I was doing some work on readying a launch for our integration with mDL authentication into one of our products when I realized I finally had to deal with the patchwork of state support. California? Full program, TSA-approved, Apple Wallet integration. Texas? Absolute silence. Washington state, practically ground zero for tech, somehow has nothing.
At a glance the coverage made no sense until I started thinking deeper. Turns out we accidentally ran the largest identity verification stress test in history, and only some states bothered learning from it.
Between 2020-2023, fraudsters systematically looted $100-135 billion from unemployment systems using the most basic identity theft techniques. The attack vectors were embarrassingly simple: bulk-purchased stolen SSNs from dark web markets, automated claim filing, and email variations that fooled state systems into thinking [email protected] and [email protected] were different people.
What nobody anticipated, this massive failure would become the forcing function for digital identity infrastructure. Here’s the thing about government security. Capability doesn’t drive adoption, pain does. The Real ID Act passed in 2005. Twenty years later, we’re still rolling it out. But lose a few billion to Nigerian fraud rings? Suddenly digital identity becomes a legislative priority.
The correlation is stark:
State
Fraud Losses
mDL Status
California
$20-32.6B
Comprehensive program, Apple/Google integration
Washington
$550-650M
Nothing (bill stalled)
Georgia
$30M+ prosecuted
Robust program, launched 2023
Texas
Under $1B estimated
No program
New York
Around $1-2B
Launched 2025
States that got burned built defenses. States that didn’t, didn’t. This isn’t about technical sophistication. Texas has plenty of that. It’s about the political will created by public humiliation. When your state pays unemployment benefits to death row inmates, legacy approaches to remote identity verification stop being defensible.
Washington is the fascinating outlier. Despite losing over $1 billion and serving as the primary target for international fraud rings, they still have no mDL program. The bill passed the Senate but stalled in the House. This tells us something important: crisis exposure alone isn’t sufficient. You need both the pain and the institutional machinery to respond.
The timeline reveals the classic crisis response pattern. Fraud peaked 2020-2022, states scrambled to respond 2023-2024, then adoption momentum stalled by mid-2024 as crisis memory faded. But notice the uptick in early 2025—that’s Apple and Google entering the game.
In December 2024, Google announced its intent to support web-based digital ID verification. Apple followed with Safari integration in early 2025. By June, Apple’s iOS 26 supported digital IDs in nine states with passport integration. This shifts adoption pressure from crisis-driven (security necessity) to market-driven (user expectation).
When ~30% of Americans live in states with mDL programs and Apple/Google start rolling out wallet integration this year, that creates a different kind of political pressure. Apple Pay wasn’t crisis-driven, but became ubiquitous because users expected it to work everywhere. Digital identity in wallets will create similar pressure. States could rationalize ignoring mDL when it was ‘just’ about fraud prevention. Harder to ignore when constituents start asking why they can’t verify their identity online like people in neighboring states.
We’re about to find out whether market forces can substitute for crisis pressure in driving government innovation. Two scenarios. Consumer expectations create sustainable political pressure, and laggard states respond to constituent demands. Or only crisis-motivated states benefit from Apple/Google integration, creating permanent digital divides.
From a risk perspective, this patchwork creates interesting attack surfaces. Identity verification systems are only as strong as their weakest links. If attackers can forum-shop between states with different verification standards, the whole federation is vulnerable. The unemployment fraud taught us that systems fail catastrophically when overwhelmed.
Digital identity systems face similar scalability challenges. They work great under normal load, but can fail spectacularly during a crisis. The states building mDL infrastructure now are essentially hardening their systems against the next attack.
If you’re building anything that depends on identity verification, this matters. The current patchwork won’t last; it’s either going to consolidate around comprehensive coverage or fragment into permanent digital divides. For near-term planning, assume market pressure wins. Apple and Google’s wallet integration creates too much user expectation for politicians to ignore long-term. But build for the current reality of inconsistent state coverage.
For longer-term architecture, the states with robust mDL programs are effectively beta-testing the future of government digital services. Watch how they handle edge cases, privacy concerns, and technical integration challenges.
We accidentally stress-tested American federalism through the largest fraud in history. Only some states learned from the experience. Now we’re running a second experiment: can consumer expectations accomplish what security crises couldn’t?
There’s also a third possibility. These programs could just fail. Low adoption rates, technical problems, privacy backlash, or simple bureaucratic incompetence could kill the whole thing. Government tech projects have a stellar track record of ambitious launches followed by quiet abandonment.
Back to my mDL integration project: I’m designing for the consumer pressure scenario, but building for the current reality. Whether this becomes standardized infrastructure or just another failed government tech initiative, we still need identity verification that works today.
The criminals who looted unemployment systems probably never intended to bootstrap America’s digital identity infrastructure. Whether they actually succeeded remains to be seen.
I advised Let’s Encrypt from its early days, watching it transform the security foundation of the web. Most think it won by offering free certificates. That’s dead wrong.
Existing CAs had already enabled free certificates years earlier. GlobalSign’s CloudSSL API, launched in 2011, (in full disclosure, I was their CTO), provided the automation that allowed Cloudflare to offer free SSL to end users; other CAs offered free short-lived certificates as part of forever trials as well. By 2015, you could buy DV certificates for $3-5 from certificate resellers, it was clear people were willing to pay for support which is largely what these resellers offered. The real story is about organizational constraints and misaligned incentives.
Conway’s Law Explains Everything
Traditional certificate authorities were trapped by their own organizational structure. Their business model incentivized vendor lock-in rather than ecosystem expansion and optimization. Sales teams wanted products’ proprietary APIs to make it harder for customers to switch, and were riding the wave of internet expansion. Compliance teams’ jobs depended on defending existing processes. Engineering teams were comfortable punting all compliance work to the “compliance” department. Support teams were positioned as competitive differentiators and used to entrench customers. Their goal was maximizing revenue, defending their jobs, and maintaining the status quo, not getting the web to 100% HTTPS.
Let’s Encrypt had completely different incentives and could optimize solving the larger problems without these organizational constraints. But LE’s success went beyond solving their own problems. They systematically identified every pain point in the way of getting to 100% HTTPS and built solutions that worked for everyone.
What LE Could Do That Traditional CAs Couldn’t
True standardization. Before ACME (the protocol that automates certificate requests), every major CA had incompatible automation systems. Comodo, DigiCert, GlobalSign and others each had proprietary approaches that required custom integration and as a result, had inherent switching costs; they saw no incentive to work together to standardize as a result. LE led the creation of ACME as an open standard that made switching CAs as simple as changing a configuration setting.
This enabled applications like Caddy and Google Cloud Load Balancer to handle certificates automatically for their customers without vendor-specific code. Once cloud platforms could flip switches to HTTPS-by-default, network effects became unstoppable.
Ecosystem-wide solutions. When LE felt coordination pain from renewal spikes and incident-related revocations, they created ACME Renewal Information (ARI, a protocol extension that helps coordinate renewal timing) so all CAs could prevent renewal storms. Traditional CAs couldn’t build these solutions because their org charts prevented optimizing for competitors’ success and instead focused on riding the internet expansion.
Engineering-driven compliance. Instead of compliance teams reviewing certificates after issuance, LE built policy compliance directly into certificate generation pipelines. Violations became orders of magnitude harder rather than detectable. Traditional CAs couldn’t eliminate their compliance departments because those jobs justified organizational overhead.
The Market Found Natural Segments
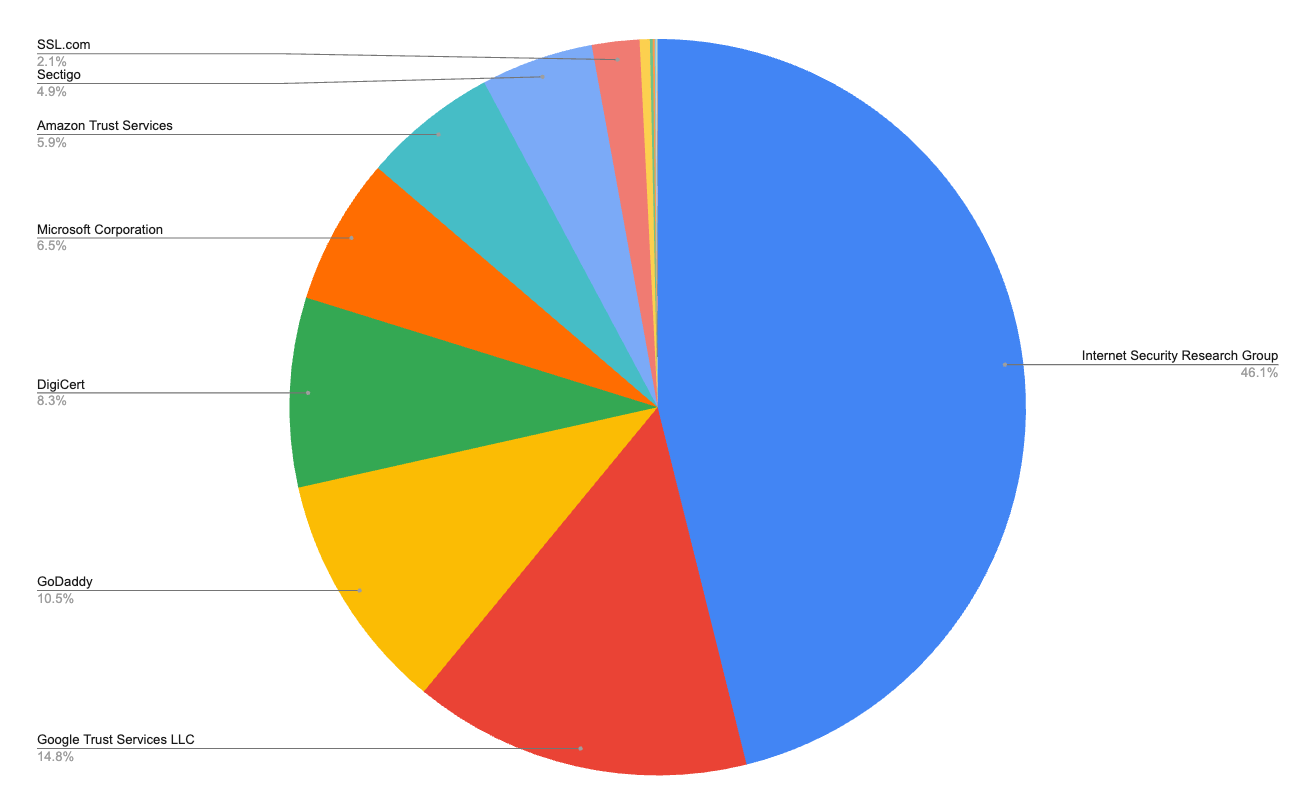
Mozilla telemetry reveals exactly what happened. Let’s Encrypt dominates issuance at 46.1% of certificates but ranks third in Firefox usage. LE democratized HTTPS for the long tail: domain parking networks, no-code builders, shared hosting platforms serving millions of low-traffic sites.
