I have been having a conversation with Melhi at Comodo, this is the most recent post in that series.
First of all, the author is unaware that my company has built the most sophisticated Certificate Management system that can automatically request, issue, renew and manage the whole lifecycle of the certificate. Many Fortune 500 companies rely on this amazing technology to manage their PKI infrastructure.
I am aware.
So it is with that expertise and insight I must insist that the author does not appreciate the nuance between “high frequency” renewal vs “low frequency” renewals. Short lived certs will require “high frequency” renewal system. To an IT admin this is a scary prospect! They tell us that!
Having been responsible for and or worked heavly on:
- The Valicert OCSP responder and clients,
- The Windows CA and the enrollment client at Microsoft, which is the most used CA software ever,
- The Network Access Protection solution that used IPSEC and ~12-hour certificates to do segmentation of hosts at the IP layer and their health. based network isolation solution that was deployed into many of the Fortune 500,
- All of GlobalSign’s technology offerings, in particular, the technology enabling their expansion into the Enterprise,
- Helping the ISRG build out Let’s Encrypt,
- Designing, building and operating numerous other high volume products and services in finance, healthcare, and government.
Above and beyond that I helped secure Bing Ads and Live ID and now work at Google on other very high scale systems.
Needless to say, I too have familiarity with “high frequency”, “low frequency”, “disaster recovery” and “availability” problems.
As for fear, it is a natural part of life, I believe it was Nelson Mandela who famously said: Courage is not the absence of fear but the triumph over it.
The reality is that it is manual certificate lifecycle management that is the thing to be afraid of. That is why COMODO and other CAs have been building out cloud-based management and automation solutions over the last few years. For customers this reduces failure, reduces costs, gives more control, and nets higher customer satisfaction.
Importantly, one needs to remember it is manual processes that lead to the majority of outages [see 1,2,3, and 4]. The scale of this problem has even led to an entire market segment dedicated to managing the lifecycle of WebPKI certificates.
So to the question of fear, I would say the same thing my father told me, though change can be scary and uncomfortable in the short term, it usually turns out okay in the end, and often better.
I believe there can be a scalable revocation infrastructure that can serve status for all certs from all CAs that is backward compatible with existing issued certificates that can be called from a browser. As I said before I do believe in the ingenuity of our scientist and engineers to bring us this solution……soon….
