)
Target champions appropriately: Ensure your technical messaging resonates with the people who will evaluate and champion your solution
Align marketing to both: Create distinct messaging for champions (technical value) and buyers (business value)
Understand the budget cycle: Time your sales efforts to align with budget planning for better success with larger deals
Match sales approach to cost structure: Ensure your go-to-market approach and resources match your cost of sale
By aligning your sales and marketing efforts with these buyer dynamics, you’ll significantly improve your efficiency and close rates in the enterprise security market.
Ever been in a meeting where someone drops terms like “TEE,” “TPM,” or “FIPS-certified” and everyone nods along, pretending they understand? Yeah, me too.
“Some discussions would be so much easier if people knew the definitions of ‘TEE’, ‘TPM’, ‘Secure element’, ‘Secure enclave’, ‘HSM’, ‘Trusted computing’, ‘FIPS(140-2/3)-certified’, ‘Common criteria’, ‘security target’, etc. Plus now the marketing-oriented term ‘confidential computing’ is used to mean a variety of things with varying security properties.”
He’s right – the security tech space is a mess of overlapping terms, marketing buzzwords, and genuine technical concepts. So I threw together a guide to sort this stuff out.
What’s Actually Different Between These Things?
At their core, these technologies do three things:
Minimize what code you need to trust (the TCB)
Create isolation between different parts of a system
Establish trust across different machines
A TPM is not the same as a TEE. Intel SGX is not identical to AMD SEV. And no, slapping “FIPS-certified” on your product doesn’t automatically make it secure.
The Real-World Impact
When your vendor says they use “Confidential Computing,” do you know what that actually means for your data? Could be anything from “your data is encrypted in memory” to “we’ve got a fancy marketing term for standard virtualization.”
The differences matter. A secure element in your phone has around 10-50KB of trusted code. A standard Linux kernel? About 27.8 MILLION lines. One of these is much easier to secure than the other.
When Things Break
Even the most certified security tech fails. Hardware Security Modules (HSMs) with FIPS 140-2 certification—supposedly the gold standard for cryptographic security—have been compromised by design flaws. Look at the 2015 Safenet HSM vulnerability where API flaws in the PKCS#11 interface allowed full key extraction. Attackers with authenticated access could exploit weak key derivation mechanisms to extract the very keys the HSM was designed to protect.
Bottom line: No security technology is perfect. Each has its place, limitations, and potential failure modes.
As Winston Churchill observed, “He who fails to plan is planning to fail.” Understanding what’s under the hood of these technologies isn’t just academic—it’s essential for building systems that can actually withstand the threats they’ll face.
The evolution of technology operations has always been driven by necessity. From the early days of single system operators (sysops) managing physical servers through hands-on intervention, to today’s complex landscape of distributed microservices, containers, and serverless functions, each operational paradigm shift has emerged to address growing complexity.
The Journey of Operational Evolution
From the hands-on Sysops era of the 1960s-80s when operators physically managed as as little as few to 10s of servers each, to the System Administration period of the 1990s when centralized tools expanded reach to hundreds of systems, technology operations have continuously transformed. DevOps emerged in the mid-2000s, leveraging Infrastructure as Code to manage thousands of systems, followed by SRE practices in the 2010s with error budgets and self-healing systems handling tens of thousands of containers. Looking ahead to 2025, AI-Driven Operations promises autonomous management of millions of components.
Each transition has been driven by necessity – not choice – as technology’s relentless complexity has overwhelmed previous operational models.
The Machine Concept Has Transformed
What’s particularly interesting is how we use the word “machine” has changed dramatically. In the early days, machines were physical servers with stable operating systems and predictable maintenance schedules. Today, with serverless computing, the very concept of a server has become fluid – functions materialize only when triggered, often lasting mere seconds before vanishing.
This ephemeral nature of modern computing creates unprecedented coordination challenges that exceed manual and even moderate automation approaches to management.
The Limits of Current Approaches
Even advanced DevOps and SRE practices are struggling with the scale and complexity of today’s systems. Many vendors have responded by adding AI or ML features to their products, but these “bolt-on” enhancements only provide incremental benefits – analyzing logs, detecting anomalies, or generating suggestions for known issues.
What’s needed is a more fundamental reimagining of operations, similar to how cloud-native architectures transformed infrastructure beyond simple virtualization.
AI-Native: A New Operational Paradigm
An AI-native platform isn’t just software that applies ML algorithms to operational data. It’s a new foundation where intelligence is deeply integrated into orchestration, observability, security, and compliance layers.
In these systems:
Instrumentation is dynamic and context-aware
Security is adaptive, learning normal communication patterns and immediately flagging and in even some cases quarantining anomalous processes
Compliance shifts from periodic audits to continuous enforcement
The timeline above illustrates how each operational era has enabled engineers to manage exponentially more systems as complexity has grown.
This diagram shows the widening gap between human management capacity and system complexity, which AI-native operations will ultimatley address.