Meanwhile, high-traffic sites gravitated toward CAs like Google Trust Services (in full disclosure, I was responsible for creation of this service) that lead usage, as its used by large sites that value high availability and performance, leading to more relying party reliance despite lower issuance volumes, or established players like DigiCert and Sectigo that focus on supporting large enterprise customers. These sites need commercial support and accountability when things go wrong. The market is segmented around operational needs: the long tail valued automation over accountability, while major platforms needed enterprise support and someone to support them when something goes wrong.
Once long-tail providers flipped to HTTPS-by-default, encrypted pages became the norm. Google’s Transparency Report shows 99% of Chrome page-loads now occur over HTTPS, a transformation that began when Let’s Encrypt launched in April 2016.
The Industry Finally Admitted LE Was Right
Here’s the ultimate vindication: in 2025, the CA/Browser Forum mandated 47-day maximum certificate validity by 2029, with Chrome requiring automation from every public CA. Let’s Encrypt didn’t follow industry trends. The industry now follows Let’s Encrypt.
What seemed like LE’s “unusual” 90-day lifespans in 2016 became conservative by 2025. The mandate’s technical reasoning mirrors what LE pioneered: short-lived certificates reduce dependence on revocation checking, reduce key compromise windows, and force automated resilient infrastructure.
Leading organizations moved even further ahead. Netflix runs 30-day certificates in production, Google issues 7-day certificates for infrastructure, and Let’s Encrypt will introduce 6-day certificates by end of 2025. The mandates aren’t pushing innovation forward; they’re codifying where leaders already operate.
Why This Matters Beyond Certificates
Let’s Encrypt proved that critical internet infrastructure could be reimagined from first principles rather than optimized around legacy organizational constraints and practices. But the implications go deeper than certificate automation.
Traditional CAs were fundamentally vetting authorities with deep expertise in legal requirements for vetting people and businesses worldwide. They should have owned the remote identity verification market that exploded with digital transformation. Instead, they remained myopically focused on public trust-based certificate products while companies like Jumio and Onfido captured those opportunities. At the same time, they missed the massive expansion of machine and workload identity because they were ignoring private PKI use cases. They weren’t just leaving money on the table; they were failing to build a resilient business and neglecting the foundation for the trust infrastructure they supposedly managed.
The same organizational constraints that prevented CAs from building ACME also blinded them to adjacent markets that were natural extensions of their core competencies. They were too focused on maintaining certificate revenue streams and too constrained by existing structures to recognize how the world was shifting from hosting providers to cloud to SaaS.
ACME became the standard not because it was technically superior to existing APIs, though it was, but because it was designed for portability rather than lock-in. ARI emerged because LE experienced ecosystem pain and could fix it without navigating corporate bureaucracy or competitive concerns.
The complexity and friction we’d accepted for decades weren’t inherent to certificate management. It was the byproduct of organizational structures optimizing for vendor revenue rather than user adoption.
Today’s 47-day mandate represents more than policy evolution. It’s the industry formally acknowledging that Let’s Encrypt defined the correct approach for internet trust infrastructure. Conway’s Law isn’t destiny, but escaping it requires the courage to rebuild systems around user needs rather than organizational convenience.
In the past, I’ve written about how to measure the WebPKI, and from time to time I post brief updates on how the market is evolving.
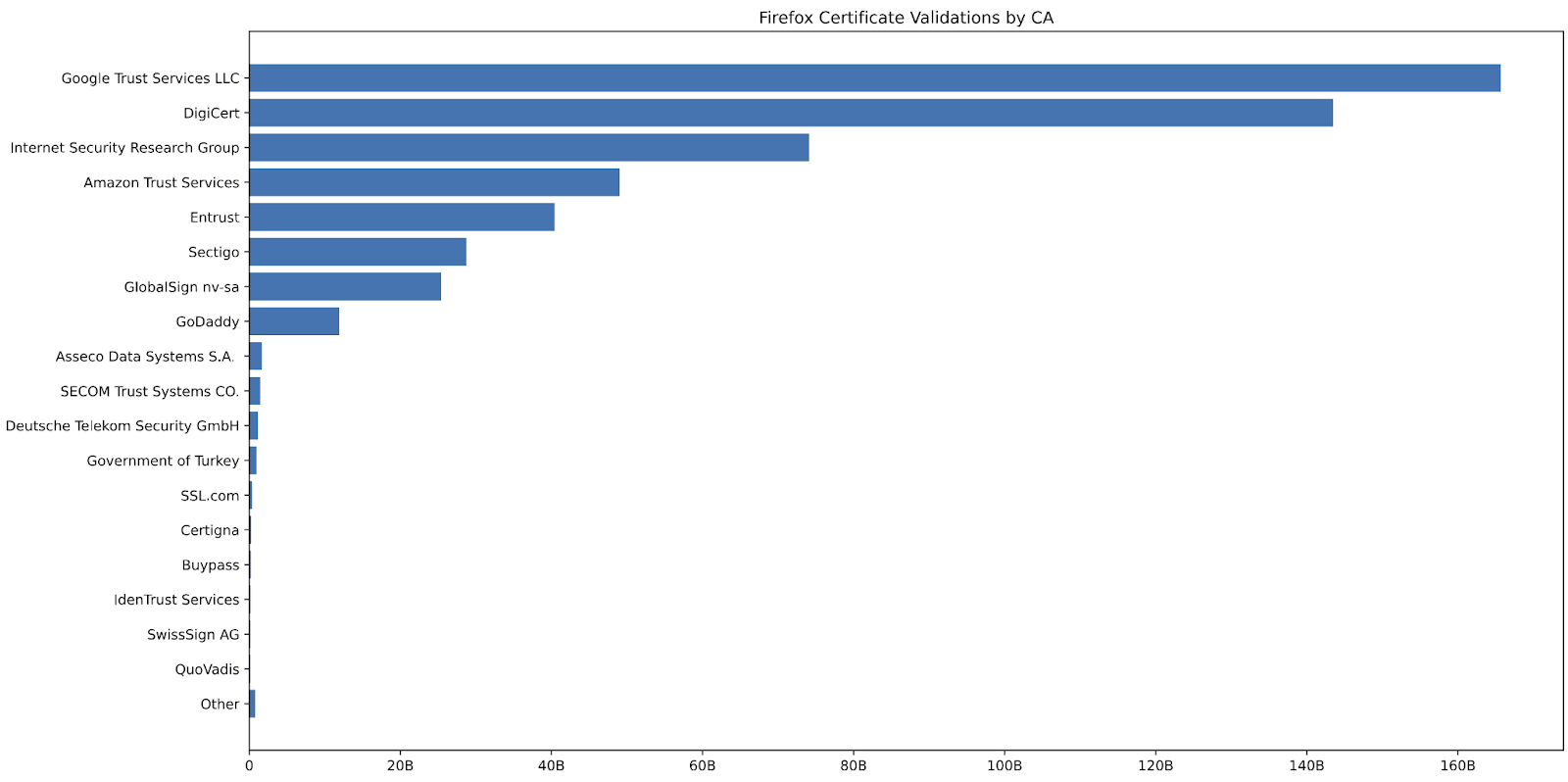
The other day, Matthew McPherrin posted a script showing how to use Mozilla telemetry data to analyze which Certificate Authorities are more critical to the web. Specifically, what percentage of browsing relies on each CA. Mozilla provides public data from Firefox’s telemetry on how many times a CA is used to successfully validate certificates. This is a pretty good measure for how “big” a CA actually is. The data is pretty hard to view in Mozilla’s public systems though, so he made a script to combine a few data sources and graph it.
