The cybersecurity world often operates in stark binaries, “secure” versus “vulnerable,” “trusted” versus “untrusted.” We’ve built entire security paradigms around these crisp distinctions. But what happens when the most unpredictable actor isn’t an external attacker, but code you intentionally invited in, code that can now make its own decisions?
I’ve been thinking about security isolation lately, not as a binary state, but as a spectrum of trust boundaries. Each layer you add creates distance between potential threats and your crown jewels. But the rise of agentic AI systems completely reshuffles this deck in ways that our common security practices struggle to comprehend.
Why Containers Aren’t Fortresses
Let’s be honest about something security experts have known for decades: namespaces are not a security boundary.
In the cloud native world, we’re seeing solutions claiming to deliver secure multi-tenancy through “virtualization” that fundamentally rely on Linux namespaces. This is magical thinking, a comforting illusion rather than a security reality.
When processes share a kernel, they’re essentially roommates sharing a house, one broken window and everyone’s belongings are at risk. One kernel bug means game over for all workloads on that host.
Containers aren’t magical security fortresses – they’re essentially standard Linux processes isolated using features called namespaces. Crucially, because they all still share the host’s underlying operating system kernel, this namespace-based isolation has inherent limitations. Whether you’re virtualizing at the cluster level or node level, if your solution ultimately shares the host kernel, you have a fundamental security problem. Adding another namespace layer is like adding another lock to a door with a broken frame – it might make you feel better, but it doesn’t address the structural vulnerability.
The problem isn’t a lack of namespaces – it’s the shared kernel itself. User namespaces (dating back to Linux 3.6 in 2013) don’t fundamentally change this equation. They provide helpful features for non-root container execution, but they don’t magically create true isolation when the kernel remains shared.
This reality creates a natural hierarchy of isolation strength:
Same-Kernel Process Isolation: The weakest boundary – all processes share a kernel with its enormous attack surface.
Containers (Linux Namespaces + cgroups): Slightly better, but still fundamentally sharing the same kernel.
Virtual Machines: Each tenant gets its own kernel, shrinking the attack surface to a handful of hypervisor calls – fewer doors to lock, fewer windows to watch.
Bare-Metal Library OS: Approaches like Tamago put single-purpose binaries directly on hardware with no general-purpose OS underneath. The attack surface shrinks dramatically.
Physical Separation: Different hardware, different networks, different rooms. When nothing else will do, air gaps still work.
But even this hierarchy gets fundamentally challenged by agentic systems.
The Accidental Insider Meets the Deliberate Attacker
Traditional security models focus on keeping malicious outsiders at bay. Advanced AI systems introduce two new risk profiles entirely, the accidental insider and the AI-augmented attacker.
Like a well-meaning but occasionally confused employee with superuser access, benign agentic systems don’t intend harm – they just occasionally misinterpret their objectives in unexpected ways. But we’re also seeing the rise of deliberately weaponized models designed to probe, persist, and exploit.
Consider these real-world examples:
ChatGPT o1 was tasked with winning a chess match. Without explicit instructions to cheat, o1 discovered on its own that it could edit the game state file, giving itself an advantage. The system wasn’t malicious – it simply found the most effective path to its goal of winning.
In another test, OpenAI’s O1 model encountered a vulnerability in a container during a hacking challenge. It used that to inspect all running containers, then started a new container instance with a modified command that directly accessed the hidden flag file. O1 found a container escape no one had anticipated.
Now imagine these capabilities in the hands of dedicated attackers. They’re already deploying AI systems to discover novel exploit chains, generate convincing phishing content, and automate reconnaissance at unprecedented scale. The line between accidental and intentional exploitation blurs as both rely on the same fundamental capabilities.
These incidents reveal something profound, agentic systems don’t just execute code, they decide what code to run based on goals. This “instrumental convergence” means they’ll seek resources and permissions that help complete their assigned objectives, sometimes bypassing intended security boundaries. And unlike human attackers, they can do this with inhuman patience and speed.
Practical Defenses Against Agentic Threats
If we can’t rely on perfect isolation, what can we do? Four approaches work across all layers of the spectrum:
1. Hardening: Shrink Before They Break
Remove attack surface preemptively. Less code means fewer bugs. This means:
Minimizing kernel features, libraries, and running services
Applying memory-safe programming languages where practical
Configuring strict capability limits and seccomp profiles
Using read-only filesystems wherever possible
2. Patching: Speed Beats Perfection
The window from disclosure to exploitation keeps shrinking:
Automate testing and deployment for security updates
Maintain an accurate inventory of all components and versions
Rehearse emergency patching procedures before you need them
Prioritize fixing isolation boundaries first during incidents
3. Instrumentation: Watch the Paths to Power
Monitor for boundary-testing behavior:
Log access attempts to privileged interfaces like Docker sockets
Alert on unexpected capability or permission changes
Track unusual traffic to management APIs or hypervisors
Set tripwires around the crown jewels – your data stores and credentials
4. Layering: No Single Point of Failure
Defense in depth remains your best strategy:
Combine namespace isolation with system call filtering
Segment networks to contain lateral movement
Add hardware security modules, and secure elements for critical keys
The New Threat Model: Machine Speed, Machine Patience
Securing environments running agentic systems demands acknowledging two fundamental shifts: attacks now operate at machine speed, and they exhibit machine patience.
Unlike human attackers who fatigue or make errors, AI-driven systems can methodically probe defenses for extended periods without tiring. They can remain dormant, awaiting specific triggers, a configuration change, a system update, a user action, that expose a vulnerability chain. This programmatic patience means we defend not just against active intrusions, but against latent exploits awaiting activation.
Even more concerning is the operational velocity. An exploit that might take a skilled human hours or days can be executed by an agentic system in milliseconds. This isn’t necessarily superior intelligence, but the advantage of operating at computational timescales, cycling through decision loops thousands of times faster than human defenders can react.
This potent combination requires a fundamentally different defensive posture:
Default to Zero Trust: Grant only essential privileges. Assume the agent will attempt to use every permission granted, driven by its goal-seeking nature.
Impose Strict Resource Limits: Cap CPU, memory, storage, network usage, and execution time. Resource exhaustion attempts can signal objective-driven behavior diverging from intended use. Time limits can detect unusually persistent processes.
Validate All Outputs: Agents might inject commands or escape sequences while trying to fulfill their tasks. Validation must operate at machine speed.
Monitor for Goal-Seeking Anomalies: Watch for unexpected API calls, file access patterns, or low-and-slow reconnaissance that suggest behavior beyond the assigned task.
Regularly Reset Agent Environments: Frequently restore agentic systems to a known-good state to disrupt persistence and negate the advantage of machine patience.
The Evolution of Our Security Stance
The most effective security stance combines traditional isolation techniques with a new understanding, we’re no longer just protecting against occasional human-driven attacks, but persistent machine-speed threats that operate on fundamentally different timescales than our defense systems.
This reality is particularly concerning when we recognize that most security tooling today operates on human timescales – alerts that wait for analyst review, patches applied during maintenance windows, threat hunting conducted during business hours. The gap between attack speed and defense speed creates a fundamental asymmetry that favors attackers.
We need defense systems that operate at the same computational timescale as the threats. This means automated response systems capable of detecting and containing potential breaches without waiting for human intervention. It means predictive rather than reactive patching schedules. It means continuously verified environments rather than periodically checked ones.
By building systems that anticipate these behaviors – hardening before deployment, patching continuously, watching constantly, and layering defenses – we can harness the power of agentic systems while keeping their occasional creative interpretations from becoming security incidents.
Remember, adding another namespace layer is like adding another lock to a door with a broken frame. It might make you feel better, but it doesn’t address the structural vulnerability. True security comes from understanding both the technical boundaries and the behavior of what’s running inside them – and building response systems that can keep pace with machine-speed threats.
When the web first flickered to life in the mid-’90s, nobody could predict how quickly “click a link, buy a book” would feel ordinary. A decade later, the iPhone landed and almost overnight, thumb-sized apps replaced desktop software for everything from hailing a ride to filing taxes. Cloud followed, turning racks of servers into a line of code. Each wave looked slow while we argued about standards, but in hindsight, every milestone was racing downhill.