The Human Role Transforms, Not Disappears
Rather than eliminating jobs, AI-native operations redefine how engineers spend their time. As a result, we will ultimately see the concept “force multiplier engineers” who will build advanced AI-driven frameworks that amplify the productivity of all other developers.
Freed from repetitive tasks like scaling, patching, and log parsing, these professionals can focus on innovation, architecture, and strategic risk management.
The Inevitable Shift
This transition isn’t optional but inevitable. As systems become more fragmented, ephemeral, and globally distributed, conventional approaches simply can’t keep pace with the complexity.
Those who embrace AI-native operations early will gain significant advantages in reliability, security, cost-efficiency, and talent utilization. Those who hesitate risk being overwhelmed by complexity that grows faster than their capacity to manage it.
What do you think about the future of AI in operations? Are you seeing early signs of this transition in your organization? Let me know in the comments!
Imagine yourself as a pilot at 30,000 feet when an engine begins to sputter. You don’t panic—your training activates, you follow your checklist, and take control. For Certificate Authorities (CAs), incidents like misissued certificates or security breaches create similar high-stakes scenarios. They’re unexpected, critical, and unforgiving. Preparation isn’t just advisable—it’s essential. In the Web PKI world, where trust is paramount, improvisation isn’t an option.
These high-stakes scenarios aren’t rare exceptions—browser distrust events occur approximately every 1.23 years. Since 2011, over a dozen CAs have been distrusted, with poor incident response handling featuring prominently among the causes. These aren’t just statistics; they represent existential threats to CAs and the trust system underpinning secure internet communication.
Mozilla’s new CA Incident Response Requirements policy addresses a history of delayed responses, insufficient analyses, and unclear communication that has plagued the ecosystem. By incorporating Site Reliability Engineering (SRE) concepts, CAs can transform incidents into opportunities to strengthen resilience. Let’s examine the new policy, take a quick look SRE concepts and how they enhance it, and analyze real-world examples from Let’s Encrypt and DigiCert to illustrate best practices—and pitfalls to avoid.
Why the Mozilla Policy Matters: Trust at Stake
Incidents are inevitable. Whether a certificate misissuance, system failure, or security exploit, these events represent critical moments for CAs. Losing browser trust, as DigiNotar did in 2011 or Symantec by 2017, is catastrophic. One moment, you’re essential to Web PKI; the next, you’re a cautionary tale.
The evidence is clear: since 2011, CAs have experienced over 10 major incidents—averaging one every 14 months. More than half—over 57%—of these distrusts stem at least in part from delayed or mishandled responses, not just the incidents themselves. Each costs trust, revenue, or both (as DigiNotar’s bankruptcy demonstrated). The pattern reveals that your response defines you more than the incident itself. A prepared CA can recover and even strengthen its reputation. An unprepared one faces severe consequences.
Mozilla’s policy addresses the cycle of late notifications and superficial fixes that have damaged CAs previously. Structured timelines ensure transparency and accountability—essential elements for maintaining trust.
2025 Policy: Your Incident Response Framework
The new Common Incident Reporting Guidelines (effective March 2025) establish a the following framework for incident handling:
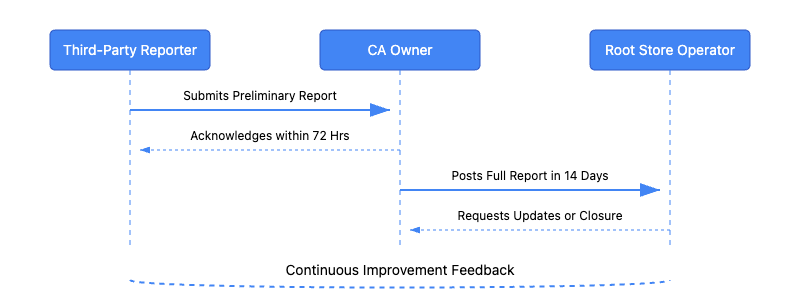
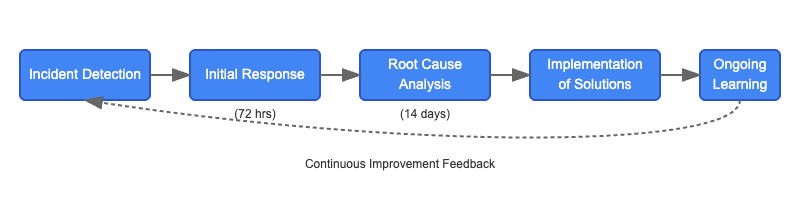
72-Hour Initial Disclosure: Three days to publicly acknowledge the issue, outline initial actions, and assess scope of impact.
14-Day Full Report: Two weeks to deliver a standardized, comprehensive Root Cause Analysis (RCA), detailed timeline, and prevention plan.
These aren’t just arbitrary deadlines—they’re designed to break the pattern of delays and ambiguity that has undermined trust in the WebPKI ecosystem. The policy establishes specific templates, report formats, and update requirements that formalize the approaches already taken by the most resilient CAs.