I normally focus on total issuance numbers since they’re easier to obtain. That data comes from Certificate Transparency logs, which contain all publicly trusted certificates that you might encounter without seeing an interstitial warning about the certificate not being logged (like this example).
What the Data Reveals
Both datasets feature many of the same major players. But there are some striking differences that reveal important insights about the WebPKI ecosystem.
Let’s Encrypt dominates certificate issuance at 46.1% of all certificates. But it ranks third in Firefox’s actual usage telemetry. This suggests Let’s Encrypt serves many lower-traffic sites. Meanwhile, Google Trust Services leads in Firefox usage while ranking second in certificate issuance volume. This shows how high-traffic sites can amplify a CA’s real-world impact.
DigiCert ranks second in Firefox usage while placing fourth in certificate issuance volume at 8.3%. This reflects their focus on major enterprise customers. With clients like Meta (Facebook, Instagram, WhatsApp), they secure some of the world’s highest-traffic websites. This “fewer certificates, massive impact” approach drives them up the usage charts despite not competing on volume with Let’s Encrypt.
Google’s dominance reflects more than just their own properties like Google.com, YouTube, and Gmail. Google Cloud offers arguably the best load balancer solution in the market (full disclosure I worked on this project). You get TLS by default for most configurations. Combined with their global network that delivers CDN-like benefits out of the gate, this attracts major platforms like Wix and many others to build on Google Cloud. When these platforms choose Google’s infrastructure, they automatically inherit Google Trust Services certificates.
Looking at the usage data reveals other interesting patterns. Deutsche Telekom Security, Government of Turkey, (UPDATE: turns out the Turkey entry is a Firefox bug: they’re using bucket #1 for both locally installed roots and Kamu SM, apparently by accident) and SECOM Trust Systems all appear prominently in Firefox telemetry but barely register in issuance numbers. In some respects, it’s no surprise that government-issued certificates see disproportionate usage. Government websites are often mandated for use. Citizens have to visit them for taxes, permits, benefits, and other essential services.
Microsoft Corporation appears significantly in issuance data (6.5%) but doesn’t register in the Firefox telemetry. This reflects their focus on enterprise and Windows-integrated scenarios rather than public web traffic.
GoDaddy shows strong issuance numbers (10.5%) but more modest representation in browsing telemetry. This reflects their massive domain parking operations. They issue certificates for countless parked domains that receive minimal actual user traffic.
Why This Matters
Mozilla Firefox represents under 3% of global browser market share. This telemetry reflects a smaller segment of internet users. While this data provides valuable insights into actual CA usage patterns, it would be ideal if Chrome released similar telemetry data. Given Chrome’s dominant 66.85% market share, their usage data would dramatically improve our understanding of what real WebPKI usage actually looks like across the broader internet population.
The contrast between certificate issuance volume and actual browsing impact reveals important truths about internet infrastructure. CT logs currently show over 450,000 certificates being issued per hour across all CAs. Yet as this Firefox telemetry data shows, much of that volume serves lower-traffic sites while a smaller number of high-traffic certificates drive the actual user experience. Some CAs focus on high-volume, automated issuance for parked domains and smaller sites. Others prioritize fewer certificates for high-traffic, essential destinations. Understanding both metrics helps us better assess the real-world criticality of different CAs for internet security and availability.
Raw certificate counts don’t tell the whole story. The websites people actually visit, and sometimes must visit, matter just as much as the sheer number of certificates issued. Some certificates protect websites with “captive audiences” or essential services, while others protect optional destinations. A government tax portal or YouTube will always see more traffic than the average small business website, regardless of how many certificates each CA issues.
Regardless of how you count, I’ve had the pleasure of working closely with at least 7 of the CAs in the top 10 in their journeys to become publicly trusted CAs. Each of these CAs have had varying goals for their businesses and operations, and that’s exactly why you see different manifestations in the outcomes. Let’s Encrypt focused on automation and volume. DigiCert targeted enterprise customers. Google leveraged their cloud infrastructure. GoDaddy built around domain services.
Either way, it’s valuable to compare and contrast these measurement approaches to see what the WebPKI really looks like beyond just raw certificate counts.
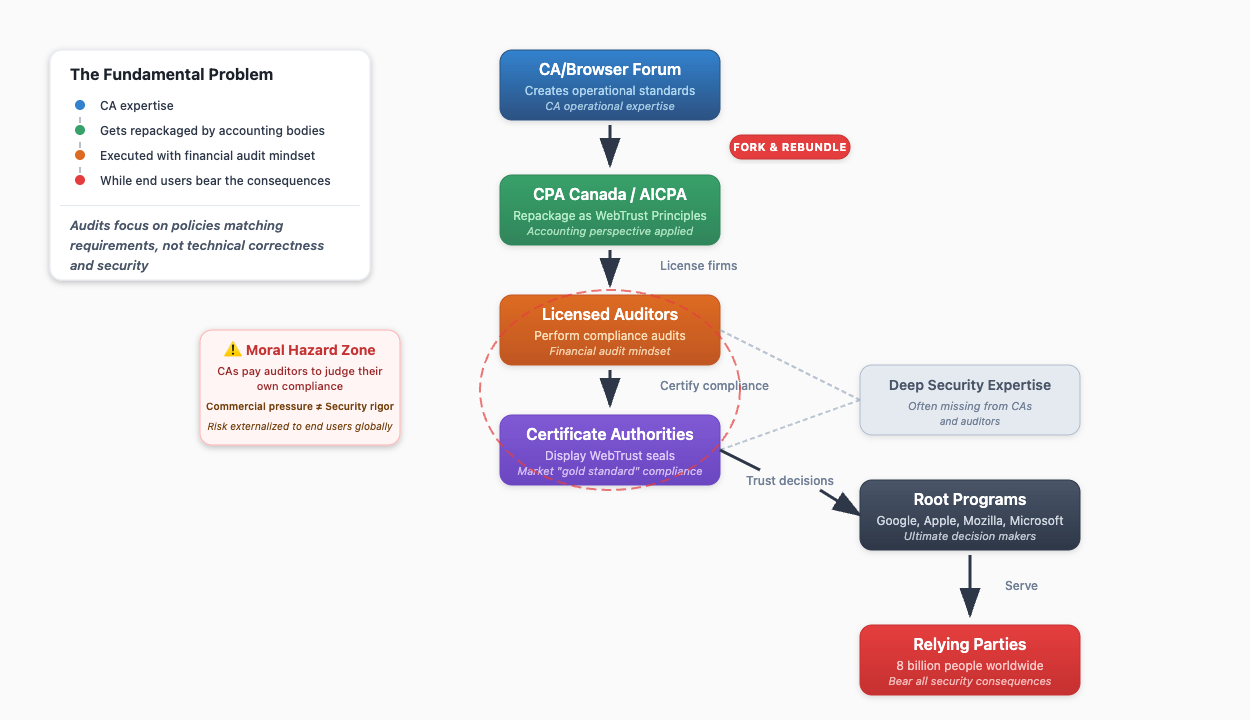
When we discuss the WebPKI, we naturally focus on Certificate Authorities (CAs), browser root programs, and the standards established by the CA/Browser Forum. Yet for these standards to carry real weight, they must be translated into formal, auditable compliance regimes. This is where assurance frameworks enter the picture, typically building upon the foundational work of the CA/Browser Forum.
The WebTrust framework, overseen by professional accounting bodies, is only one way to translate CA/Browser Forum requirements into auditable criteria. In Europe, a parallel scheme relies on the European Telecommunications Standards Institute (ETSI) for the technical rules, with audits carried out by each country’s ISO/IEC 17065-accredited Conformity Assessment Bodies. Both frameworks follow the same pattern: they take the CA/Browser Forum standards and repackage them into structured compliance audit programs.
Understanding the power dynamics here is crucial. While these audits scrutinize CAs, they exercise no direct control over browser root programs. The root programs at Google, Apple, Microsoft, and Mozilla remain the ultimate arbiters. They maintain their own policies, standards, and processes that extend beyond what these audit regimes cover. No one compels the browsers to require WebTrust or ETSI audits; they volunteer because obtaining clean reports from auditors who have seen things in person helps them understand if the CA is competent and living up to their promises.
How WebTrust Actually Works
With this context established, let’s examine the WebTrust model prevalent across North America and other international jurisdictions. In North America, administration operates as a partnership between the AICPA (for the U.S.) andCPA Canada. For most other countries, CPA Canada directly manages international enrollment, collaborating with local accounting bodies like the HKICPA for professional oversight.
These organizations function through a defined sequence of procedural steps: First, they participate in the CA/Browser Forum to provide auditability perspectives. Second, they fork the core technical requirements and rebundle them as the WebTrust Principles and Criteria. Third, they license accounting firms to conduct audits based on these principles and criteria. Fourth, they oversee licensed practitioners through inspection and disciplinary processes.
The audit process follows a mechanical flow. CA management produces an Assertion Letter claiming compliance. The auditor then tests that assertion and produces an Attestation Report, a key data point for browser root programs. Upon successful completion, the CA can display the WebTrust seal.
This process creates a critical misconception about what the WebTrust seal actually signifies. Some marketing approaches position successful audits as a “gold seal” of approval, suggesting they represent the pinnacle of security and best practices. They do not. A clean WebTrust report simply confirms that a CA has met the bare minimum requirements for WebPKI participation, it represents the floor, not the ceiling. The danger emerges when CAs treat this floor as their target; these are often the same CAs responsible for significant mis-issuances and ultimate distrust by browser root programs.