You misunderstand me. I did not say it was impossible to have a scalable revocation infrastructure that is backward compatible. I said the creation of a new system that could deliver on the small message size promise we were discussing would take 10 years to design, build and deploy.
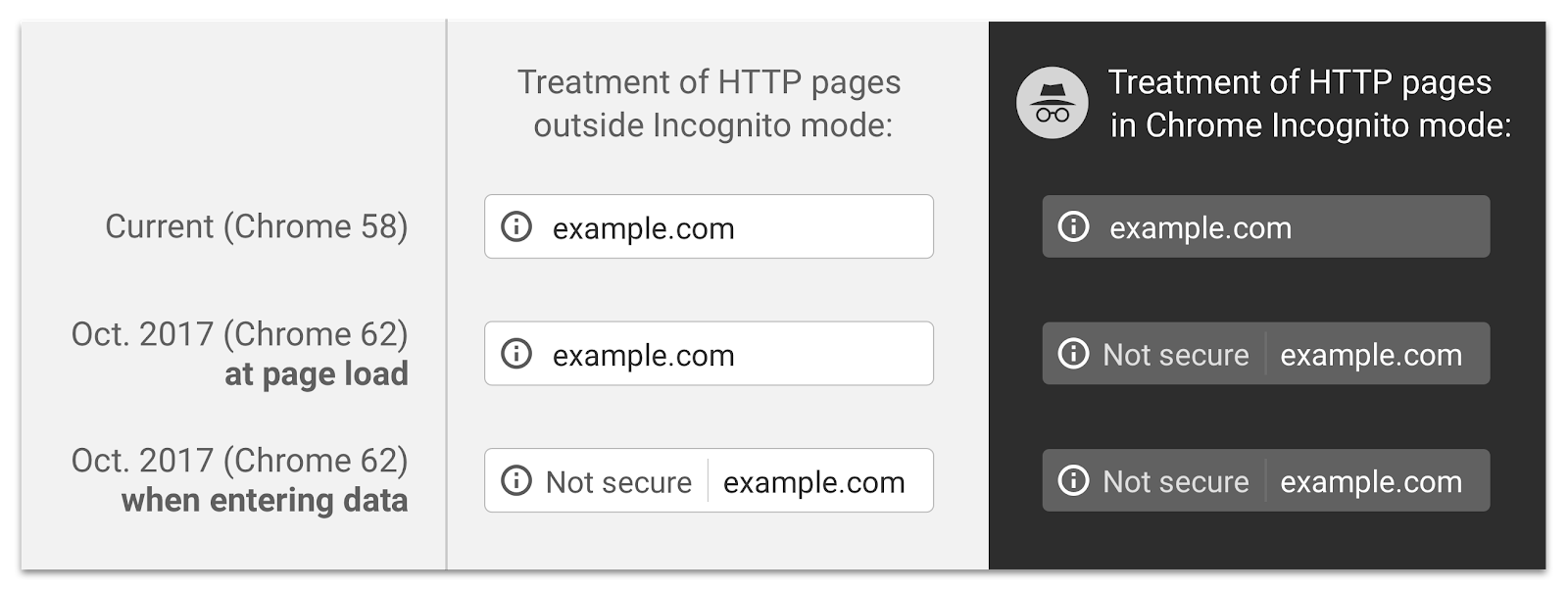
To understand my rational take a look at this post. It is a little old now, and update rates are a faster now but not massively. When you review it you will see that if you exclude IE/Edge it takes just under a year for a new version of the most common browsers to reach 90% market share.
To put that in a more concrete way, if today, Chrome, Firefox, and Safari decided to simultaneously release a new version with a new revocation scheme it would take a bit less than a year for us to see 90% deployment. That is, of course, an unrealistic goal. Apple, for example only releases new versions a few times a year and does not even support WebRTC yet. Additionally, browsers have a pretty deep-seated position on revocation checking at this point given all the problems of the past so convince them will take time.
A more realistic, but still optimistic period assuming pre-existing consensus and a will to solve the problem is 5 to 6 years. If you question this figure, just look at how long it took for TLS 1.2 to get deployed. TLS 1.2 was published in 2008 and was not enabled by default in Windows until Windows 8.1 in 2014.
Web servers are even worse, as an example consider Apache version 2 was released in 2002 and these later versions still have less than 50% deployment.
Lets call it DCSP 😉

DCSP isn’t a bad idea, but it has its own challenges. For example, some that come at the top of mind are:
- Most browsers do not ship their own DNS clients, this is one of the problems DNSSEC had in deployment. If the operating system DNS APIs they use do not provide the information they need then they can not adopt any technology depend on it.
- Middleboxes and captive networks make DNS-based distribution problematic. Again DNSSEC suffered from this.
- If DCSP requires a custom record type, for example, DNS servers and tooling will need to be updated. DNS servers also do not get updated regularly, this is another thing that has held back DNSSEC as well as CAA. It is fair to say that it is fair for the WebPKI CAs to update their DNS but based on the glacial pace in which CAs adopt technology that is 3-4 years before you could see deployment even with that (see CT as an example).
To be clear, I think something like this is worth exploring but I don’t think it will see meaningful deployment in the near term.
If we were in Vegas, I would say the most expedient path is to build on what is there, while in parallel building the new thing. This can shave as much as 5 years off the time it takes to solve the problem. If nothing else this moves the CA ecosystem closer to an operational maturity capable of supporting the new system.
Ryan