The requirements emphasize “candid, timely, and transparent” reporting—values that separate successful incident responses from catastrophic ones. What’s more, reports must demonstrate “a detailed understanding of root causes” and “clear, measurable explanations” of remediation actions.
The incident lifecycle follows this structure:
SRE: The Enhancement for Resilience
Mozilla provides structure, but Site Reliability Engineering (SRE)—pioneered by Google—offers tools that elevate your response. Two SRE concepts align perfectly with Mozilla’s requirements:
Automation: SRE emphasizes automating repetitive tasks. For the 72-hour disclosure, automated monitoring can identify issues immediately, while scripts—such as certificate revocation tools—activate without delay. Speed becomes your advantage.
Blameless Postmortems: The 14-day RCA isn’t about assigning blame—it’s about learning. SRE’s blameless approach investigates what failed and how to improve, converting every incident into a growth opportunity.
Automation in this case might look like this:
Together, Mozilla’s timelines and SRE’s methodologies establish a framework that’s proactive rather than reactive.
Case Studies: Preparation Demonstrated
Let’s Encrypt: Prepared When It Mattered
In 2020, Let’s Encrypt encountered a bug in their domain validation logic. Their response exemplified best practices:
Early Detection: Proactive monitoring and periodic reviews identified the issue quickly, before external parties did.
Automation in Action: They revoked 1.7 million certificates within hours due to their readiness.
Data-Driven Decisions: They were able to immediately identify which certificates had been replaced versus which were still in active use.
Transparent Communication: Regular updates and a thorough postmortem kept stakeholders informed.
Strategic Delayed Revocation: For certificates that couldn’t be immediately revoked without major disruption, they filed a separate delayed revocation incident with clear timelines.
They met CCADB’s deadlines with margin to spare and emerged stronger. Their preparation proved invaluable—and it was no coincidence. Their systems were designed from day one to handle such scenarios, with automation built into their core operations.
DigiCert: Caught Unprepared
DigiCert’s misissuance incident tells a contrasting story. An external party discovered the problem, and their response faltered:
Manual Processes: Without automation, revocations progressed slowly and required customer intervention.
Insufficient Planning: They struggled, facing subscriber resistance and legal complications, including a Temporary Restraining Order (TRO) from a customer.
Reactive Decision-Making: They initially announced a 24-hour revocation window, then extended it to 5 days as complications mounted.
Customer Impact: They did not know how many of their customers were ready to rotations, and so they had to treat everyone the same, amplifying disruption.
Design Issues: The initial fix appeared to be applied at the user interface level rather than addressing the core validation system—suggesting insufficient engineering practices.
Commercial CAs might argue their enterprise model makes automation harder than Let’s Encrypt’s, but complex customer relationships actually make preparation more critical, not less. The TRO demonstrates how business constraints amplify—rather than excuse—the need for rigorous incident readiness.
The contrast is instructive. Let’s Encrypt’s readiness maintained stability; DigiCert’s lack of preparation created vulnerability and legal complications that set a concerning precedent for the industry.
Implementing the New CCADB Requirements
To meet the new CCADB incident reporting requirements effectively, CAs should implement these eight critical capabilities:
Create Templated Response Plans: Develop standardized report templates aligned with CCADB’s new formats, with designated owners for each section.
Establish Monitoring Triggers: Implement automated monitoring that can identify potential incidents early and trigger response workflows.
Build Certificate Inventory Systems: Maintain comprehensive real-time data about certificate status, usage, and replacement to enable rapid impact assessment.
Create Tiered Revocation Capabilities: Implement automation for certificates with lifecycle management while maintaining processes for manual customers.”
Prepare customers and technology: Implement back-end changes, and work with customers to adopt systems that have been designed to meet these requirements.
Develop Blameless Postmortem Processes: Create structured processes for conducting Root Cause Analysis using methodologies like “5 Whys” and Fishbone Diagrams.
Create Revocation Automation: Implement systems to quickly revoke certificates in bulk with minimal manual intervention.
Align Legal Agreements: Ensure contracts include provisions for certificate revocations and incident response cooperation.
Test Incident Response Regularly: Conduct simulations of different incident types to ensure teams can meet the required reporting deadlines.
These systems shouldn’t be created during a crisis—they must be built, tested, and refined during normal operations to ensure they function when needed most.
Your Next Steps: Building Resilience
Ready to implement these principles? Follow this straightforward approach:
Create a Response Plan: Define roles, responsibilities, and timelines—your organization’s crisis protocol.
Automate Critical Functions: Implement detection and remediation tools—prioritize speed.
Develop Learning Processes: Conduct blameless postmortems to strengthen systems.
Prioritize Clear Communication: Share updates with stakeholders consistently, even during difficulties.
This isn’t complex—it’s disciplined. And for CAs, discipline is fundamental.
Preparation Is Essential
Incidents occur without warning. With a robust plan, automation, a learning orientation, and transparent communication, you can manage them effectively. Mozilla’s policy and Google’s SRE practices provide both structure and methodology to succeed. Let’s Encrypt demonstrated its effectiveness; DigiCert illustrated its necessity.