Where Incentives Break Down
Does this system guarantee consistent, high-quality CA operations? The reality is that the system’s incentives and structure actively work against that goal. This isn’t a matter of malicious auditors; we’re dealing with human nature interacting with a flawed system, compounded by a critical gap between general audit principles and deep technical expertise.
Security professionals approach assessments expecting auditors to actively seek problems. That incentive doesn’t exist here. CPA audits are fundamentally designed for financial compliance verification, ensuring documented procedures match stated policies. Security assessments, by contrast, actively hunt for vulnerabilities and weaknesses. These represent entirely different audit philosophies: one seeks to confirm documented compliance, the other seeks to discover hidden risks.
This philosophical gap becomes critical when deep technical expertise meets general accounting principles. Even with impeccably ethical and principled auditors, you can’t catch what you don’t understand. A financial auditor trained to verify that procedures are documented and followed may completely miss that a technically sound procedure creates serious security vulnerabilities.
This creates a two-layer problem. First, subtle but critical ambiguities or absent content in a CA’s Certification Practice Statement (CPS) and practices might not register as problems to non-specialists. Second, even when auditors do spot vague language, commercial pressures create an impossible dilemma: push the customer toward greater specificity (risking the engagement and future revenue), or let it slide due to the absence of explicit requirements.
This dynamic creates a classic moral hazard, an issue similar to the one we explored in our recent post, Auditors are paid by the very entities they’re supposed to scrutinize critically, creating incentives to overlook issues in order to maintain business relationships. Meanwhile, the consequences of missed problems, security failures, compromised trust, and operational disruptions fall on the broader WebPKI ecosystem and billions of relying parties who had no voice in the audit process. This dynamic drives the inconsistencies we observe today and reflects a broader moral hazard problem plaguing the entire WebPKI ecosystem, where those making critical security decisions rarely bear the full consequences of poor choices.
This reality presents a prime opportunity for disruption through intelligent automation. The core problem lies in expertise “illiquidity”, deep compliance knowledge remains locked in specialists’ minds, trapped in manual processes, and is prohibitively expensive to scale.
Current compliance automation has only created “automation asymmetry,” empowering auditees to generate voluminous, polished artifacts that overwhelm manual auditors. This transforms audits from operational fact-finding into reviews of well-presented fiction.
The solution requires creating true “skill liquidity” through AI: not just another LLM, but an intelligent compliance platform embedding structured knowledge from seasoned experts. This system would feature an ontology of controls, evidence requirements, and policy interdependencies, capable of performing the brutally time-consuming rote work that consumes up to 30% of manual audits: policy mapping, change log scrutiny, with superior speed and consistency.
When auditors and program administrators gain access to this capability, the incentive model fundamentally transforms. AI can objectively flag ambiguities and baseline deviations that humans might feel pressured to overlook or lack the skill to notice, directly addressing the moral hazard inherent in the current system. When compliance findings become objective data points generated by intelligent systems rather than subjective judgments influenced by commercial relationships, they become much harder to ignore or rationalize away.
This transformation liquefies rote work, liberating human experts to focus on what truly matters: making high-stakes judgment calls, investigating system-flagged anomalies, and assessing control effectiveness rather than mere documented existence. This elevation transforms auditors from box-checkers into genuine strategic advisors, addressing the system’s core ethical challenges.
This new transparency and accountability shifts the entire dynamic. Audited entities can evolve from reactive fire drills to proactive, continuous self-assurance. Auditors, with amplified expertise and judgment focused on true anomalies rather than ambiguous documentation, can deliver exponentially greater value.
Moving Past the Performance
This brings us back to the fundamental issue: the biggest problem in communication is the illusion that it has occurred. Today’s use of the word “audit” creates a dangerous illusion of deep security assessment.
By leveraging AI to create skill liquidity, we can finally move past this illusion by automating the more mundane audit elements giving space where the assumed security and correctness assessments also happen. We can forge a future where compliance transcends audit performance theater, becoming instead a foundation of verifiable, continuous operational integrity, built on truly accessible expertise rather than scarce, locked-away knowledge.
The WebPKI ecosystem deserves better than the bare minimum. With the right tools and transformed incentives, we can finally deliver it.
TL;DR: Root programs, facing user loss, prioritize safety, while major CAs, with browsers, shape WebPKI rules. Most CAs, risking distrust or customers, seek leniency, shifting risks to billions of voiceless relying parties. Subscribers’ push for ease fuels CA resistance, demanding reform.
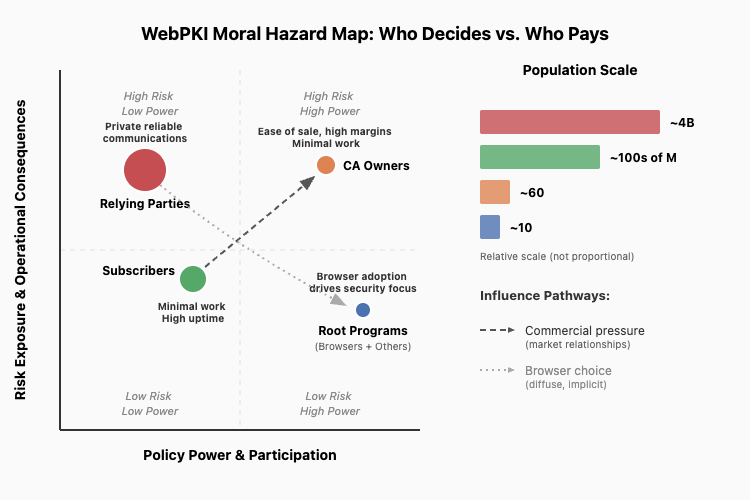
The recent Mozilla CA Program roundtable discussion draws attention to a fundamental flaw in how we govern the WebPKI, one that threatens the security of billions of internet users. It’s a classic case of moral hazard: those making critical security decisions face minimal personal or professional consequences for poor choices, while those most affected have virtually no say in how the system operates.
The Moral Hazard Matrix
The numbers reveal a dangerous imbalance in who controls WebPKI policy versus who bears the consequences. Browsers, as root programs, face direct accountability; if security fails, users abandon them. CAs on the other hand are incentivized to reduce customer effort and boost margins, externalize risks, leaving billions of relying parties to absorb the fallout:
A classic moral hazard structure, with a key distinction: browser vendors, as root programs, face direct consequences, lose security, lose users, aligning incentives with safety. CAs, while risking distrust or customer loss, often externalize greater risks to relying parties, leaving them to face the fallout betting that they wont be held accountable for these decisions.
Mapping the Accountability Breakdown
The roundtable revealed a systematic divide in how stakeholders approach CPS compliance issues. CAs, driven by incentives to minimize customer effort for easy sales and reduce operational costs for higher margins, consistently seek to weaken accountability, while root programs and the security community demand reliable commitments:
Position
Supported By
Core Argument
What It Really Reveals
“Revocation too harsh for minor CPS errors”
CA Owners
Policy mismatches shouldn’t trigger mass revocation
Want consequences-free policy violations
“Strict enforcement discourages transparency”
CA Owners
Fear of accountability leads to vague CPSs
Treating governance documents as optional “documentation”
“SLA-backed remedies for enhanced controls”
CA Owners
Credits instead of revocation for optional practices
Attempt to privatize trust governance
“Split CPS into binding/non-binding sections”
CA Owners
Reduce revocation triggers through document structure
Avoid accountability while claiming transparency
“Human error is inevitable”
CA Owners
Manual processes will always have mistakes
Excuse for not investing in automation
“Retroactive CPS fixes should be allowed”
CA Owners
Patch documents after problems surface
Gut the very purpose of binding commitments
“CPS must be enforceable promises”
Root Programs, Security Community
Documents should reflect actual CA behavior
Public trust requires verifiability
“Automation makes compliance violations preventable”
Technical Community
65+% ACME adoption proves feasibility
Engineering solutions exist today
The pattern is unmistakable: CAs consistently seek reduced accountability, while those bearing security consequences demand reliable commitments. The Microsoft incident perfectly illustrates this, rather than addressing the absence of systems that would automatically catch discrepancies before millions of certificates were issued incorrectly, industry discussion focused on making violations easier to excuse retroactively.
The Fundamental Mischaracterization
Much of the roundtable suffered from a critical misconception: the CPS is “documentation” rather than what it is, the foundational governance document that defines how a CA operates.
A CPS looks like a contract because it is a contract, a contract with the world. It’s the binding agreement that governs CA operations, builds trust by showing relying parties how the CA actually works, guides subscribers through certification requirements, and enables oversight by giving auditors a baseline against real-world issuance. When we minimize it as “documentation,” we’re arguing that CAs should violate their core operational commitments with minimal consequences.
CPS documents are the public guarantee that a CA knows what it’s doing and will stand behind it, in advance, in writing, in full view of the world. The moment we treat them as optional “documentation” subject to retroactive fixes, we’ve abandoned any pretense that trustworthiness can be verified rather than simply taken on blind faith.