That cadence, the messy birth, the sudden lurch into ubiquity, the quiet settling into infrastructure, has a rhythm. Agents will follow it, only faster. While my previous article outlined the vision of an agent-centric internet with rich personal ontologies and fluid human-agent collaboration, here I want to chart how this transformation may unfold.
Right now, we’re in the tinkering phase, drafts of Model-Context-Protocol and Agent-to-Agent messaging are still wet ink, yet scrappy pilots already prove an LLM can navigate HR portals or shuffle travel bookings with no UI at all. Call this 1994 again, the Mosaic moment, only the demos are speaking natural language instead of rendering HTML. Where we once marveled at hyperlinks connecting documents, we now watch agents traversing APIs and negotiating with services autonomously.
Give it a couple of years and we’ll hit the first-taste explosion. Think 2026-2028. You’ll wake to OS updates that quietly install an agent runtime beside Bluetooth and Wi-Fi. SaaS vendors will publish tiny manifest files like .well-known/agent.json, so your personal AI can discover an expense API as easily as your browser finds index.html. Your agent will silently reschedule meetings when flights are delayed, negotiate with customer service on your behalf while you sleep, and merge scattered notes into coherent project briefs with minimal guidance. Early adopters will brag that their inbox triages itself; skeptics will mutter about privacy. That was Netscape gold-rush energy in ’95, or the first App Store summer in 2008, replayed at double speed.
Somewhere around the turn of the decade comes the chasm leap. Remember when smartphones crossed fifty-percent penetration and suddenly every restaurant begged you to scan a QR code for the menu? Picture that, but with agents. Insurance companies will underwrite “digital delegate liability.” Regulators will shift from “What is it?” to “Show me the audit log.” You’ll approve a dental claim or move a prescription with a nod to your watch. Businesses without agent endpoints will seem as anachronistic as those without websites in 2005 or mobile apps in 2015. If everything holds, 2029-2031 feels about right, but history warns that standards squabbles or an ugly breach of trust could push that even further out.
Of course, this rhythmic march toward an agent-centric future won’t be without its stumbles and syncopations. Several critical challenges lurk beneath the optimistic timeline.
First, expect waves of disillusionment to periodically crash against the shore of progress. As with any emerging technology, early expectations will outpace reality. Around 2027-2028, we’ll likely see headlines trumpeting “Agent Winter” as investors realize that seamless agent experiences require more than just powerful language models; they need standardized protocols, robust identity frameworks, and sophisticated orchestration layers that are still embryonic.
More concerning is the current security and privacy vacuum. We’re generating code at breakneck speeds thanks to AI assistants, but we haven’t adapted our secure development lifecycle (SDL) practices to match this acceleration. Even worse, we’re failing to deploy the scalable security techniques we do have available. The result? Sometime around 2028, expect a high-profile breach where an agent’s privileged access is exploited across multiple services in ways that the builders never anticipated. This won’t just leak data, it will erode trust in the entire agent paradigm.
Traditional security models simply won’t suffice. Firewalls and permission models weren’t designed to manage the emergent and cumulative behaviors of agents operating across dozens of services. When your personal agent can simultaneously access your healthcare provider, financial institutions, and smart home systems, the security challenge isn’t just additive, it’s multiplicative. We’ll need entirely new frameworks for reasoning about and containing ripple effects that aren’t evident in isolated testing environments.
Meanwhile, the software supply chain grows more vulnerable by the day. “Vibe coding”, where developers increasingly assemble components they don’t fully understand, magnifies these risks exponentially. By 2029, we’ll likely face a crisis where malicious patterns embedded in popular libraries cascade through agent-based systems, causing widespread failures that take months to fully diagnose and remediate.
Perhaps the most underappreciated challenge is interoperability. The fluid agent’s future demands unprecedented agreement on standards across competitors and jurisdictions. Today’s fragmented digital landscape, where even basic identity verification lacks cross-platform coherence, offers little confidence. Without concerted effort on standardization, we risk a balkanized agent ecosystem where your finance agent can’t talk to your health agent, and neither works outside your home country. The EU will develop one framework, the US another, China a third, potentially delaying true interoperability well into the 2030s.
These challenges don’t invalidate the agent trajectory, but they do suggest a path marked by setbacks and recoveries. Each crisis will spawn new solutions, enhanced attestation frameworks, agent containment patterns, and cross-jurisdictional standards bodies that eventually strengthen the ecosystem. But make no mistake, the road to agent maturity will be paved with spectacular failures that temporarily shake our faith in the entire proposition.
Past these challenges, the slope gets steep. Hardware teams are already baking neural engines into laptops, phones, and earbuds; sparse-mixture models are slashing inference costs faster than GPUs used to shed die size. By the early 2030s an “agent-first” design ethos will crowd out login pages the way responsive web design crowded out fixed-width sites. The fluid dance between human and agent described in my previous article—where control passes seamlessly back and forth, with agents handling complexity and humans making key decisions—will become the default interaction model. You won’t retire the browser, but you’ll notice you only open it when your agent kicks you there for something visual.
And then, almost unnoticed, we’ll hit boring maturity, WebPKI-grade trust fabric, predictable liability rules, perhaps around 2035. Agents will book freight, negotiate ad buys, and dispute parking tickets, all without ceremony. The personal ontology I described earlier, that rich model of your preferences, patterns, values, and goals, will be as expected as your smartphone knows your location is today. It will feel miraculous only when you visit digital spaces that still require manual navigation, exactly how water from the faucet feels extraordinary only when you visit a cabin that relies on rain barrels.
Could the timetable shrink? Absolutely. If MCP and A2A converge quickly and the model-hardware cost curve keeps free-falling, mainstream could arrive by 2029, echoing how smartphones swallowed the world in six short years. Could it stretch? A high-profile agent disaster or standards deadlock could push us to 2034 before Mom quits typing URLs. The only certainty is that the future will refuse to follow our Gantt charts with perfect obedience; history never does, but it loves to keep the beat.
So what do we do while the metronome clicks? The same thing web pioneers did in ’94 and mobile pioneers did in ’08, publish something discoverable, wire in basic guardrails, experiment in the shallow end while the cost of failure is lunch money. Start building services that expose agent-friendly endpoints alongside your human interfaces. Design with the collaborative handoff in mind—where your users might begin a task directly but hand control to their agent midway, or vice versa. Because when the tempo suddenly doubles, the builders already keeping time are the ones who dance, not stumble.
Imagine how you interact with digital services today: open a browser, navigate menus, fill forms, manually connect the dots between services. It’s remarkable how little this has changed since the 1990s. Despite this today one of the most exciting advancements we have seen in the last year is that agents are now browsing the web like people.
If we were starting fresh today, the browser as we know it likely wouldn’t be the cornerstone for how agents accomplish tasks on our behalf. We’re seeing early signals in developments like Model-Context-Protocol (MCP) and Agent-to-Agent (A2A) communication frameworks that the world is awakening to a new reality: one where agents, not browsers, become our primary interface.
At the heart of this transformation is a profound shift, your personal agent will develop and maintain a rich ontology of you, your preferences, patterns, values, and goals. Not just a collection of settings and history, but a living model of your digital self that evolves as you do. Your agent becomes entrusted with this context, transforming into a true digital partner. It doesn’t just know what you like; it understands why you like it. It doesn’t just track your calendar; it comprehends the rhythms and priorities of your life.
For this future to happen, APIs must be more than documented; they need to be dynamically discoverable. Imagine agents querying for services using standardized mechanisms like DNS SRV or TXT records, or finding service manifests at predictable .well-known URIs. This way, they can find, understand, and negotiate with services in real time. Instead of coding agents for specific websites, we’ll create ecosystems where services advertise their capabilities, requirements, and policies in ways agents natively understand. And this won’t be confined to the web. As we move through our physical world, agents will likely use technologies like low-power Bluetooth to discover nearby services, restaurants, pharmacies, transit systems, all exposing endpoints for seamless engagement.