Don’t wait for an incident to expose weaknesses in your process. Preparation isn’t optional—it’s how you transform a crisis into an opportunity to demonstrate excellence. Plan systematically, automate intelligently, learn continuously, and you’ll build a CA that doesn’t merely survive but thrives.
Want to learn more? Mastering Incident Reporting in the WebPKI class covers mistakes and misconceptions: slides can be found here
I’ve been involved in the Web PKI since the mid-‘90s, when SSL certificates carried five- or ten-year lifetimes—long-lasting credentials for an internet still a wild west. Issuance was manual, threats were sparse, and long validity fit that quieter era. Thirty years later, we’ve fought our way to a 398-day maximum lifetime—today’s standard as of 2025—thanks in part to Apple’s bold 2020 move to enforce 398-day certificates in Safari, dragging resistant CAs into a shared ballot after years of clinging to the status quo. Yet some certificate authorities, certificate consumers, and industry holdouts still resist shorter lifetimes and tighter data reuse policies, offloading breaches, increased risk, and eroded trust onto users, businesses, and the web’s backbone. This 15-year struggle got us to 398; now it’s time to push past it.
Core Argument
The journey to shorter lifetimes spans decades. The TLS Baseline Requirements set a 60-month cap in 2010, but by 2014, internal debates among browsers and CAs ignited over whether such spans were safe as threats ballooned. Progress stalled—pushback was fierce—until Apple threw a wrench in the works. Announced earlier in 2020, effective September 2020, they declared Safari would reject certificates issued after August 31, 2020, with lifetimes exceeding 398 days, blindsiding CAs who’d dug in their heels. Only after that jolt did the CA/Browser Forum pass Ballot SC-42 in 2021, codifying 398 days as a shared requirement—proof that CAs wouldn’t budge without external force. Earlier, Ballot 185 in 2017 had proposed cutting lifetimes to 27 months, Ballot SC-22 in 2019 explored short-lived certificates, and Ballot SC-081 in 2025 is expected to reaffirm 398 days as the maximum, with a long-term target of 45–47 days by 2029 (SC-081v2). That’s 15 years of incremental progress, built on 30 years of evolution—Last time Apple’s push broke CA inertia enough to land us at 398, and I am confident without that action we would not be where we are yet. Yet risks like “Bygone SSL” linger: valid certificates staying with old domain owners after a sale, opening doors to impersonation or chaos.
Automation made this possible—and Apple’s 2020 edict accelerated it. Let’s Encrypt launched in November 2014, revolutionizing issuance with free, automated certificates; the ACME protocol, drafted then and standardized as RFC 8555 in 2019, turned renewal into a background hum. Today, CAs split into camps: fully automated players like Let’s Encrypt, Google Trust Services, and Amazon, versus mixed providers like DigiCert, Sectigo, and GlobalSign, who blend proprietary and ACME based automation with manual issuance for some. Data from crt.sh suggests over 90% of certificates now use automated protocols like ACME. Apple’s push forced CAs to adapt or lose relevance, yet many clung to old ways, agreeing to 398 only post-ballot. That lag—resisting automation and shorter spans—doesn’t just slow progress; it externalizes risk, burdening the WebPKI with overstretched certificates and outdated practices.
What Problem Are We Solving Anyway?
Well for one certificates are snapshots of a domain’s status at issuance; that 13-month span lets changes—like ownership shifts or domain compromises—linger unreflected, while 45 days would keep them current, shrinking an attacker’s window from over a year to mere weeks. “Bygone SSL” proves the point: when domains change hands, old owners can hang onto valid certificates—sometimes for years—letting them spoof the new owner or, with multi-domain certs, trigger revocations that disrupt others. History teaches us that reusing stale validation data—sometimes months old—leads to misissuance, where certificates get issued on outdated or hijacked grounds. Tighter allowed reuse periods force regular revalidation, but when CAs or companies slack, the ecosystem bears the cost: spoofed domains impersonating legit sites, breaches exposing sensitive data, and a trust system strained by systemic hits.
Browsers show us the way—back in the ‘90s, updates came on floppy disks on magazine covers, a manual slog that left users exposed until the next trip to the store; today, automatic updates roll out silently, patching holes and keeping security tight without a fuss. Certificates should mirror that: automated renewal via ACME or proprietary tools manages 398 days now and could handle 45 effortlessly, shedding the old manual grind—an incremental evolution already underway. Yet some cling to slower cycles, offloading risk—leaving the WebPKI vulnerable to their refusal to fully embrace automation’s promise. The proof’s in the pudding—Kerberos rotates 10-hour tickets daily in enterprise networks without a hitch; ACME brings that scalability to the web. Legacy systems? Centralized solutions like reverse proxies, certificate management platforms, or off-device automation bridge the gap—technical excuses don’t hold.
We’ve hit 398 days, but Zeno’s Dichotomy still grips us: advocates push for shortening, hit “not ready,” and stall at the current max—halving the gap to robust security without ever closing it. Each delay lets inertia shift risk onto the system.