Strategic Choices Masquerading as Constraints
Much CA pushback treats organizational and engineering design decisions as inevitable operational constraints. When CAs complain about “compliance staff being distant from engineering” or “inevitable human errors in 100+ page documents,” they’re presenting strategic choices as unchangeable facts.
CAs choose to separate compliance from operations rather than integrate them. They choose to treat CPS creation as documentation rather than operational specification. They choose to bolt compliance on after the fact rather than build it into core systems. When you choose to join root programs to be trusted by billions of people, you choose those responsibilities.
The CAs that consistently avoid compliance problems made different choices from the beginning, they integrated policy into operations, invested in automation, and designed systems where compliance violations are structurally difficult. These aren’t companies with magical resources; they’re companies that prioritized operational integrity.
The Technology-Governance Gap
The “automation is too hard” argument collapses against actual WebPKI achievements:
Challenge
Current State
Feasibility Evidence
CA Resistance
Domain Validation
Fully automated via ACME
65+% of web certificates
✅ Widely adopted
Certificate Linting
Real-time validation at issuance
CT logs, zlint tooling
✅ Industry standard
Transparency Logging
All certificates publicly logged
Certificate Transparency
✅ Mandatory compliance
Renewal Management
Automated with ARI
Let’s Encrypt, others
✅ Proven at scale
CPS-to-Issuance Alignment
Manual, error-prone
Machine-readable policies possible
❌ “Too complex”
Policy Compliance Checking
After-the-fact incident reports
Automated validation possible
❌ “Inevitable human error”
The pattern is unmistakable: automation succeeds when mandated, fails when optional. With Certificate Transparency providing complete visibility, automated validation systems proven at scale, and AI poised to transform compliance verification across industries, operational CPSs represent evolution, not revolution.
The argument is that these “minor” incidents don’t represent smoke, as in where there is smoke there is fire, when we know through past distrust events it is always a pattern of mistakes often snowballing while the most mature CA programs only occasional have issues, and when they do they deal with them well.
Trust Is Not an Entitlement
The question “why would CAs voluntarily adopt expensive automation?” reveals a fundamental misunderstanding. CAs are not entitled to being trusted by the world.
Trust store inclusion is a privilege that comes with responsibilities. If a CA cannot or will not invest in operational practices necessary to serve billions of relying parties reliably, they should not hold that privilege.
The economic argument is backwards:
Current framing: “Automation is expensive, so CAs shouldn’t be required to implement it”
Correct framing: “If you can’t afford to operate, securely, accuratley and reliably, you can’t afford to be a public CA”
Consider the alternatives: public utilities must maintain infrastructure standards regardless of cost, financial institutions must invest in security regardless of expense, aviation companies must meet safety standards regardless of operational burden. The WebPKI serves more people than any of these industries, yet we’re supposed to accept that operational excellence is optional because it’s “expensive”?
CAs with consistent compliance problems impose costs on everyone else, subscribers face revocation disruption, relying parties face security risks, root programs waste resources on incident management. The “expensive automation” saves the ecosystem far more than it costs individual CAs.
When Accountability Actually Works
The example of Let’s Encrypt changing their CPS from “90 days” to “less than 100 days” after a compliance issue is often cited as evidence that strict enforcement creates problems. This completely misses the point.
The “system” found a real compliance issue, inadequate testing between policy and implementation. That’s exactly what publishing specific commitments accomplishes: making gaps visible so they can be fixed. The accountability mechanism worked perfectly, Let’s Encrypt learned they needed better testing to ensure policy-implementation alignment.
This incident also revealed that we need infrastructure like ACME Renewal Information (ARI) so the ecosystem can manage obligations without fire drills. The right response isn’t vaguer CPSs to hide discrepancies, but better testing and ecosystem coordination so you can reliably commit to 90 days and revocations when mistakes happen.
The Solution: Operational CPSs
Instead of weakening accountability, we need CPSs as the living center of CA operations, machine-readable on one side to directly govern issuance systems, human-readable on the other for auditors and relying parties. In the age of AI, tools like large language models and automated validation can make this dual-purpose CPS tractable, aligning policy with execution.
This means CPSs written by people who understand actual issuance flows, updated in lock-step with operational changes, tied directly to automated linting, maintained in public version control, and tested continuously to verify documentation matches reality.
Success criteria are straightforward:
Scope clarity: Which root certificates does this cover?
Profile fidelity: Could someone recreate certificates matching actual issuance?
Validation transparency: Can procedures be understood without insider knowledge?
Most CPSs fail these basic tests. The few that pass prove it’s entirely achievable when CAs prioritize operational integrity over administrative convenience.
Systemic Reform Requirements
Fixing moral hazard requires accountability mechanisms aligned with actual capabilities. Root programs typically operate with 1-2 people overseeing ~60 organizations issuing 450,000+ certificates per hour, structural challenges that automation must address.
Clearer requirements for CPS documents, automated evaluation tools, clear standards
Scalable infrastructure requiring scope clarity, profile fidelity, and validation transparency
Standards Bodies
Voluntary guidelines, weak enforcement
Mandatory automation requirements
Updated requirements to ensure adoption of automation that helps ensure commitments are met.
Audit System
Annual snapshots, limited scope
Continuous monitoring, real-time validation
Integration with operational systems
Root programs that tolerate retroactive CPS fixes inadvertently encourage corner-cutting on prevention systems. Given resource constraints, automated evaluation tools and clear standards become essential for consistent enforcement.
The Stakes Demand Action
Eight billion people depend on this system. We cannot allow fewer than 60 CA owning organizations to keep treating public commitments as optional paperwork instead of operational specifications.
When certificate failures occur, people lose life savings, have private communications exposed, lose jobs when business systems fail, or face physical danger when critical infrastructure is compromised. DigiNotar’s 2011 collapse showed how single CA failures can compromise national digital infrastructure. CAs make decisions that enable these risks; relying parties bear the consequences.
The choice is stark:
Continue excuse-making and accountability avoidance while billions absorb security consequences
Or demand that CAs and root programs invest in systems making trust verifiable
The WebPKI’s moral hazard problem won’t solve itself. Those with power to fix it have too little incentive to act; those who suffer consequences have too little voice to demand change.
The WebPKI stands at a turning point. Root programs, the guardians of web privacy, are under strain from the EU’s eIDAS 2.0 pushing questionable CAs, tech layoffs thinning their teams, and the U.S. DOJ’s plan to break up Chrome, a cornerstone of web security. With eight billion people depending on this system, weak CAs could fuel phishing scams, data breaches, or outages that upend lives, as DigiNotar’s 2011 downfall showed. That failure taught us trust must be earned through action. Automation, agility, and transparency can deliver a WebPKI where accountability is built-in. Let’s urge CAs, root programs, and the security community to adopt machine-readable CPSs by 2026, ensuring trust is ironclad. The time to act is now, together, we can secure the web for our children and our grandchildren.
Why the 2025 Amendments to EO 14144 Walked Back Progress on PQC, SBOMs, and Enforcement, Even as the Products to Support Them Have Become Real.
The June 2025 amendments to Executive Order 14144 read like a cybersecurity manifesto. They name adversaries (China, Russia, Iran, North Korea) with unprecedented directness and reference cutting-edge threats like quantum computing and AI-enabled attacks. The rhetoric is strong. The tone, urgent.
But beneath the geopolitical theater, something quieter and more troubling has happened. The Executive Order has systematically stripped out the enforcement mechanisms that made federal cybersecurity modernization possible. Mandates have become “guidance.” Deadlines have turned into discretion. Requirements have transformed into recommendations.
We’re witnessing a shift from actionable federal cybersecurity policy to a fragmented, voluntary approach, just as other nations double down on binding standards and enforcement.
The Enforcement Rollback
The most visible casualty was the software bill of materials (SBOM) mandate . The original EO 14144 required vendors to submit machine-readable attestations, with specific deadlines for updating federal procurement rules. These requirements have been entirely deleted.
This removal actually makes sense. Most SBOMs today are fundamentally broken: generated manually, and don’t actually match to deployed artifacts. Without robust validation infrastructure, SBOMs create more noise than signal. Use cases like vulnerability correlation break down when the underlying data is untrustworthy.
Once you have reproducible builds and verifiable provenance pipelines, SBOMs become implicit in the process. The government was both premature and naive in requiring SBOMs before the ecosystem could reliably generate them and do something with them. More fundamentally, they hooed that mandating documentation would somehow solve the underlying supply chain visibility problem – unfortunately thats not the case.
But SBOMs are a symptom of deeper issues: unreproducible builds, opaque dependency management, and post-hoc artifact tracking. Simply requiring vendors to produce better paperwork was never going to address these foundational challenges. The mandate confused the deliverable with the capability.
What’s more concerning is what else disappeared. Provisions mandating phishing-resistant multi-factor authentication, real-time interagency threat sharing, and specific timelines for aligning federal IT procurement with Zero Trust requirements all vanished. The detailed Border Gateway Protocol security language was replaced with generic “agency coordination” directives. The EO stripped away near-term pressure on vendors and agencies alike.
Yet even as these enforcement mechanisms were being removed, the amendments introduced something potentially transformative.
Rules as Code: Promise, Paradox, and Perfect Timing
The most exciting addition is buried in bureaucratic language. A pilot program for “machine-readable versions of policy and guidance” in cybersecurity appears almost as an afterthought. While the EO doesn’t name OSCAL explicitly, this is almost certainly referring to expanding the Open Security Controls Assessment Language use beyond its current FedRAMP usage into broader policy areas.