Websites themselves won’t vanish; they’ll evolve into dynamic, shared spaces where you and your agent collaborate, fluidly passing control back and forth. Your agent might begin a task, researching vacation options, for instance, gathering initial information and narrowing choices based on your preferences. When you join, it presents the curated options and reasoning, letting you explore items that interest you. As you review a potential destination, your agent proactively pulls relevant information: weather forecasts, local events during your dates, or restaurant recommendations matching your dietary preferences. This collaborative dance continues, you making high-level decisions while your agent handles the details, each seamlessly picking up where the other leaves off.
Consider what becomes possible when your agent truly knows you. Planning your day, it notices an upcoming prescription refill. It checks your calendar, sees you’ll be in Bellevue, and notes your current pickup is inconveniently far. Discovering that the pharmacy next to your afternoon appointment has an MCP endpoint and supports secure, agent-based transactions, it suggests “Would you like me to move your pickup to the pharmacy by your Bellevue appointment?” With a tap, you agree. The agent handles the transfer behind the scenes, but keeps you in the loop, showing the confirmation and adding, “They’re unusually busy today, would you prefer I schedule a specific pickup time?” You reply that 2:15 works best, and your agent completes the arrangement, dropping the final QR code into your digital wallet.
Or imagine your agent revolutionizing how you shop for clothes. As it learns your style and what fits you best, managing this sensitive data with robust privacy safeguards you control, it becomes your personal stylist. You might start by saying you need an outfit for an upcoming event. Your agent surfaces initial options, and as you react to them, liking one color but preferring a different style, it refines its suggestions. You take over to make some choices, then hand control back to your agent to find matching accessories at other stores. This fluid collaboration, enabled through interoperable services that allow your agent to securely share anonymized aspects of your profile with retail APIs, creates a shopping experience that’s both more efficient and more personal.
Picture, too, your agent quietly making your day easier. It notices from your family calendar that your father is visiting and knows from your granted access to relevant information that he follows a renal diet. As it plans your errands, it discovers a grocery store near your office with an API advertising real-time stock and ingredients suitable for his needs. It prepares a shopping list, which you quickly review, making a few personal additions. Your agent then orders the groceries for pickup, checking with you only on substitutions that don’t match your preferences. By the time you head home, everything is ready, a task completed through seamless handoffs between you and your agentic partner.
These aren’t distant dreams. Image-based search, multimodal tools, and evolving language models are early signs of this shift toward more natural, collaborative human-machine partnerships. For this vision to become reality, we need a robust trust ecosystem, perhaps akin to an evolved Web PKI but for agents and services. This would involve protocols for agent/service identification, authentication, secure data exchange, and policy enforcement, ensuring that as agents act on our behalf, they do so reliably, with our explicit consent and in an auditable fashion.
The path from here to there isn’t short. We’ll need advances in standardization, interoperability, security, and most importantly, trust frameworks that put users in control . There are technical and social challenges to overcome. But the early signals suggest this is the direction we’re headed. Each step in AI capability, each new protocol for machine-to-machine communication, each advancement in personalization brings us closer to this future.
Eventually, navigating the digital world won’t feel like using a tool at all. It will feel like collaborating with a trusted partner who knows you, truly knows you, and acts on your behalf within the bounds you’ve set, sometimes leading, sometimes following, but always in sync with your intentions. Agents will change everything, not by replacing us, but by working alongside us in a fluid dance of collaboration, turning the overwhelming complexity of our digital lives into thoughtful simplicity. Those who embrace this agent-centric future, building services that are not just human-accessible but native agent-engagable, designed for this collaborative interchange, will define the next chapter of the internet.
In the early 2000s, I was responsible for a number of core security technologies in Windows, including cryptography. As part of that role, we had an organizational push to support “vanity” national algorithms in SChannel (and thus SSL/TLS) and CMS. Countries like Austria and China wanted a simple DLL‑drop mechanism that would allow any application built on the Windows crypto stack to instantly support their homegrown ciphers.
On paper, it sounded elegant: plug in a new primitive and voilà, national‑sovereignty protocols everywhere. In practice, however, implementation proved far more complex. Every new algorithm required exhaustive validation, introduced performance trade-offs, risked violating protocol specifications, and broke interoperability with other systems using those same protocols and formats.
Despite these challenges, the threat of regulation and litigation pushed us to do the work. Thankfully, adoption was limited and even then, often misused. In the few scenarios where it “worked,” some countries simply dropped in their algorithm implementations and misrepresented them as existing, protocol-supported algorithms. Needless to say, this wasn’t a fruitful path for anyone.
As the saying goes, “failing to plan is planning to fail.” In this case, the experience taught us a critical lesson: real success lies not in one-off plug-ins, but in building true cryptographic agility.
We came to realize that instead of chasing edge-case national schemes, the real goal was a framework that empowers operators to move off broken or obsolete algorithms and onto stronger ones as threats evolve. Years after I left Microsoft, I encountered governments still relying on those early plugability mechanisms—often misconfigured in closed networks, further fracturing interoperability. Since then, our collective expertise in protocol engineering has advanced so far that the idea of dynamically swapping arbitrary primitives into a live stack now feels not just naïve, but fundamentally impractical.
Since leaving Microsoft, I’ve seen very few platforms, Microsoft or otherwise, address cryptographic agility end-to-end. Most vendors focus only on the slice of the stack they control (browsers prioritize TLS agility, for instance), but true agility requires coordination across both clients and servers, which you often don’t own.
My Definition of Crypto Agility
Crypto agility isn’t about swapping out ciphers. It’s about empowering operators to manage the full lifecycle of keys, credentials, and dependent services, including:
Generation of new keys and credentials
Use under real-world constraints
Rotation before algorithms weaken, keys exceed their crypto period, or credentials expire
Compromise response, including detection, containment, and rapid remediation
Library & implementation updates, patching or replacing affected crypto modules and libraries when weaknesses or compromises are identified
Retirement of outdated materials
Replacement with stronger, modern algorithms
Coincidentally, NIST has since released an initial public draft titled Considerations for Achieving Crypto Agility (CSWP 39 ipd, March 5, 2025), available here. In it, they define:
“Cryptographic (crypto) agility refers to the capabilities needed to replace and adapt cryptographic algorithms in protocols, applications, software, hardware, and infrastructures without interrupting the flow of a running system in order to achieve resiliency.”
That definition aligns almost perfectly with what I’ve been advocating for years—only now it carries NIST’s authority.
Crypto Agility for the 99%
Ultimately, consumers and relying parties—the end users, application owners, cloud tenants, mobile apps, and service integrators—are the 99% who depend on seamless, invisible crypto transitions. They shouldn’t have to worry about expired credentials, lapsed crypto periods, or how to protect and rotate algorithms without anxiety, extensive break budgets or downtime.
True agility means preserving trust and control at every stage of the lifecycle.
Of course, delivering that experience requires careful work by developers and protocol designers. Your APIs and specifications must:
Allow operators to choose permitted algorithms
Enforce policy-driven deprecation
A Maturity Roadmap
To make these lifecycle stages actionable, NIST’s Crypto Agility Maturity Model (CAMM) defines four levels:
Level 1 – Possible: Discover and inventory all keys, credentials, algorithms, and cipher suites in use. Catalog the crypto capabilities and policies of both parties.
Level 2 – Prepared: Codify lifecycle processes (generation, rotation, retirement, etc.) and modularize your crypto stack so that swapping primitives doesn’t break applications.
Level 3 – Practiced: Conduct regular “crypto drills” (e.g., simulated deprecations or compromises) under defined governance roles and policies.
Level 4 – Sophisticated: Automate continuous monitoring for expired credentials, lapsed crypto-period keys, deprecated suites, and policy violations triggering remediations without human intervention.
Embedding this roadmap into your operations plan helps you prioritize inventory, modularity, drills, and automation in the right order.