Critics’ Refrain
Critics cling to familiar objections. “Legacy systems can’t handle frequent renewals”? Centralized automation—proxies, management tools, off-device solutions—proves otherwise; their inertia spills risk onto the ecosystem. “Smaller players face a competitive burden,” implying the web should shoulder that risk? Shared tools and phased transitions even the odds, yet their lag, like SHA-1’s slow death, threatens everyone. “Why not focus on revocation, DNSSEC, or key management instead”? Revocation’s a pipe dream—three decades of flops, from CRLs to OCSP, show it crumbling at scale, with privacy holes, performance drags, and spotty enforcement, as DigiNotar’s failure left unpatched clients exposed. DNSSEC and key management complement, not replace—shorter lifetimes cut exposure fast, while those build out. “It’s too rapid”? Two decades of automation—from proprietary solutions to ACME—and 15 years of debate say no; 398 days took effort, 45–47 is next. “We’re not ready”? That’s an impossible hurdle—security leaps like SHA-2 to TLS 1.3 came by diving in, not waiting, just as parents figure out diapers post-birth. Stalling at 398 doesn’t shield risk—it dumps it on the rest.
Pushing Beyond 398 Delivers Concrete Gains When Inertia’s Beaten:
Benefit
Description
Enhanced Trustworthyness
Frequent renewals keep data current, cutting misissuance—laggards can’t dump stale risks on the WebPKI.
Shorter Exploitation Window
45 days caps attacks at weeks, not 398 days—orgs can’t offload longer threats.
Lower Misissuance Risk
Tight reuse forces fresh checks, slashing errors CAs push onto the system.
Rapid Policy Transition
Quick shifts to new standards dodge inertia’s drag, keeping the PKI sharp.
Stronger Baselines
90%+ automated renewals set a secure norm—holdouts can’t undermine it.
Collective Accountability
Deadlines force modernization, ending the pass where a few’s inaction risks all.
Conclusion
Shorter lifetimes and tighter reuse periods—break the cycle: fresh data, capped risk, no more offloading. A phased, deadline-driven approach, like SC-081’s framework (targeting shorter spans by 2029 in SC-081v2), forces the industry to adapt, hones automation where needed, and drives security forward—waiting five more years just fattens the risks we’ve already outgrown.
How does inertia externalize risk in the WebPKI? When CAs lean on stale data, companies settle for 398 days, and stragglers resist progress, they turn trust into a punching bag—ripe for abuse. Thirty years in, with 398 days locked and over 90% automated, the tools sit ready—only will falters.
Zeno’s half-steps got us here, but “not ready” is a fantasy—no one masters security before the plunge, just as parents don’t ace diapers pre-birth; we’ve evolved through every shift this way. Browsers don’t wait for floppy disks anymore—certificates can’t linger on yesterday’s pace either. I’ve watched the WebPKI battle from the Wild West to now—let’s rip inertia’s grip off with deadlines that stick and lock in 45 days to forge a trust that outlasts the past’s failures.
Security used to be something we tried to bolt on to inherently insecure systems. In the 1990s, many believed that if we simply patched enough holes and set up enough firewalls, we could protect almost anything. Today, hard-won experience has shown that secure-by-design is the only sustainable path forward. Rather than treating security as an afterthought, we need to bake it into a system’s very foundation—from its initial design to its day-to-day operation.
Yet even the best security technology can fail to catch on if no one understands its value. In my time in the field I’ve seen a recurring theme: great solutions often falter because they aren’t communicated effectively to the right audiences. Whether you’re a security entrepreneur, an in-house security architect, or part of a larger development team, you’ll likely need to equip three distinct groups with the right messaging: the Technical Champion, the Economic Buyer, and the Broader Market. If any of them fail to see why—and how—your solution matters, momentum stalls.
From Bolt-On to Secure-by-Design
The security industry has undergone a massive shift, moving away from the idea that you can simply bolt on protection to an already flawed system. Instead, we now realize that security must be designed in from the start. This demands a lifecycle approach—it’s not enough to fix bugs after deployment or put a facade in front of a service. We have to consider how software is built, tested, deployed, and maintained over time.
This evolution requires cultural change: security can’t just live in a silo; it has to be woven into product development, operations, and even business strategy. Perhaps most importantly, we’ve learned that people, processes, and communication strategies are just as important as technology choices.
This shift has raised the bar. It’s no longer sufficient to show that your solution works; you must show how it seamlessly integrates into existing workflows, consider the entire use lifecycle, supports future needs, and gets buy-in across multiple levels of an organization.
The Three Audiences You Need to Win Over
The Technical Champion (80% Tech / 20% Business)
Your security solution will often catch the eye of a deeply technical person first. This might be a security engineer who’s tired of patching the same vulnerabilities or a software architect who sees design flaws that keep repeating. They’re your first and most crucial ally.
