The conversation on short-lived certificates and their value continues. In the most recent conversation, we have started to shift from an either or position to one where we explore what is needed to make revocation checking a viable technology, this is a topic I am passionate about.
That said, there still seems to be some confusion on short-lived certificates, specifically the author states:
Of course, the cost of short-lived certs is very high as change the whole computing infrastructure so that certificates are renewed on a daily basis (daily for it to be secure enough vs 90 day certificates in my view) and introduce this new moving part that might cause vulnerability and operational issues.
Let’s explore this “cost” argument for a moment. First, when I issue an end-entity certificate I minimally have to perform two cryptographic signatures, one on the certificate and one on the OCSP response (it’s actually more than this in some cases but to keep the conversation simple I have omitted the others).
If we look at the performance optimization that Firefox has implemented where they do not require revocation checking when the certificate is within a subset the resolution of the revocation period short-lived certificates can, in fact, reduce the cost for a CA. This is because you no longer need to sign two things during the first few days/hours of the life of the certificate and you do not need to distribute that response.
The only way I think short lived certificates are more expensive for the CA is if you compare a model of certificates issued for a period better measured in hours to a model with certificate validity measured in years providing weekly revocation updates. This, however, is a bad model, and something in-between is needed.
The author also believes the use of automation represents a security vulnerability, so this deserves a response. It is true that complexity is the enemy of security, it is even true that automation can if poorly implemented can hurt security. The inverse is also true, however. It is also generally accepted that availability is a component of security and one of the more common problems in the WebPKI is poor manual management practices resulting in the lack of understanding what is deployed and those certificates that are deployed expiring [see 1,2,3, and 4] and taking down services.
It is also important to look at the big picture when evaluating the net-security benefits of automation, for example, does anyone honestly believe we would ever get to a world where the majority of the web is encrypted if organizations have to staff people to manually generate certificate requests and hand carry them to CAs? Is the net-benefit of automation of reliability and scope of deployment worth its secondary effects?
The author also suggests that a certificate must have a validity period of only a day to be “secure enough”. This seems both arbitrary and wrong, as stated previously the User Agents and WebTrust allows an OCSP response or CRL can be a week old and still be trusted.
One of the largest reasons for this is that clock skew is a big problem in the real world and as a result, you need to keep validity periods of certificates and revocation messages outside this skew period to prevent skew related failures.
The decision to define “secure enough” at a day, both defines the problem in an intractable way and furthermore ignores the fact that it establishes a double standard that does nothing to address the issue if stale revocation information.
If we were to bring this conversation back to how we improve certificate revocation I would say there should be one standard for how recent the client’s understanding of the certificate’s validity would need to be.
On that topic, the author goes on to discuss how 32 bytes is better than 470 (the size of the smallest OCSP response). I could not agree more about this, in fact in the 90s’ when I was at Valicert we implemented a proposal from Paul Kocher called Certificate Revocation Trees. This approach uses of Merkle Trees (the heart of the Bitcoin ledger) to provide a very space efficient solution to this problem. Unfortunately, we were unable to popularize this at the time.
Ben Laurie began work on a variation on this approach that leveraged sparse Merkle Trees that he called Revocation Transparency. I personally like the idea of this approach because it leverages the work done to make Certificate Transparency scalable. For example, Trillian, the foundational server for Google’s next generation log server is designed to scale to Trillions of certificates.
That said, there are a number of similar approaches that could be equally scalable.
While I do think that an approach similar to the above could be made to work today, I also think it is more of a long-term solution in that even with the significantly increased rate of technological adoption it would take close to ten years given the state of things for such a solution to be fully deployed if we started right now.
As such I would start with the problem definition, which would need to involve a more formal analysis of the role of revocation checking today so that the right solution was built.
In parallel I would want to see the industry adopt a more strategic plan to address the more practical and immediately solvable problems, including:
- Measuring and improving the revocation infrastructure operated by CAs,
- Establishing global performance and reliability metrics and reporting that all CAs must meet,
- Funding improvements to Nginx and Apache’s OCSP Stapling implementations,
- Working with browsers to adopt the performance optimization firefox has implemented for revocation checking,
- Working with TLS stacks, User Agents, Servers and Service Providers to adopt OCSP Must-Staple,
- Defining an OCSP transport based on DNS that would reduce dependency on CA infrastructure reliability,
- Evangalizing the adoption of OCSP stapling with administrators.

Ryan
P.S.
The author also has also added in someone else who has asked some questions or more correctly seems to question my version of the historical narrative. To provide some context, my narrative comes from my practical experience working with Microsoft, eBay, Amazon, and other large companies in the mid to late 90s and through the mid-2000s.
I too have worked with the BBN Safekeeper, I have a fun story how we hired some people to extract the keys from one of these boxes I would be happy to share over a beer sometime.
However, a cool device, the first one I remember working with was the KOV-8 in the 1993/4 timeframe.
Anyway, it is true that SSL started its life in 1994/5 at which point only software implementations of crypto were used (they were all BSAFE) but it is also true that mass deployment of SSL (relatively speaking) did not start until the late 90s and early 00s and that is the time my narrative was based on.
He also has also questioned the narrative of what Windows supported in the context of key protection. Since the author knows me personally he must have simply forgotten that I was the PM for these technologies and was at Microsoft working in this area for about 15 years.
Again I think there is some confusion here, the author states:
The software based Cryptographic Service Provider for RSA allowed keys to be marked ‘not for export’ from a very early release if not the first.
and:
The CAPI features used to protect private keys were expanded and exposed as a separate API in Windows 2000 as the Data Protection API.
As someone who worked at Microsoft on these technologies for a long time I can say with absolute confidence they were not built to provide key isolation, do not provide key isolation properties and were actually not used by the SSL implementation (SCHANNEL) for the server keys. If you’re interested in learning more about the capabilities of Windows in this area check out this post I did recently.
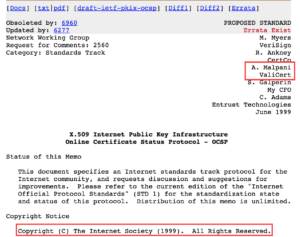
He has also questioned the role of ValiCert in the definition of the RFC, thankfully the IETF PKIX archives are still there and if you care to look you can see Mike was basically checked out, Warwick was not publicly paticipating and the work to finalize the protocol was largely done by Ambarish Malpani the founder of Valicert.