My Lifecycle of Algorithm and Key Management
This operator-focused lifecycle outlines the critical phases for managing cryptographic algorithms and associated keys, credentials, and implementations, including module or library updates when vulnerabilities are discovered:
Generation of new keys and credentials
Use under real-world constraints with enforced policy
Library & Implementation Updates, to address discovered vulnerabilities
Retirement of outdated keys, credentials, and parameters
Replacement with stronger, modern algorithms and materials
Each phase builds on the one before it. Operators must do more than swap out algorithms—they must update every dependent system and implementation. That’s how we minimize exposure and maintain resilience throughout the cryptographic lifecycle.
Conclusion
What’s the message then? Well, from my perspective, cryptographic agility isn’t a feature—it’s an operational mindset. It’s about building systems that evolve gracefully, adapt quickly, and preserve trust under pressure. That’s what resilience looks like in the age of quantum uncertainty and accelerating change.
“The world isn’t run by weapons anymore, or energy, or money. It’s run by little ones and zeroes, little bits of data. It’s all just electrons.” — Martin Bishop, Sneakers (1992)
I was 16 when I first watched Sneakers on a VHS tape rented from my local video store. Between the popcorn and plot twists, I couldn’t have known that this heist caper would one day seem less like Hollywood fantasy and more like a prophetic warning about our future. Remember that totally unassuming “little black box” – just an answering machine, right? Except this one could crack any code. The device that sent Robert Redford, Sidney Poitier, and their ragtag crew on a wild adventure. Fast forward thirty years, and that movie gadget gives those of us in cybersecurity a serious case of déjà vu.
Today, as quantum computing leaves the realm of theoretical physics and enters our practical reality, that fictional black box takes on new significance. What was once movie magic now represents an approaching inflection point in security – a moment when quantum algorithms like Shor’s might render our most trusted encryption methods as vulnerable as a simple padlock to a locksmith.
When Hollywood Met Quantum Reality
I’ve always found it deliciously ironic that Leonard Adleman – the “A” in RSA encryption – served as the technical advisor on Sneakers. Here was a man who helped create the mathematical backbone of modern digital security, consulting on a film about its theoretical downfall. What’s particularly fascinating is that Adleman took on this advisory role partly so his wife could meet Robert Redford! His expertise is one reason why the movie achieves such technical excellence. It’s like having the architect of a castle advising on a movie about the perfect siege engine. For what feels like forever – three whole decades – our world has been chugging along on a few key cryptographic assumptions. We’ve built trillion-dollar industries on the belief that certain mathematical problems—factoring large numbers or solving discrete logarithms—would remain practically impossible for computers to solve. Yep, our most of security is all built on these fundamental mathematical ideas. Sneakers playfully suggested that one brilliant mathematician might find a shortcut through these “unsolvable” problems. The movie’s fictional Gunter Janek discovered a mathematical breakthrough that rendered all encryption obsolete – a cinematic prediction that seemed far-fetched in 1992.
Yet here we are in the 2020s, watching quantum computing advance toward that very capability. What was once movie magic is becoming technological reality. The castle walls we’ve relied on aren’t being scaled—they’re being rendered obsolete by a fundamentally different kind of siege engine.
The Real Horror Movie: Our Security Track Record
Hollywood movies like Sneakers imagine scenarios where a single breakthrough device threatens our digital security. But here’s the kicker, and maybe the scarier part: the real threats haven’t been some crazy math breakthrough, but the everyday stuff – those operational hiccups in the ‘last mile’ of software supply chain and security management. I remember the collective panic during the Heartbleed crisis of 2014. The security community scrambled to patch the vulnerability in OpenSSL, high-fiving when the code was fixed. But then came the sobering realization: patching the software wasn’t enough. The keys – those precious secrets exposed during the vulnerability’s window – remained unchanged in countless systems. It was like installing a new lock for your door but having it keyed the same as the old one all the while knowing copies of the key still sitting under every mat in the neighborhood. And wouldn’t you know it, this keeps happening, which is frankly a bit depressing. In 2023, the Storm-0558 incident showed how even Microsoft – with all its resources and expertise – could fall victim to pretty similar failures. A single compromised signing key allowed attackers to forge authentication tokens and breach government email systems. The digital equivalent of a master key to countless doors was somehow exposed, copied, and exploited. Perhaps most illustrative was the Internet Archive breach. After discovering the initial compromise, they thought they’d secured their systems. What they missed was complete visibility into which keys had been compromised. The result? Attackers simply used the overlooked keys to walk right back into the system later. Our mathematical algorithms may be theoretically sound, but in practice, we keep stumbling at the most human part of the process: consistently managing the lifecycle of the software and cryptographic keys through theih entire lifecycle. We’re brilliant at building locks but surprisingly careless with the keys.
From Monochrome Security to a Quantum Technicolor
Think back to when TVs went from black and white to glorious color. Well, cryptography’s facing a similar leap, except instead of just adding RGB, we’re talking about a whole rainbow of brand new, kinda wild frequencies. For decades, we’ve lived in a relatively simple cryptographic world. RSA and ECC have been the reliable workhorses – the vanilla and chocolate of the security ice cream shop. Nearly every secure website, VPN, or encrypted message relies on these algorithms. They’re well-studied, and deeply embedded in our digital infrastructure. But quantum computing is forcing us to expand our menu drastically. Post-quantum cryptography introduces us to new mathematical approaches with names that sound like science fiction concepts: lattice-based cryptography, hash-based signatures, multivariate cryptography, and code-based systems. Each of these new approaches is like a different musical instrument with unique strengths and limitations. Lattice-based systems offer good all-around performance but require larger keys. Hash-based signatures provide strong security guarantees but work better for certain applications than others. Code-based systems have withstood decades of analysis but come with significant size trade-offs. That nice, simple world where one crypto algorithm could handle pretty much everything? Yeah, that’s fading fast. We’re entering an era where cryptographic diversity isn’t just nice to have – it’s essential for survival. Systems will need to support multiple algorithms simultaneously, gracefully transitioning between them as new vulnerabilities are discovered. This isn’t just a technical challenge – it’s an operational one. Imagine going from managing a small garage band to conducting a full philharmonic orchestra. The complexity doesn’t increase linearly; it explodes exponentially. Each new algorithm brings its own key sizes, generation processes, security parameters, and lifecycle requirements. The conductor of this cryptographic orchestra needs perfect knowledge of every instrument and player.
The “Operational Gap” in Cryptographic Security
Having come of age in the late ’70s and ’80s, I’ve witnessed the entire evolution of security firsthand – from the early days of dial-up BBSes to today’s quantum computing era. The really wild thing is that even with all these fancy new mathematical tools, the core questions we’re asking about trust haven’t actually changed all that much. Back in 1995, when I landed my first tech job, key management meant having a physical key to the server room and maybe for the most sensitive keys a dedicated hardware device to keep them isolated. By the early 2000s, it meant managing SSL certificates for a handful of web servers – usually tracked in a spreadsheet if we were being diligent. These days, even a medium-sized company could easily have hundreds of thousands of cryptographic keys floating around across all sorts of places – desktops, on-premise service, cloud workloads, containers, those little IoT gadgets, and even some old legacy systems. The mathematical foundations have improved, but our operational practices often remain stuck in that spreadsheet era. This operational gap is where the next evolution of cryptographic risk management must focus. There are three critical capabilities that organizations need to develop before quantum threats become reality:
1. Comprehensive Cryptographic Asset Management
When a major incident hits – think Heartbleed or the discovery of a new quantum breakthrough – the first question security teams ask is: “Where are we vulnerable?” Organizations typically struggle to answer this basic question. During the Heartbleed crisis, many healthcare organizations spent weeks identifying all their vulnerable systems because they lacked a comprehensive inventory of where OpenSSL was deployed and which keys might have been exposed. What should have been a rapid response turned into an archaeological dig through their infrastructure. Modern key management must include complete visibility into:
Where’s encryption being used?
Which keys are locking down which assets?
When were those keys last given a fresh rotation?
What algorithms are they even using?