Technical champions need more than promises—they need proof. They want detailed demos showing real-world scenarios, sample configurations they can experiment with, and pilot environments where they can test thoroughly. Give them architecture diagrams that satisfy their technical depth, comprehensive documentation that anticipates their questions, and a clear roadmap showing how you’ll address emerging threats and scale for future needs.
Integration concerns keep champions awake at night. They need to understand exactly how your solution will mesh with existing systems, what the deployment strategy looks like, and who owns responsibility for updates and patches. Address their concerns about learning curves head-on with clear documentation and practical migration paths.
While technology drives their interest, champions eventually have to justify their choices to management. Give them a concise one-pager that frames the returns in business terms: reduced incident response time, prevented security gaps, and automated fixes that save precious engineer hours.
Why This Matters: When you equip your champion with the right resources, they become heroes inside their organizations. They’re the one who discovered that crucial solution before a major breach, who saved the team countless hours of manual work, who saw the strategic threat before anyone else. That kind of impact directly translates to recognition, promotions, and career advancement. The champion who successfully implements a game-changing security solution often becomes the go-to expert, earning both peer respect and management attention. When you help a champion shine like this, they’ll pull your solution along with them as they climb the organizational ladder.
The Economic Buyer (20% Tech / 80% Business)
A passionate champion isn’t always the one holding the purse strings. Often, budget is controlled by directors, VPs, or executives who juggle competing priorities and are measured by overall business outcomes, not technical elegance.
Your buyer needs a concise, compelling story about how this investment reduces risk, saves costs, or positions the company advantageously. Frame everything in terms of bottom-line impact: quantifiable labor hours saved, reduced compliance burdens, and concrete return on investment timelines.
Even without extensive case studies, you can build confidence through hypothetical or pilot data. Paint a clear picture: “Similar environments have seen 30% reduction in incident response time” or “Based on initial testing, we project 40% fewer false positives.” Consider proposing a small pilot or staged rollout—once they see quick wins scaling up becomes an easier sell.
Why This Matters: When buyers successfully champion a security solution, they transform from budget gatekeepers into strategic leaders in the eyes of executive management. They become known as the one who not only protected the company but showed real business vision. This reputation for combining security insight with business acumen often fast-tracks their career progression. A buyer who can consistently tell compelling business stories—especially about transformative security investments—quickly gets noticed by the C-suite. By helping them achieve these wins, you’re not just securing a deal; you’re empowering their journey to higher organizational levels. And as they advance, they’ll bring your solution with them to every new role and company they touch.
The Broader Market: Present, Teach, and Farm
While winning over individual champions and buyers is crucial, certain security approaches need industry-wide acceptance to truly succeed. Think of encryption standards, identity protocols, and AI based security research tools—these changed the world only after enough people, in multiple communities, embraced them.
Build visibility through consistent conference presentations, industry webinars, and local security meetups. Even with novel technologies, walking people through hypothetical deployments or pilot results builds confidence. Panels and Q&A sessions demonstrate your openness to tough questions and deep understanding of the problems you’re solving.
Make your message easy to spread and digest. While detailed whitepapers have their place, supplement them with short video demonstrations, clear infographics, and focused blog posts that capture your solution’s essence quickly. Sometimes a two-minute video demonstration or one-page technical overview sparks more interest than an extensive document.
Think of education as planting seeds—not every seed sprouts immediately, but consistent knowledge sharing shapes how an entire field thinks about security over time. Engage thoughtfully on social media, address skepticism head-on, and highlight relevant use cases that resonate with industry trends. Consider aligning with open-source projects, industry consortiums, or standards bodies to amplify your reach.
Why This Matters: By consistently educating and contributing to the community dialogue, you create opportunities for everyone involved to shine. Your champions become recognized thought leaders, speaking at major conferences about their successful implementations. Your buyers get profiled in industry publications for their strategic vision. Your early adopters become the experts everyone else consults. This creates a powerful feedback loop where community advocacy not only drives adoption but establishes reputations and advances careers. The security professionals who help establish new industry norms often find themselves leading the next wave of innovation—and they remember who helped them get there.
Overcoming Common Challenges
The “Not Invented Here” Mindset
Security professionals excel at finding flaws, tearing down systems, and building their own solutions. While this breaker mindset is valuable for discovering vulnerabilities, it can lead to the “Not Invented Here” syndrome: a belief that external solutions can’t possibly be as good as something built in-house.
The key is acknowledging and respecting this culture. Offer ways for teams to test, audit, or customize your solution so it doesn’t feel like an opaque black box. Show them how your dedicated support, updates, and roadmap maintenance can actually free their talent to focus on unique, high-value problems instead of maintaining yet another in-house tool.
Position yourself as a partner rather than a replacement. Your goal isn’t to diminish their expertise—it’s to provide specialized capabilities that complement their strengths. When teams see how your solution lets them focus on strategic priorities instead of routine maintenance, resistance often transforms into enthusiasm.