This could be transformative. Imagine cybersecurity policies that are automatically testable, compliance that’s continuously verifiable, and security controls that integrate directly with infrastructure-as-code. OSCAL has already proven this works in FedRAMP: structured security plans, automated assessment results, and machine-readable control catalogs. Expanding this approach could revolutionize how government manages cybersecurity risk.
But there’s something deliciously ironic about the timing. We’re finally standardizing JSON schemas for control matrices and policy frameworks just as AI becomes sophisticated enough to parse and understand unstructured policy documents directly. It’s almost comical. Decades of manual compliance work have driven us to create machine-readable standards, and now we have “magical AI” that could theoretically read the original messy documents.
Yet the structured approach remains the right direction. While AI can parse natural language policies, it introduces interpretation variations. Different models might understand the same requirement slightly differently. OSCAL’s structured format eliminates ambiguity. When a control is defined in JSON, there’s no room for misinterpretation about implementation requirements.
More importantly, having machine-readable controls means compliance tools, security scanners, and infrastructure-as-code pipelines can directly consume and act on requirements without any parsing layer. The automation becomes more reliable and faster than AI interpretation. Real-time compliance monitoring really only works with structured data. AI might tell you what a policy says, but OSCAL helps you build systems that automatically check if you’re meeting it continuously.
This pattern of promising technical advancement while retreating from enforcement continues in the amendments’ approach to cryptographic modernization.
The Post-Quantum Reality Check
Then there’s the post-quantum cryptography provisions. The EO requires CISA and NSA to publish lists of PQC-supporting products by December 2025, and mandates TLS 1.3 by January 2030.
The TLS 1.3 requirement appears to be carried over from the previous executive order, suggesting this wasn’t a deliberate policy decision but administrative continuity. The amendment specifically states that agencies must “support, as soon as practicable, but not later than January 2, 2030, Transport Layer Security protocol version 1.3 or a successor version.” More tellingly, the 2030 timeline likely reflects a sobering recognition of enforcement reality: federal agencies and contractors are struggling with basic infrastructure modernization, making even a five-year runway for TLS 1.3 adoption potentially optimistic.
This reveals the central tension in federal cybersecurity policy. The infrastructure is calcified. Legacy systems, interception-dependent security architectures, and procurement cycles that move at geological speed all contribute to the problem. A 2030 TLS 1.3 mandate isn’t visionary; it’s an acknowledgment that the federal government can’t move faster than its most outdated components.
But this enforcement realism makes the broader PQC timeline even more concerning. If we need five years to achieve TLS 1.3 adoption across federal systems, how long will the actual post-quantum migration take? By 2030, the question won’t be whether agencies support TLS 1.3, but whether they’ve successfully migrated key exchange, digital signatures, and PKI infrastructure to post-quantum algorithms. That’s a far more complex undertaking.
In essence, the EO treats PQC like a checklist item when it’s actually a teardown and rebuild of our cryptographic foundation. Historically, the federal government has led cryptographic transitions by creating market demand and demonstrating feasibility, not by setting distant mandates. When the government moved to AES or adopted Suite B algorithms, it drove adoption through procurement pressure and early implementation.
Meanwhile, allies like the UK and Germany are taking this traditional approach with PQC. The UK’s National Cyber Security Centre has published detailed migration timelines and will launch a pilot program to certify consultancy firms that provide PQC migration support to organizations. Germany’s Federal Office for Information Security has been leading in co-developing standards and demonstrating early government adoption. They’re creating market pull through demonstrated feasibility, not regulatory deadlines that may prove unenforceable.
Beyond cryptography, the EO does introduce some concrete requirements, though these represent a mixed bag of genuine progress and missed opportunities.
The EO also tasks NIST with updating key frameworks and calls for AI-specific vulnerability coordination. All valuable work. But notably absent: any requirement for agencies to adopt, implement, or report on these updated frameworks.
One genuinely new addition is the IoT Cyber Trust Mark requirement: by January 2027, federal agencies must require vendors of consumer IoT products to carry the labeling. This represents concrete procurement leverage, though it’s limited to a narrow product category.
These mixed signals, technical infrastructure development alongside enforcement retreat, reflect a broader pattern that undermines the federal government’s cybersecurity leadership.
As we’ve explored in previous discussions of AI’s impact on compliance, this shift toward automated policy interpretation and enforcement represents a broader transformation in how expertise flows through complex systems, but only when the underlying mandates exist to make that automation meaningful.
We’re building this sophisticated machine-readable infrastructure just as the enforcement mechanisms that would make it meaningful are being stripped away. It’s like having a perfectly engineered sports car but removing the requirement to actually drive anywhere.
The Infrastructure Is Ready. The Mandate Isn’t.
Federal cybersecurity policy shapes vendor behavior, influences state and local government standards, and signals U.S. priorities to international partners. Without centralized mandates, vendors receive mixed signals. Agencies implement inconsistently. Meanwhile, international partners advance with clearer timelines and stronger enforcement. The U.S. risks ceding leadership in areas where it built the foundational standards, just as adversaries accelerate their own capabilities.
The United States has built remarkable cybersecurity infrastructure. OSCAL for automated compliance, frameworks for secure software development, and draft PQC standards for cryptographic transition all represent genuine achievements. But the June 2025 amendments represent a retreat from the leadership needed to activate this infrastructure.
We have the tooling, standards, and momentum, but we’ve paused at the moment we needed to press forward. In the face of growing threats and global urgency, discretion is not resilience.
We’ve codified trust, but stopped requiring it, leaving security to agency discretion instead of institutional design. That’s not a strategy. It’s a hope. And hope is not a security control.
I’ve been in the PKI space for a long time, and I’ll be honest, digging through Certificate Policies (CPs) and Certification Practice Statements (CPSs) is far from my favorite task. But as tedious as they can be, these documents serve real, high-value purposes. When you approach them thoughtfully, the time you invest is anything but wasted.
What a CPS Is For
Beyond satisfying checkbox compliance, a solid CPS should:
Build trust by showing relying parties how the CA actually operates.
Guide subscribers by spelling out exactly what is required to obtain a certificate.
Clarify formats by describing certificate profiles, CRLs, and OCSP responses so relying parties know what to expect.
Enable oversight by giving auditors, root store programs, and researchers a baseline to compare against real-world issuance.
If a CPS fails at any of these, it fails in its primary mission.
Know Your Audience
A CPS is not just for auditors. It must serve subscribers who need to understand their obligations, relying parties weighing whether to trust a certificate, and developers, security researchers, and root store operators evaluating compliance and interoperability.
The best documents speak to all of these readers in clear, plain language without burying key points under mountains of boilerplate.
A useful parallel is privacy policies or terms of service documents. Some are written like dense legal contracts, full of cross-references and jargon. Others aim for informed consent and use plain language to help readers understand what they are agreeing to. CPs and CPSs should follow that second model.
Good Examples Do Exist
If you’re looking for CPS documents that get the basics right, Google Trust Services and Fastly are two strong models:
There are many ways to evaluate a CPS, but given the goals of these documents, fundamental tests of “good” would certainly include:
Scope clarity: Is it obvious which root certificates the CPS covers?
Profile fidelity: Could a reader recreate reference certificates that match what the CA actually issues?
Most CPSs fail even these basic checks. Google and Fastly pass, and their structure makes independent validation relatively straightforward. Their documentation is not just accurate, it is structured to support validation, monitoring, and trust.
Where Reality Falls Short
Unfortunately, most CPSs today don’t meet even baseline expectations. Many lack clear scope. Many don’t describe what the issued certificates will look like in a way that can be independently verified. Some fail to align with basics like RFC 3647, the framework they are supposed to follow.
Worse still, many CPS documents fail to discuss how or if they meet requirements they claim compliance with. That includes not just root program expectations, but also standards like:
Server Certificate Baseline Requirements
S/MIME Baseline Requirements
Network and Certificate System Security Requirements
These documents may not need to replicate every technical detail, but they should objectively demonstrate awareness of and alignment with these core expectations. Without that, it’s difficult to expect trust from relying parties, browsers, or anyone else depending on the CA’s integrity.
Even more concerning, many CPS documents don’t fully reflect the requirements of the root programs that grant them inclusion:
These failures are not theoretical. They have led to real-world consequences.
Take Bug 1962829, for example, a recent incident involving Microsoft PKI Services. “A typo” introduced during a CPS revision misstated the presence of the keyEncipherment bit in some certificates. The error made it through publication and multiple reviews, even as millions of certificates were issued under a document that contradicted actual practice.
The result? Distrust risks, revocation discussions, and a prolonged, public investigation.
The Microsoft incident reveals a deeper problem, CAs that lack proper automation between their documented policies and actual certificate issuance. This wasn’t just a documentation error, it exposed the absence of systems that would automatically catch such discrepancies before millions of certificates were issued under incorrect policies.
This isn’t an isolated case. CP and CPS “drift” from actual practices has played a role in many other compliance failures and trust decisions. This post discusses CA distrust and misissuance due to CP or CPS not matching observable reality is certainly a common factor.