Who’s got the keys to the kingdom?
What are all the dependencies between these different crypto bits?
Without this baseline visibility, planning or actually pulling off a quantum-safe migration? Forget about it.
2. Rapid Cryptographic Incident Response
When Storm-0558 hit in 2023, the most alarming aspect wasn’t the initial compromise but the uncertainty around its scope. Which keys were affected? What systems could attackers access with those keys? How quickly could the compromised credentials be identified and rotated without breaking critical business functions? These questions highlight how cryptographic incident response differs from traditional security incidents. When a server’s compromised, you can isolate or rebuild it. When a key’s compromised, the blast radius is often unclear – the key might grant access to numerous systems, or it might be one of many keys protecting a single critical asset. Effective cryptographic incident response requires:
Being able to quickly pinpoint all the potentially affected keys when a vulnerability pops up.
Having automated systems in place to generate and deploy new keys without causing everything to fall apart.
A clear understanding of how all the crypto pieces fit together so you don’t cause a domino effect.
Pre-planned procedures for emergency key rotation that have been thoroughly tested, so you’re not scrambling when things hit the fan.
Ways to double-check that the old keys are completely gone from all systems.
Forward-thinking organizations conduct tabletop exercises for “cryptographic fire drills” – working through a key compromise and practicing how to swap them out under pressure. When real incidents occur, these prepared teams can rotate hundreds or thousands of critical keys in hours with minimal customer impact, while unprepared organizations might take weeks with multiple service outages.
3. Cryptographic Lifecycle Assurance
Perhaps the trickiest question in key management is: “How confident are we that this key has been properly protected throughout its entire lifespan?” Back in the early days of security, keys would be generated on secure, air-gapped systems, carefully transferred via physical media (think floppy disks!), and installed on production systems with really tight controls. These days, keys might be generated in various cloud environments, passed through CI/CD pipelines, backed up automatically, and accessed by dozens of microservices. Modern cryptographic lifecycle assurance needs:
Making sure keys are generated securely, with good randomness.
Storing keys safely, maybe even using special hardware security modules.
Automating key rotation so humans don’t have to remember (and potentially mess up).
Keeping a close eye on who can access keys and logging everything that happens to them.
Securely getting rid of old keys and verifying they’re really gone.
Planning and testing that you can actually switch to new crypto algorithms smoothly.
When getting ready for post-quantum migration, organizations often discover keys in use that were generated years ago under who-knows-what conditions, leading to them discovering that they need to do a complete overhaul of their key management practices.
Business Continuity in the Age of Cryptographic Change
If there’s one tough lesson I’ve learned in all my years in tech, it’s that security and keeping the business running smoothly are constantly pulling in opposite directions. This tension is especially noticeable when we’re talking about cryptographic key management. A seemingly simple crypto maintenance task can also turn into a business disaster because you have not properly tested things ahead of time, leaving you in a state where you do not understand the potential impact if these tasks if things go wrong. Post-quantum migration magnifies these risks exponentially. You’re not just updating a certificate or rotating a key – you’re potentially changing the fundamental ways systems interoperate all at once. Without serious planning, the business impacts could be… well, catastrophic. The organizations that successfully navigate this transition share several characteristics:
They treat keeping crypto operations running as a core business concern, not just a security afterthought.
They use “cryptographic parallel pathing” – basically running the old and new crypto methods side-by-side during the switch.
They put new crypto systems through really rigorous testing under realistic conditions before they go live.
They roll out crypto changes gradually, with clear ways to measure if things are going well.
They have solid backup plans in case the new crypto causes unexpected problems.
Some global payment processors have developed what some might call “cryptographic shadow deployments” – they run the new crypto alongside the old for a while, processing the same transactions both ways but only relying on the old, proven method for actual operations. This lets them gather real-world performance data and catch any issues before customers are affected.
From Janek’s Black Box to Your Security Strategy
As we’ve journeyed from that fictional universal codebreaker in Sneakers to the very real quantum computers being developed today, it strikes me how much the core ideas of security haven’t actually changed. Back in the 1970s security was mostly physical – locks, safes, and vaults. The digital revolution just moved our valuables into the realm of ones and zeros, but the basic rules are still the same: figure out what needs protecting, control who can get to it, and make sure your defenses are actually working. Post-quantum cryptography doesn’t change these fundamentals, but it does force us to apply them with a whole new level of seriousness and sophistication. The organizations that suceed in this new world will be the ones that use the quantum transition as a chance to make their cryptographic operations a key strategic function, not just something they do because they have to. The most successful will:
Get really good at seeing all their crypto stuff and how it’s being used.
Build strong incident response plans specifically for when crypto gets compromised.
Make sure they’re managing the entire lifecycle of all their keys and credentials properly.
Treat crypto changes like major business events that need careful planning.
Use automation to cut down on human errors in key management.
Build a culture where doing crypto right is something people value and get rewarded for.
The future of security is quantum-resistant organizations.
Gunter Janek’s fictional breakthrough in Sneakers wasn’t just about being a math whiz – it was driven by very human wants. Similarly, our response to quantum computing threats won’t succeed on algorithms alone; we’ve got to tackle the human and organizational sides of managing crypto risk. As someone who’s seen the whole evolution of security since the ’70s, I’m convinced that this quantum transition is our best shot at really changing how we handle cryptographic key management and the associated business risks.
By getting serious about visibility, being ready for incidents, managing lifecycles properly, and planning for business continuity, we can turn this challenge into a chance to make some much-needed improvements. The black box from Sneakers is coming – not as a device that instantly breaks all encryption, but as a new kind of computing that changes the whole game.
The organizations that come out on top won’t just have the fanciest algorithms, but the ones that have the discipline to actually use and manage those algorithms and associated keys and credentials effectively.
So, let’s use this moment to build security systems that respect both the elegant math of post-quantum cryptography and the wonderfully messy reality of human organizations.
We’ve adapted before, and we’ll adapt again – not just with better math, but with better operations, processes, and people. The future of security isn’t just quantum-resistant algorithms; it’s quantum-resistant organizations.
Offering customers deployment flexibility from managed SaaS to complex on-premise installations often feels like essential table stakes in enterprise software. Vendors list options, sales teams confirm availability, and engineering prepares for varied environments. Operationally, it seems like necessary market responsiveness. Strategically, however, this frequently masks a costly disconnect.
“The single biggest problem in communication is the illusion that it has taken place.” – George Bernard
The illusion here is that offering deployment choice equates to a sound strategy, often without a shared internal understanding of the profound operational and financial consequences across the Deployment Complexity Spectrum, visualized below:
Consider an enterprise security vendor’s platform. Their cloud-native solution delivers threat detection efficiently through centralized intelligence and real-time updates (Managed SaaS). Yet, certain market segments federal contracts, highly regulated industries (often requiring Private Cloud or On-Premise), and organizations with strict data sovereignty requirements legitimately demand deployment options further right on the spectrum. Supporting these models isn’t simply a matter of preference; it’s sometimes a necessity for market access.
However, accommodating these more complex deployment models triggers that cascade of business implications. Engineering faces the friction of packaging for disparate environments; Sales encounters drastically longer cycles navigating security and infrastructure reviews with more stakeholders; Implementation becomes bespoke and resource-intensive; Support grapples with unique, often opaque customer environments typical of Hybrid Cloud or On-Premise setups. The key isn’t avoiding these markets entirely, but rather making conscious strategic decisions about how to serve them while understanding the full business impact.
This isn’t just about technical difficulty; it’s about a fundamental business trade-off between market access and operational efficiency. Let’s examine the quantifiable impact:
The higher on-prem ARR is dwarfed by the tripled sales velocity drag, the 7.5x implementation cost, the margin collapse, and the ongoing high support burden. Even when necessary, this “complexity tax” must be accounted for. The long-term financial disparity becomes even clearer when visualized over time:
A Framework for Strategic Deployment Evaluation
To move beyond operational reactivity, vendors need a framework that explicitly evaluates the impact of supporting points along the deployment spectrum. This framework should quantify the true business impact, forcing conscious trade-offs:
Sales & Go-to-Market Impact (Weight: ~25%):
Quantify: How does this model affect sales cycle length? (On-prem often 2-3x longer). Example Key Metric: Sales Cycle Length (Days)
Identify: Does it require engaging more stakeholders (networking, security, infra, procurement), complicating the sale?