The Platform vs. Product Dilemma
A common pitfall in security (and tech in general) is trying to build a comprehensive platform before solving a single, specific problem. While platforms can be powerful, they require critical mass and broad ecosystem support to succeed. Many promising solutions have faltered by trying to do too much too soon.
Instead, focus on addressing one pressing need exceptionally well. This approach lets you deliver value quickly and build credibility through concrete wins. Once you’ve proven your worth in a specific area, you can naturally expand into adjacent problems. You might have a grand vision for a security platform, but keep your initial messaging focused on immediate, tangible benefits.
Navigating Cross-Organizational Dependencies
Cross-team dynamics can derail implementations in two common ways: operational questions like “Who will manage the database?” and adoption misalignment where one team (like Compliance) holds the budget while another (like Engineering) must use the solution. Either can stall deals for months.
Design your proof of value (POV) deployments to minimize cross-team dependencies. The faster a champion can demonstrate value without requiring multiple department sign-offs, the better. Start small within a single team’s control, then scale across organizational boundaries as value is proven.
Understand ownership boundaries early: Who handles infrastructure? Deployment? Access control? Incident response? What security and operational checklists must be met for production? Help your champion map these responsibilities to speed implementation and navigate political waters.
The Timing and Budget Challenge
Success often depends on engaging at the right time in the organization’s budgeting cycle. Either align with existing budget line items or engage early enough to help secure new ones through education. Otherwise, your champion may be stuck trying to spend someone else’s budget—a path that rarely succeeds. Remember that budget processes in large organizations can take 6-12 months, so timing your engagement is crucial.
The Production Readiness Gap
A signed deal isn’t the finish line—it’s where the real work begins. Without successful production deployment, you won’t get renewals and often can’t recognize revenue. Know your readiness for the scale requirements of target customers before engaging deeply in sales.
Be honest about your production readiness. Can you handle their volume? Meet their SLAs? Support their compliance requirements? Have you tested at similar scale? If not, you risk burning valuable market trust and champion relationships. Sometimes the best strategy is declining opportunities until you’re truly ready for that tier of customer.
Having a clear path from POV to production is critical. Document your readiness criteria, reference architectures, and scaling capabilities. Help champions understand and navigate the journey from pilot to full deployment. Remember: a successful small customer in production is often more valuable than a large customer stuck in pilot or never deploys into production and does not renew.
Overcoming Entrenched Solutions
One of the toughest challenges isn’t technical—it’s navigating around those whose roles are built on maintaining the status quo. Even when existing solutions have clear gaps (like secrets being unprotected 99% of their lifecycle), the facts often don’t matter because someone’s job security depends on not acknowledging them.
This requires a careful balance. Rather than directly challenging the current approach, focus on complementing and expanding their security coverage. Position your solution as helping them achieve their broader mission of protecting the organization, not replacing their existing responsibilities. Show how they can evolve their role alongside your solution, becoming the champion of a more comprehensive security strategy rather than just maintaining the current tools.
Putting It All Together
After three decades in security, one insight stands out: success depends as much on communication as on code. You might have the most innovative approach, the sleekest dashboard, or a bulletproof protocol—but if nobody can articulate its value to decision-makers and colleagues, it might remain stuck at the proof-of-concept stage or sitting on a shelf.
Your technical champion needs robust materials and sufficient business context to advocate internally. Your economic buyer needs clear, ROI-focused narratives supported by concrete outcomes. And the broader market needs consistent education through various channels to understand and embrace new approaches.
Stay mindful of cultural barriers like “Not Invented Here” and resist the urge to solve everything at once. Focus on practical use cases, maintain consistent messaging across audiences, and show how each stakeholder personally benefits from your solution. This transforms curiosity into momentum, driving not just adoption but industry evolution.
Take a moment to assess your approach: Have you given your champion everything needed to succeed—technical depth, migration guidance, and business context? Does your buyer have a compelling, ROI-focused pitch built on solid data? Are you effectively sharing your story with the broader market through multiple channels?
If you’re missing any of these elements, now is the time to refine your strategy. By engaging these three audiences effectively, addressing cultural barriers directly, and maintaining focus on tangible problems, you’ll help advance security one success story at a time.
Account recovery is where authentication systems go to die. We build sophisticated authentication using FIDO2, WebAuthn, and passkeys, then use “click this email link to reset” when something goes wrong. Or if we are an enterprise, we spend millions staffing help desks to verify identity through caller ID and security questions that barely worked in 2005.
This contradiction runs deep in digital identity. Organizations that require hardware tokens and biometrics for login will happily reset accounts based on a hope and a prayer. These companies that spend fortunes on authentication will rely on “mother’s maiden name” or a text message of a “magic number” for recovery. Increasingly we’ve got bank-vault front doors with screen-door back entrances.
The Government Solution
But there’s an interesting solution emerging from an unexpected place: government identity standards. Not because governments are suddenly great at technology, but because they’ve been quietly solving something harder than technology – how to agree on how to verify identity across borders and jurisdictions.