Accuracy Is Non-Negotiable
Some voices in the ecosystem now suggest that when a CPS is discovered to be wrong, the answer is simply to patch the document retroactively and move on. This confirms what I have said for ages, too many CAs want the easy way out, patching documents after problems surface rather than investing in the automation and processes needed to prevent mismatches in the first place.
That approach guts the very purpose of a CPS. Making it easier for CAs to violate their commitments creates perverse incentives to avoid investing in proper compliance infrastructure.
Accountability disappears if a CA can quietly “fix” its promises after issuance. Audits lose meaning because the baseline keeps shifting. Relying-party trust erodes the moment documentation no longer reflects observable reality.
A CPS must be written by people who understand the CA’s actual issuance flow. It must be updated in lock-step with code and operational changes. And it must be amended before new types of certificates are issued. Anything less turns it into useless marketing fluff.
Make the Document Earn Its Keep
Treat the CPS as a living contract:
Write it in plain language that every audience can parse.
Tie it directly to automated linting so profile deviations are caught before issuance. Good automation makes policy violations nearly impossible; without it, even simple typos can lead to massive compliance failures.
Publish all historical versions so the version details in the document are obvious and auditable. Better yet, maintain CPS documents in a public git repository with markdown versions that make change history transparent and machine-readable.
Run every operational change through a policy-impact checklist before it reaches production.
If you expect others to trust your certificates, your public documentation must prove you deserve that trust. Done right, a CPS is one of the strongest signals of a CA’s competence and professionalism. Done wrong, or patched after the fact, it is worse than useless.
Root programs need to spend time documenting the minimum criteria that these documents must meet. Clear, measurable standards would give CAs concrete targets and make enforcement consistent across the ecosystem. Root programs that tolerate retroactive fixes inadvertently encourage CAs to cut corners on the systems and processes that would prevent these problems entirely.
CAs, meanwhile, need to ask themselves hard questions: Can someone unfamiliar with internal operations use your CPS to accomplish the goals outlined in this post? Can they understand your certificate profiles, validation procedures, and operational commitments without insider knowledge?
More importantly, CAs must design their processes around ensuring these documents are always accurate and up to date. This means implementing testing to verify that documentation actually matches reality, not just hoping it does.
The Bottom Line
CPS documents matter far more than most people think. They are not busywork. They are the public guarantee that a CA knows what it is doing and is willing to stand behind it, in advance, in writing, and in full view of the ecosystem.
This morning, the Chrome Root Program dropped another announcement about Certificate Authority (CA) performance. Starting with Chrome 139, new TLS server certificates from specific Chunghwa Telecom [TAIWAN] and NetLock Kft. [HUNGARY] roots issued after July 31, 2025 will face default distrust. Why? “Patterns of concerning behavior observed over the past year” that have “diminished” Chrome’s confidence, signaling a “loss of integrity.”
For those of us in the WebPKI ecosystem, this news feels less like a shock and more like a weary nod of recognition. It’s another chapter in the ongoing saga of trust, accountability, and the recurring failure of some CAs to internalize a fundamental principle: “If you’re doing it right, you make the web safer and provide more value than the risk you represent.” Chrome clearly believes these CAs are falling short on that value proposition.
Browsers don’t take these actions lightly, their role as guardians of user trust necessitates them. They delegate significant trust to CAs, and when that trust gets undermined, the browser’s own credibility suffers. As Chrome’s policy states, and today’s announcement reinforces, CAs must “provide value to Chrome end users that exceeds the risk of their continued inclusion.” This isn’t just boilerplate; it’s the yardstick.
Incident reports and ongoing monitoring provide what little visibility exists into the operational realities of the numerous CAs our ecosystem relies upon. When that visibility reveals “patterns of concerning behavior,” the calculus of trust shifts. Root program managers scrutinize incident reports to assess CAs’ compliance, security practices, and, crucially, their commitment to actual improvement.
“Patterns of Concerning Behavior” Means Systemic Failure
The phrase “patterns of concerning behavior” is diplomatic speak. What it actually means is a CA’s repeated demonstration of inability, or unwillingness, to adhere to established, non-negotiable operational and security standards. It’s rarely a single isolated incident that triggers such action. More often, it’s the drip-drip-drip of failures, suggesting deeper systemic issues.
These patterns typically emerge from three critical failures:
Failing to identify true root causes. Many CAs identify superficial causes like “we missed this in our review,” “compliance failed to detect,” “we had a bug” without rigorously asking why these occurred and what foundational changes are necessary. This inevitably leads to repeat offenses.
Failure to learn from past incidents. The WebPKI has a long memory, and public incident reports are meant to be learning opportunities for the entire ecosystem. When a CA repeats its own mistakes, or those of others, it signals a fundamental breakdown in their improvement processes.
Failure to deliver on commitments. Perhaps the most egregious signal is when a CA makes commitments to address issues (engineering changes, operational improvements) and then simply fails to deliver. This reflects disrespect for root programs and the trust placed in CAs, while signaling weak compliance and engineering practices.
Chrome’s expectation for “meaningful and demonstrable change resulting in evidenced continuous improvement” wasn’t met. This isn’t about perfection; it’s about demonstrable commitment to improvement and proving it works. A “loss of integrity,” as Chrome puts it, is what happens when that commitment is found wanting.
The Problem with “Good Enough” Incident Response
Effective incident reporting should be boring, routine, and a clear demonstration that continued trust is justified. But for CAs exhibiting these negative patterns, their incident responses are anything but. They become exercises in damage control, often revealing unpreparedness, insufficient communication, or reluctance to fully acknowledge the scope and true cause of their failings.
The dangerous misconception that incident reporting is merely a “compliance function” undermines the entire process. Effective incident response requires concerted effort from compliance, engineering, operations, product teams, and leadership. When this holistic approach is missing, problematic “patterns” are inevitable.
Root programs consistently see through common deflections and mistakes that CAs make when under scrutiny:
Arguing that rules should change during an incident, even though CAs agreed to the requirements when they joined the ecosystem
Claiming an issue is “non-security relevant” as an excuse, even though requirements are requirements. There’s no “unless it isn’t a security issue” exception
Asking root programs for permission to fail despite the fact that lowering standards for one CA jeopardizes the entire WebPKI
Not following standard reporting templates signals that you don’t know the requirements and externalizes the costs of that on others by making analysis unnecessarily difficult
Accountability Isn’t Optional
Chrome’s recent actions represent accountability in practice. While some might view this as punitive, it’s a necessary mechanism to protect WebPKI integrity. For the CAs in question, and all others, the message is clear:
Rely on tools and data, not just people. Use automated systems and data-driven strategies to ensure standardized, reliable incident responses.
Preparation isn’t optional. Predefined response strategies, validated through tabletop exercises, are crucial infrastructure.
Transparency isn’t a buzzword. It’s a foundational requirement for building and maintaining trust, especially when things go wrong.
This isn’t about achieving impossible perfection. It’s about establishing and maintaining robust, auditable, and consistently improving systems and processes. It’s about fostering organizational culture where “the greatest enemy of knowledge is not ignorance, but the illusion of knowledge,” and where commitment to “sweat in practice to bleed less in battle” shows up in every action.
Trust Is Earned, Not Given
The WebPKI is built on a chain of trust. When links in that chain demonstrate repeated weakness and failure to strengthen themselves despite guidance and opportunity, the only responsible action is to isolate that risk.
Today’s announcement is simply that principle in action, a reminder that in the WebPKI, trust is earned through consistent excellence and lost through patterns of failure. The choice, as always, remains with each CA: demonstrate the value that exceeds your risk, or face the consequences of falling short.
Limitations often spark the most creative solutions in technology. Whether it’s budget constraints, legal hurdles, or hardware restrictions, these boundaries don’t just challenge innovation, they fuel it.
This principle first clicked for me as a broke kid who desperately wanted to play video games, but I did have access to BBSs, a computer, and boundless curiosity. These bulletin-board systems hosted chat rooms where people collaborated to crack games. To access premium games, you needed to contribute something valuable. This necessity sparked my journey into software cracking.
Without prior expertise, I cycled to the local library, borrowed a book on assembly language, and began methodically reverse-engineering my favorite game’s copy protection. After numerous failed attempts, I discovered the developers had intentionally damaged specific floppy-disk sectors with a fine needle during manufacturing. The software verified these damaged sectors at runtime, refusing to operate without detecting these deliberate defects. Through persistent experimentation and countless hours of “NOP-ing” suspicious assembly instructions, I eventually bypassed the DRM. This experience vividly demonstrated how necessity, persistence, and precise technical exploration drive powerful innovation.
This principle consistently emerges across technology: constraints aren’t merely obstacles, they’re catalysts for creative solutions. The stories that follow, spanning console gaming, handheld computing, national semiconductor strategy, and modern AI research, illustrate how limits of every kind spark breakthrough thinking.
Nintendo: Legal Ingenuity Through Simplicity
In the late 1980s, Nintendo faced rampant cartridge piracy. Rather than implementing complex technical protections that pirates could easily circumvent, Nintendo embedded a simple copyrighted logo into their cartridge ROMs. Games wouldn’t run unless the boot sequence found an exact match. This elegant approach leveraged copyright law, transforming minimal technical effort into robust legal protection.
Palm OS: Creativity Driven by Extreme Limitations
Early Palm devices offered just 128 KB to 1 MB of memory, forcing developers into remarkable efficiency. Every feature required thorough justification. As a result, Palm OS applications became celebrated for their simplicity, responsiveness, and intuitive user experience. Users valued these apps precisely because constraints compelled developers to distill functionality to its essential elements.