Assess: What is the cost of sales and required presales expertise vs. potential deal value? Does it accelerate or impede overall business velocity?
Implementation & Delivery Cost (Weight: ~30%):
Measure: What is the typical implementation time? (Days/weeks for SaaS vs. months/years for complex on-prem). Example Key Metric: Implementation Margin (%)
Factor In: Does it require bespoke configuration, custom infrastructure knowledge, and navigating complex customer organizational boundaries and politics?
Calculate: What is the true implementation cost and its impact on gross margin? How repeatable and predictable is delivery?
Operational Scalability & Support Burden (Weight: ~30%):
Analyze: How difficult is troubleshooting in varied, often opaque customer environments with limited vendor visibility? Can issues be easily replicated? Example Key Metric: Avg. Support Tickets per Account per Quarter
Resource: Does it require broadly skilled support staff or specialized experts per environment? How does this impact support team scalability and cost-per-customer?
Compare: Contrast the ease of automated monitoring and centralized support in SaaS vs. the manual, reactive nature of complex deployment support.
Customer Value Realization & Retention (Weight: ~15%):
Evaluate: How easily can customers access new features and improvements? Does this model enable SaaS-like continuous value delivery (think Tesla’s overnight updates) or does it rely on disruptive, infrequent upgrades? Example Key Metric: Net Revenue Retention (%) by Deployment Model
Track: How visible are product usage and value realization? Does lack of visibility (common in on-prem) hinder proactive success management and create renewal risks?
Engage: Does the model foster ongoing engagement or lead to “out of sight, out of mind,” weakening the customer relationship?
(Note: Weights are illustrative examples, meant to provoke thought on relative importance.)
This framework brings the hidden costs and strategic trade-offs into sharp focus, facilitating data-informed decisions rather than reactive accommodations.
Three Deployment Strategy Archetypes
Applying this framework often leads vendors towards one of three strategic postures:
The SaaS-First Operator: Maximizes efficiency by focusing on SaaS and standardized cloud, accepting limitations on addressable market as the key trade-off to preserve operational leverage and innovation speed.
The Full Spectrum Provider: Commits to serving all models but requires disciplined execution: distinct architectures, specialized teams, rigorous cost allocation, and pricing reflecting true complexity. High risk if not managed strategically with extreme operational discipline and cost visibility.
The Strategic Hybrid Player: Primarily cloud-focused but supports specific, well-defined Hybrid or On-Premise use cases where strategically critical (e.g., for specific regulated industries or control-plane components). Aims for a balance between market reach and operational sustainability, requiring clear architectural boundaries and disciplined focus.
Implementation: Aligning Strategy with Execution
Making the chosen strategy work requires aligning the entire organization, incorporating lessons from both successful and struggling vendors:
Recognize the fundamental differences between cloud-native (for SaaS efficiency) and traditional architectures. Align product architecture with target deployment models; avoid force-fitting. Consider distinct codebases if necessary.
Ensure pricing models accurately reflect the total cost-to-serve for each deployment option, including the higher sales, implementation, and support burden for complex models (e.g., conduct quarterly reviews of actual cost-to-serve per deployment model).
Create dedicated teams or clear processes for the unique demands of selling, implementing, and supporting complex deployments. Don’t overload SaaS-optimized teams.
Even for on-prem, develop standardized deployment models, tooling, and best practices to reduce variability.
Invest in secure monitoring/diagnostics for non-SaaS environments where feasible to improve support efficiency.
Ensure internal alignment on the strategy and its rationale. Clearly communicate capabilities, limitations, and expectations externally (e.g., ensure support SLAs clearly reflect potential differences based on deployment complexity). Avoid the “illusion” of seamless flexibility where significant trade-offs exist.
Ensure executive alignment across all functions (Product, Engineering, Sales, Support, Finance) on the chosen deployment strategy and its implications. Resource allocation must match strategic intent.
Conclusion
Choosing which deployment models to offer, and how, is a critical strategic decision, not just a technical or sales tactic. It fundamentally shapes your business’s operational efficiency, cost structure, product architecture, innovation capacity, and customer relationships. As the visualized business impact illustrates, ignoring the true costs of complexity driven by technical realities, architectural limitations, and organizational friction can cripple an otherwise successful business.
By using a multi-dimensional framework to evaluate the real impact of each deployment option and aligning the entire organization behind a conscious strategy, vendors can move beyond reactive accommodations. Success lies not in offering every possible option, but in building a sustainable, profitable, and scalable business around the deployment choices that make strategic sense. Avoid the illusion; understand and communicate the true impact.
When a product reaches the end of its lifecycle, companies typically create simple tables mapping products to migration paths, target dates, and release milestones. While operationally necessary, these tables often fail to capture the complex nature of EOL decisions. As George Bernard Shaw aptly said, “The single biggest problem in communication is the illusion that it has taken place.” These simplistic EOL tables create precisely this illusion-providing the comfort of a decision framework without addressing the strategic nuances.
Consider a neighborhood bakery that supplies all baked goods to a large grocery store chain. After a change in ownership, the new bakery manager reviews the product lineup and identifies a specialty pastry that appears to be an underperforming outlier-purchased by only a single customer. With a purely product-centric analysis, discontinuing this item seems logical.
However, this pastry happens to be a signature item for the grocery chain, which purchases substantial volumes across the bakery’s entire range. When informed about the discontinuation, the grocery store explains that their customers specifically request this specialty pastry. The bakery manager refuses to reconsider, emphasizing that the product isn’t profitable enough and the production line is needed for more popular items.
A few weeks later, the bakery learns that the grocery chain has decided to replace them entirely with a new vendor capable of meeting all their needs. The interaction was handled so poorly that the grocery store, despite being a major customer, isn’t even inclined to renegotiate-they’ve moved on completely.
This scenario vividly illustrates a common but critical strategic error: viewing products in isolation rather than considering their value in customer relationships. The quantitative analysis reveals the magnitude of this mistake:
All Other Products: $680,000 annual revenue, 22% margin
Total Account Value: $692,000 annual revenue, 21% blended margin
Risk Assessment: Discontinuing the specialty pastry put $692,000 at risk, not just $12,000
Outcome: Complete loss of the account (100% revenue impact vs. the expected 1.7% impact)
The bakery manager made several critical errors that we see repeatedly in product EOL decisions. They treated each pastry as an isolated product rather than part of a larger strategic relationship. They failed to recognize the pastry’s importance to their major client. They made decisions based purely on aggregated sales data without customer segmentation. They approached the conversation without empathy or alternatives. And they prioritized immediate resource allocation while overlooking long-term consequences.
A Framework for Better Decisions
To avoid similar mistakes, organizations need a comprehensive approach that evaluates EOL decisions across dimensions that understand the whole business, here is an example of how this might work in our bakery example:
Customer relationship impact should be the primary consideration in any EOL decision, weighing approximately 40% in the overall assessment. This includes evaluating the aggregate revenue from all products with shared customers, the customer’s classification and business importance, the probability of triggering a broader portfolio review, and what C-level relationships are tied to the product.
Product economics matter but must be viewed holistically, accounting for about 25% of the decision weight. Consider the product-specific recurring revenue and growth trajectory, any “door opener” and account protection value, ongoing engineering and operations expenses, volume and complexity of support tickets, and margin trajectory over time.
Technical considerations evaluate the maintenance burden against potential disruption, weighing approximately 20% in the decision process. Assess technical debt quantification, resources allocated across engineering and support, systems that depend on this product, estimated customer transition effort, and infrastructure and stack viability.
Market position provides critical competitive context, contributing about 15% to the decision framework. Consider the percentage of customers actively using the product, strength of the unique value proposition, fit with long-term product vision, and segment growth trajectory.