The European Union is pushing ahead with cross-border digital identity wallets based on their own standards. At the same time, a growing number of U.S. states—early adopters like California, Arizona, Colorado, and Utah—are piloting and implementing mobile driver’s licenses (mDLs). These mDLs aren’t just apps showing a photo ID; they’re essentially virtual smart cards, containing a “certificate” of sorts that is used to attest to certain information about you, similar to what happens with electronic reading of passports and federal CAC cards. Each of these mDL “certificates” are cryptographically traceable back to the issuing authority’s root of trust, creating verifiable chains of who is attesting to these attributes.
One of the companies helping make this happen is SpruceID, a company I advise. They have been doing the heavy lifting to enable governments and commercial agencies to accomplish these scenarios, paving the way for a more robust and secure digital identity ecosystem.
Modern Threats and Solutions
What makes this particularly relevant in 2024 is how it addresses emerging threats. Traditional remote identity verification relies heavily on liveness detection – systems looking at blink patterns, reflections and asking users to turn their heads, or show some other directed motion. But with generative AI advancing rapidly, these methods are becoming increasingly unreliable. Bad actors can now use AI to generate convincing video responses that fool traditional liveness checks. We’re seeing sophisticated attacks that can mimic these patterns the existing systems look at, even the more nuanced subtle facial expressions that once served as reliable markers of human presence.
mDL verification takes a fundamentally different approach. Instead of just checking if a face moves correctly, it verifies cryptographic proofs that link back to government identity infrastructure. Even if an attacker can generate a perfect deepfake video, they can’t forge the cryptographic attestations that come with a legitimate mDL. It’s the difference between checking if someone looks real and verifying they possess cryptographic proof of their identity.
Applications and Implementation
This matters for authentication because it gives us something we’ve never had: a way to reliably verify legal identity during account authentication or recovery that’s backed by the same processes used for official documents. This means that in the future when someone needs to recover account access, they can prove their identity using government-issued credentials that can be cryptographically verified, even in a world where deepfakes are becoming indistinguishable from reality.
The financial sector is already moving on this. Banks are starting to look at how they can integrate mDL verification into their KYC and AML compliance processes. Instead of manual document checks or easily-spoofed video verification, they will be able to use these to verify customer identity against government infrastructure. The same approaches that let customs agents verify passports electronically will now also be used to enable banks to verify customers.
For high-value transactions, this creates new possibilities. When someone signs a major contract, their mDL can be used to create a derived credential based on the attestations from the mDL about their name, age, and other artifacts. This derived credential could be an X.509 certificate binding their legal identity to the signature. This creates a provable link between the signer’s government-verified identity and the document – something that’s been remarkably hard to achieve digitally.
Technical Framework
The exciting thing isn’t the digital ID – they have been around a while – it’s the support for an online presentment protocol. ISO/IEC TS 18013-7 doesn’t just specify how to make digital IDs; it defines how these credentials can be reliably presented and verified online. This is crucial because remote verification has always been the Achilles’ heel of identity systems. How do you know someone isn’t just showing you a video or a photo of a fake ID? The standard addresses these challenges through a combination of cryptographic proofs and real-time challenge-response protocols that are resistant to replay attacks and deep fakes.
Government benefits show another critical use case. Benefits systems face a dual challenge: preventing fraud while ensuring legitimate access. mDL verification lets agencies validate both identity and residency through cryptographically signed government credentials. The same approach that proves your identity for a passport electronically at the TSA can prove your eligibility for benefits online. But unlike physical ID checks or basic document uploads, these verifications are resistant to the kind of sophisticated fraud we’re seeing with AI-generated documents and deepfake videos.
What’s more, major browsers are beginning to implement these standards as a first-class citizen. This means that verification of these digital equivalents of our physical identities will be natively supported by the web, ensuring that online interactions—from logging in to account recovery—are more easier and more secure than ever before.
Privacy and Future Applications
These mDLs have interesting privacy properties too. The standards support selective disclosure – proving you’re over 21 without showing your birth date, or verifying residency without exposing your address. You can’t do that with a physical ID card. More importantly, these privacy features work remotely – you can prove specific attributes about yourself online without exposing unnecessary personal information or risking your entire identity being captured and replayed by attackers.
We’re going to see this play out in sensitive scenarios like estate access. Imagine a case when someone needs to access a deceased partner’s accounts, they can prove their identity and when combined with other documents like marriage certificates and death certificates, they will be able to prove their entitlement to access that bank account without the overhead and complexity they need today. Some day we can even imagine those supporting documents to be in these wallets also, making it even easier.
The Path Forward
While the path from here to there is long and there are a lot of hurdles to get over, we are clearly on a path where this does happen. We will have standardized, government-backed identity verification that works across borders and jurisdictions. Not by replacing existing authentication systems, but by providing them with a stronger foundation for identity verification and recovery and remote identity verification – one that works even as AI makes traditional verification methods increasingly unreliable.
We’re moving from a world of island of identity systems to one with standardized and federated identity infrastructure, built on the same trust frameworks that back our most important physical credentials. And ironically, at least in the US it started with making driver’s licenses digital.