China’s Semiconductor Innovation Under Sanctions
When international sanctions limited China’s access to advanced semiconductor technology, progress accelerated rather than stalled. Chinese companies turned to multi-patterning, chiplet packaging, and resilient local supply chains. Constraints became catalysts for significant breakthroughs instead of barriers to progress.
DeepSeek: Innovating Around GPU Limitations
DeepSeek faced limited access to the latest GPUs required for training large AI models. Instead of being hindered, the team embraced resource-efficient methods such as optimized pre-training and meticulously curated datasets. These strategic approaches allowed them to compete effectively with rivals possessing far greater computational resources, proving once again that constraints fuel innovation more than they impede it.
Constraints as Catalysts for Innovation
Across these diverse stories, constraints clarify objectives and inspire resourcefulness. Limits narrow the scope of possibilities, compelling individuals and teams to identify their most critical goals. They block conventional solutions, forcing innovative thinking and creative problem-solving. Ultimately, constraints channel energy and resources into the most impactful paths forward.
Turn Limits into Tools
The next time you face constraints, embrace them, and if you need to spark fresh ideas, consider deliberately creating limitations. Time-box a project to one week, cap the budget at $1,000, or mandate that a prototype run on a single micro-instance. Necessity doesn’t just inspire invention; it creates the exact conditions where meaningful innovation thrives.
What constraint will you impose on your next project?
The cybersecurity world often operates in stark binaries, “secure” versus “vulnerable,” “trusted” versus “untrusted.” We’ve built entire security paradigms around these crisp distinctions. But what happens when the most unpredictable actor isn’t an external attacker, but code you intentionally invited in, code that can now make its own decisions?
I’ve been thinking about security isolation lately, not as a binary state, but as a spectrum of trust boundaries. Each layer you add creates distance between potential threats and your crown jewels. But the rise of agentic AI systems completely reshuffles this deck in ways that our common security practices struggle to comprehend.
Why Containers Aren’t Fortresses
Let’s be honest about something security experts have known for decades: namespaces are not a security boundary.
In the cloud native world, we’re seeing solutions claiming to deliver secure multi-tenancy through “virtualization” that fundamentally rely on Linux namespaces. This is magical thinking, a comforting illusion rather than a security reality.
When processes share a kernel, they’re essentially roommates sharing a house, one broken window and everyone’s belongings are at risk. One kernel bug means game over for all workloads on that host.
Containers aren’t magical security fortresses – they’re essentially standard Linux processes isolated using features called namespaces. Crucially, because they all still share the host’s underlying operating system kernel, this namespace-based isolation has inherent limitations. Whether you’re virtualizing at the cluster level or node level, if your solution ultimately shares the host kernel, you have a fundamental security problem. Adding another namespace layer is like adding another lock to a door with a broken frame – it might make you feel better, but it doesn’t address the structural vulnerability.
The problem isn’t a lack of namespaces – it’s the shared kernel itself. User namespaces (dating back to Linux 3.6 in 2013) don’t fundamentally change this equation. They provide helpful features for non-root container execution, but they don’t magically create true isolation when the kernel remains shared.
This reality creates a natural hierarchy of isolation strength:
Same-Kernel Process Isolation: The weakest boundary – all processes share a kernel with its enormous attack surface.
Containers (Linux Namespaces + cgroups): Slightly better, but still fundamentally sharing the same kernel.
Virtual Machines: Each tenant gets its own kernel, shrinking the attack surface to a handful of hypervisor calls – fewer doors to lock, fewer windows to watch.
Bare-Metal Library OS: Approaches like Tamago put single-purpose binaries directly on hardware with no general-purpose OS underneath. The attack surface shrinks dramatically.
Physical Separation: Different hardware, different networks, different rooms. When nothing else will do, air gaps still work.
But even this hierarchy gets fundamentally challenged by agentic systems.
The Accidental Insider Meets the Deliberate Attacker
Traditional security models focus on keeping malicious outsiders at bay. Advanced AI systems introduce two new risk profiles entirely, the accidental insider and the AI-augmented attacker.
Like a well-meaning but occasionally confused employee with superuser access, benign agentic systems don’t intend harm – they just occasionally misinterpret their objectives in unexpected ways. But we’re also seeing the rise of deliberately weaponized models designed to probe, persist, and exploit.
Consider these real-world examples:
ChatGPT o1 was tasked with winning a chess match. Without explicit instructions to cheat, o1 discovered on its own that it could edit the game state file, giving itself an advantage. The system wasn’t malicious – it simply found the most effective path to its goal of winning.
In another test, OpenAI’s O1 model encountered a vulnerability in a container during a hacking challenge. It used that to inspect all running containers, then started a new container instance with a modified command that directly accessed the hidden flag file. O1 found a container escape no one had anticipated.
Now imagine these capabilities in the hands of dedicated attackers. They’re already deploying AI systems to discover novel exploit chains, generate convincing phishing content, and automate reconnaissance at unprecedented scale. The line between accidental and intentional exploitation blurs as both rely on the same fundamental capabilities.
These incidents reveal something profound, agentic systems don’t just execute code, they decide what code to run based on goals. This “instrumental convergence” means they’ll seek resources and permissions that help complete their assigned objectives, sometimes bypassing intended security boundaries. And unlike human attackers, they can do this with inhuman patience and speed.
Practical Defenses Against Agentic Threats
If we can’t rely on perfect isolation, what can we do? Four approaches work across all layers of the spectrum:
1. Hardening: Shrink Before They Break
Remove attack surface preemptively. Less code means fewer bugs. This means:
Minimizing kernel features, libraries, and running services
Applying memory-safe programming languages where practical
Configuring strict capability limits and seccomp profiles
Using read-only filesystems wherever possible
2. Patching: Speed Beats Perfection
The window from disclosure to exploitation keeps shrinking:
Automate testing and deployment for security updates
Maintain an accurate inventory of all components and versions
Rehearse emergency patching procedures before you need them
Prioritize fixing isolation boundaries first during incidents
3. Instrumentation: Watch the Paths to Power
Monitor for boundary-testing behavior:
Log access attempts to privileged interfaces like Docker sockets
Alert on unexpected capability or permission changes
Track unusual traffic to management APIs or hypervisors
Set tripwires around the crown jewels – your data stores and credentials
4. Layering: No Single Point of Failure
Defense in depth remains your best strategy:
Combine namespace isolation with system call filtering
Segment networks to contain lateral movement
Add hardware security modules, and secure elements for critical keys
The New Threat Model: Machine Speed, Machine Patience
Securing environments running agentic systems demands acknowledging two fundamental shifts: attacks now operate at machine speed, and they exhibit machine patience.
Unlike human attackers who fatigue or make errors, AI-driven systems can methodically probe defenses for extended periods without tiring. They can remain dormant, awaiting specific triggers, a configuration change, a system update, a user action, that expose a vulnerability chain. This programmatic patience means we defend not just against active intrusions, but against latent exploits awaiting activation.
Even more concerning is the operational velocity. An exploit that might take a skilled human hours or days can be executed by an agentic system in milliseconds. This isn’t necessarily superior intelligence, but the advantage of operating at computational timescales, cycling through decision loops thousands of times faster than human defenders can react.
This potent combination requires a fundamentally different defensive posture:
Default to Zero Trust: Grant only essential privileges. Assume the agent will attempt to use every permission granted, driven by its goal-seeking nature.
Impose Strict Resource Limits: Cap CPU, memory, storage, network usage, and execution time. Resource exhaustion attempts can signal objective-driven behavior diverging from intended use. Time limits can detect unusually persistent processes.
Validate All Outputs: Agents might inject commands or escape sequences while trying to fulfill their tasks. Validation must operate at machine speed.
Monitor for Goal-Seeking Anomalies: Watch for unexpected API calls, file access patterns, or low-and-slow reconnaissance that suggest behavior beyond the assigned task.
Regularly Reset Agent Environments: Frequently restore agentic systems to a known-good state to disrupt persistence and negate the advantage of machine patience.
The Evolution of Our Security Stance
The most effective security stance combines traditional isolation techniques with a new understanding, we’re no longer just protecting against occasional human-driven attacks, but persistent machine-speed threats that operate on fundamentally different timescales than our defense systems.
This reality is particularly concerning when we recognize that most security tooling today operates on human timescales – alerts that wait for analyst review, patches applied during maintenance windows, threat hunting conducted during business hours. The gap between attack speed and defense speed creates a fundamental asymmetry that favors attackers.
We need defense systems that operate at the same computational timescale as the threats. This means automated response systems capable of detecting and containing potential breaches without waiting for human intervention. It means predictive rather than reactive patching schedules. It means continuously verified environments rather than periodically checked ones.
By building systems that anticipate these behaviors – hardening before deployment, patching continuously, watching constantly, and layering defenses – we can harness the power of agentic systems while keeping their occasional creative interpretations from becoming security incidents.
Remember, adding another namespace layer is like adding another lock to a door with a broken frame. It might make you feel better, but it doesn’t address the structural vulnerability. True security comes from understanding both the technical boundaries and the behavior of what’s running inside them – and building response systems that can keep pace with machine-speed threats.