Note: These % figures are really intended as examples rather than strict guidelines.
These four dimensions provide a balanced view of a product’s strategic importance beyond immediate financial metrics. The bubble chart above illustrates their relative weighting in the decision process, emphasizing the outsized importance of customer relationships.
Three Product Archetypes and How to Handle Them
Most EOL candidates fall into one of three categories, each requiring a different approach:
Strategic anchor products have high customer relationship impact despite potentially challenging economics or technical debt. Like the bakery’s specialty pastry, they may appear unprofitable in isolation but protect significant broader revenue. Organizations should retain these products despite costs, as they protect broader customer relationships and associated revenue streams, though pricing adjustments might be considered if necessary.
Legacy systems typically have balanced profiles with high technical maintenance burden but moderate customer impact. They often represent technical debt accumulated through growth. The wise approach is to modernize rather than discontinue to maintain customer relationships, creating migration paths that preserve core functionality while reducing technical debt.
True EOL candidates have low customer attachment and minimal dependency chains. Their strategic value has diminished over time as the market has evolved. These products can be considered for end-of-life treatment with appropriate migration paths and thoughtful customer communication, ensuring smooth transitions to alternatives.
The radar chart above illustrates how these three product archetypes compare across the four dimensions. Strategic anchor products show high customer relationship impact, legacy systems typically have high technical burden but moderate customer impact, and true EOL candidates score low across most dimensions.
Implementation: Making It Work in Practice
Successful EOL decisions require collaboration across the organization through a structured process. Begin with thorough data collection across all dimensions, then integrate perspectives from Sales, Customer Success, Product, Engineering, and Support. Project different transition timelines and potential impacts. Present multidimensional analysis to secure leadership alignment. Develop thoughtful communication that acknowledges the full context.
As the bakery example illustrates, EOL decisions are fundamentally about managing complex trade-offs. The framework shifts the conversation from “Should we discontinue this product?” to “What is the strategic value of this product to our customers and business?”
By moving beyond simplistic spreadsheet analysis to a multidimensional approach, organizations can make EOL decisions that enhance rather than damage customer relationships, technical architecture, and market position.
Remember Shaw’s warning about the illusion of communication. Your EOL tables may give the appearance of strategic planning, but without considering all dimensions, they’re merely operational checklists that risk overlooking critical strategic value. The true measure of EOL success isn’t operational execution but customer retention and long-term business impact.
We cannot do everything; the French have a saying, “To choose something is to renounce something.” This also holds true for Product Managers. How we choose is important, especially in a startup where resources are finite.
The larger the organization, or the more political it is, having a framework that we use for decision-making helps us both increase the chances of good decisions and defend the uncomfortable decisions that must be made.
The highest priority of a product manager is to be a good custodian of the engineering resources. This means we must ensure they have the information they need to make the right engineering investments; otherwise, we are wasting the most valuable asset in the organization.
The next highest priority is to ensure that the sales and support team has what they need to keep the funnel full. This might include marketing materials, product roadmaps, one-on-one customer engagements, or a myriad of other inputs to the sales process that enable the field to support teams to jump-start the revenue engine.
With that said, if all we do is focus on those two things, we fail. Product management is about solving a specific business problem in an elegant and timely manner. This requires research, customer interviews, designs, and roadmapping. Once we unblock engineering, sales, and support, we must shift our priority to optimizing the conversion funnel.
We need to prioritize optimizing how each stage of the sales funnel works while ensuring the existing sales, support, and engineering processes function as needed.
The path to success involves balancing immediate needs with long-term strategic goals and continually refining the process to ensure that the product not only addresses current market needs but is also positioned for future growth and success. This also requires us to continually assess, as independently as we can, how the organization is doing on these metrics so we can make sure how we prioritize evolves with the ever-changing needs of the organization.
As the product manager, you are in many respects the general manager for the business. If you get too focused on a task mindset, simply put, you will miss the forest through the trees, which for a small company can be the difference between death and success.
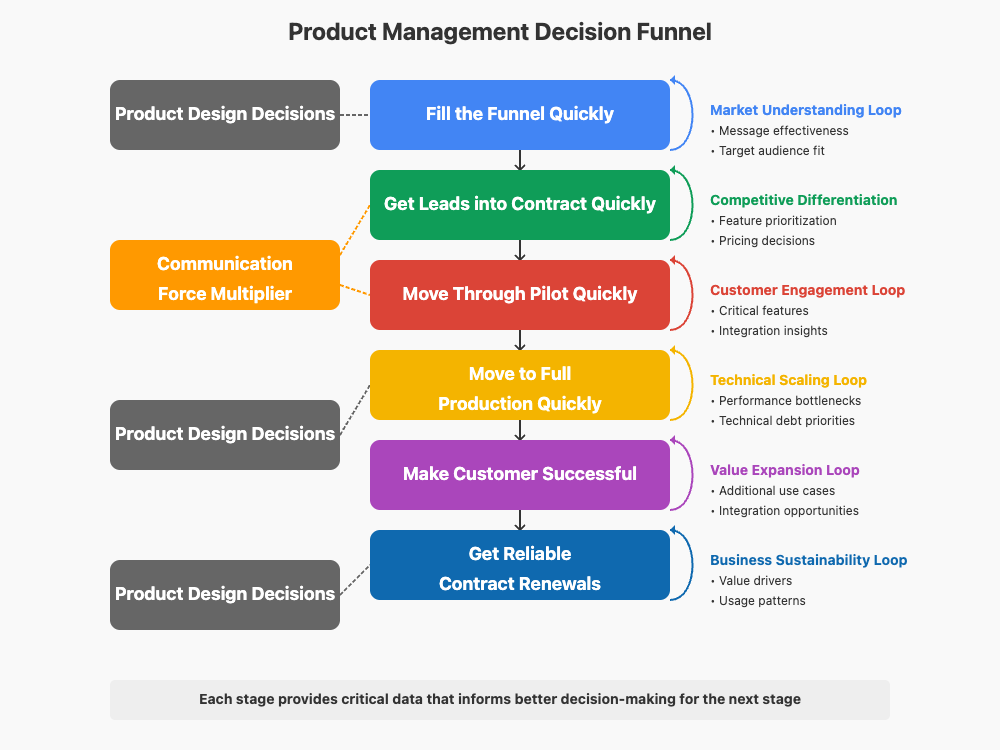
The Decision Engine
What makes this funnel particularly powerful is that each stage generates critical information that fuels better decision-making. As a product manager, you’re not just moving customers through stages—you’re creating a decision engine that systematically improves how you allocate resources and prioritize efforts.
When focusing on filling the funnel, every piece of messaging that resonates or falls flat gives you data that refines your market understanding. The leads that convert tell you which pain points matter most; those that don’t reveal gaps in your value proposition. This creates a natural feedback loop where better market understanding leads to more effective messaging, which generates higher-quality leads, further enhancing your understanding.
This pattern continues as prospects move toward contracts. Here, you learn precisely where your offering stands relative to alternatives. Which features accelerate decisions in your favor? What competitive gaps slow down contract signing? These insights should directly influence your product prioritization decisions, creating a virtuous cycle where enhanced differentiation speeds contract closure.
Product Design: The True Driver of Sales Velocity
Looking at our funnel, it’s tempting to see words like “quickly,” “successful,” and “renewals” as purely sales-driven metrics. In reality, these outcomes are fundamentally shaped by product decisions. Each “quickly” in our funnel represents not just a sales process optimization but a product design imperative.
Consider the pilot stage. Moving through pilot “quickly” isn’t just about sales execution—it’s about how you’ve designed the product to be deployed, configured, and integrated. A product that requires weeks of professional services to set up creates an inherent velocity constraint that no sales process can overcome. Your architectural decisions directly determine how rapidly customers can reach value.
Similarly, moving to full production quickly depends on how you’ve designed for scalability from the beginning. Does your product require painful reconfiguration when moving from pilot to production? Have you anticipated enterprise requirements for security, compliance, and integration? The deployment friction your customers experience is built into your product decisions long before the sales team encounters it.
Making customers “successful” and securing renewals are likewise outcomes of product strategy more than sales tactics. A product designed with deep customer empathy, clear use cases, and thoughtful success metrics creates its own momentum toward renewal. Conversely, even the most skilled customer success team can’t compensate for a product that doesn’t deliver measurable value aligned with the customer’s definition of success.
As a product manager, recognize that you’re designing not just features but the velocity of your entire business. Every decision that reduces friction in deployment, integration, scalability, and value realization accelerates your funnel more effectively than any sales process optimization could.
Communication: The Force Multiplier of Decision-Making
The greatest decision framework in the world fails if it remains inside your head. The biggest problem with communication is the illusion that it has occurred. As a product manager, you can never communicate too much about decisions and their rationale.
Clear communication turns good decisions into organizational alignment. When engineers understand not just what to build but why it matters to customers and the business, they make better micro-decisions during implementation. When sales understands the strategic reasoning behind a feature prioritization, they can communicate this context to customers, turning potential disappointment into a deeper relationship.
Insufficient communication of decisions and rationale inevitably leads to loss of focus and momentum. Teams begin to drift in different directions, making assumptions about priorities that may conflict with your actual intentions. You’ll find yourself having the same conversations repeatedly, wondering why people “just don’t get it.” The answer is usually that you haven’t communicated nearly as effectively as you thought.
This communication challenge often necessitates difficult conversations and realignment throughout the process. Team members may have become invested in directions that no longer align with your decisions. Having to reset expectations is uncomfortable but essential. These conversations become significantly easier when you’ve consistently communicated the decision framework and the data informing it.
Effective communication of decisions requires multiple formats and repetition. The same message needs reinforcement through documentation, presentations, one-on-ones, and team discussions. Remember that people need to hear information multiple times, in multiple contexts, before it truly sinks in. What feels like redundant overcommunication to you is often just barely sufficient for your stakeholders.
Most importantly, communicate not just the what but the why. Decisions without context are merely directives; decisions with context create learning opportunities that help your team make better autonomous choices aligned with your strategy.
Embracing Constraints
It’s worth acknowledging a fundamental truth of product management: resource constraints are inevitable regardless of your organization’s size. Even companies with seemingly infinite resources must choose where to allocate them. Google, Amazon, and Apple all discontinue products and say “no” to opportunities—size doesn’t eliminate the need for prioritization, it just changes the scale of what’s possible.
Priority conflicts and organizational challenges will always be part of the landscape you navigate. You’ll encounter competing stakeholder needs, passionate advocates for conflicting approaches, and the politics that come with any human enterprise. This isn’t a sign that something is wrong—it’s the natural state of building products in complex environments.
The key difference between effective and ineffective product managers isn’t whether they face these challenges, but how they approach them. By being transparent about the first and second-order effects of your decisions, you create trust even when stakeholders disagree with your choices. When engineering knows why you’ve prioritized feature A over feature B, they may still be disappointed but can align with the reasoning.
Perhaps most importantly, remember that few decisions are truly permanent. The best product managers maintain the humility to monitor outcomes and change course when the data suggests they should. Your decision framework should include not just how to decide, but how to recognize when a decision needs revisiting. This adaptability, coupled with transparency about your reasoning, creates the resilience necessary to navigate the inevitable twists in your product journey.
Building Decision Frameworks That Scale
As product managers, we should strive to make our analysis and decision processes repeatable and measurable. Using consistent rubrics helps ensure that the insights generated at each funnel stage don’t remain isolated events but become part of an institutional learning process.
These rubrics need not be complex—simple scoring systems for evaluating feature requests against strategic goals, or frameworks for assessing customer feedback patterns—but they should be consistent. By standardizing how we evaluate options, we create the ability to look back quarterly and yearly to assess the quality of our decision-making.
Did we ask ourselves the right questions? Did we weigh factors appropriately? Which decision frameworks yielded the best outcomes? This retrospective analysis allows us to internalize lessons and deploy improved decision processes more consistently across the organization. Over time, these rubrics become the scaffolding that supports better and faster decisions as the company grows.
Feeding the Company’s Soul
As a product manager, you are the custodian of more than just resources—you are feeding the very soul of the company. Product is where vision meets reality, where strategy becomes tangible, and where customer needs translate into business value. Each decision you make, each iteration loop you create, fuels the journey toward the company’s next milestone.
These seemingly small decisions—which feature to prioritize, which customer segment to focus on, which technical debt to address—collectively determine the trajectory of the entire organization. The funnel isn’t just a conversion mechanism; it’s the heartbeat of your business, pumping valuable insights that nourish every subsequent decision.
Your most valuable contribution isn’t the individual decisions you make, but how you architect the feedback loops that transform customer interactions into organizational learning. By systematically capturing and applying these insights, you create not just a product but an ever-evolving organism that adapts and thrives in changing conditions.
Remember that in a startup, the line between success and failure is often razor-thin. Your ability to make good decisions, informed by these iteration loops, may be the difference between reaching that next funding milestone or running out of runway. You’re not just building a product—you’re charting the course that determines whether your company reaches its destination or disappears beneath the waves.
What took the telecommunications industry a century to experience—the full evolution from groundbreaking innovation to commoditized utility status—cloud computing is witnessing in just 15 years. This unprecedented compression isn’t merely faster; it represents a significant strategic challenge to cloud providers who believe their operational expertise remains a durable competitive advantage.
The historical parallel is instructive, yet nuanced. While telecom’s path offers warnings, cloud providers still maintain substantial advantages through their physical infrastructure investments and service ecosystems.
Telecom’s Transformation: Lessons for Cloud Providers
In 1984, AT&T was the undisputed titan of American business—a monopolistic giant controlling communication infrastructure so vital that it was deemed too essential to fail. Its operational expertise in managing the world’s most complex network was unmatched, its infrastructure an impenetrable competitive moat, and its market position seemingly unassailable.
Four decades later, telecom companies have been substantially transformed. Their networks, while still valuable assets, no longer command the premium they once did. The 2024 Salt Typhoon cyberattacks revealed vulnerabilities in these once-impregnable systems—targeting nine major US telecom providers and compromising systems so thoroughly that the FBI directed citizens toward encrypted messaging platforms instead of traditional communication channels.
This transformation contains critical lessons for today’s cloud providers.
Telecom’s journey followed a predictable path:
Innovation to Infrastructure: Pioneering breakthroughs like the telephone transformed into sprawling physical networks that became impossible for competitors to replicate.
Operational Excellence as Moat: By mid-century, telecom giants weren’t just valued for their copper wire—their ability to operate complex networks at scale became their true competitive advantage.
Standardization and Erosion: Over decades, standardization (TCP/IP protocols) and regulatory action (AT&T’s breakup) gradually eroded these advantages, turning proprietary knowledge into common practice.
Value Migration: As physical networks became standardized, value shifted to software and services running atop them. Companies like Skype and WhatsApp captured value without owning a single mile of cable.
Security Crisis: Commoditization led to chronic underinvestment, culminating in the catastrophic Salt Typhoon vulnerabilities that finally shattered the public’s trust in legacy providers.
Cloud providers are accelerating through similar phases, though with important distinctions that may alter their trajectory.
Cloud’s Compressed Evolution: 7x Faster Than Telecom
The cloud industry is experiencing its innovation-to-commoditization cycle at hyperspeed. What took telecom a century is unfolding for cloud in approximately 15 years—a roughly 7-fold acceleration—though the endgame may differ significantly.
Consider the timeline compression:
What took long-distance calling nearly 50 years to transform from premium service to essentially free, cloud storage accomplished in less than a decade—with prices dropping over 90%.
Features that once justified premium pricing (load balancing, auto-scaling, managed databases) rapidly became table stakes across all providers.
APIs and interfaces that were once proprietary differentiators are now essentially standardized, with customers demanding cross-cloud compatibility.
This accelerated commoditization has forced cloud providers to rely heavily on their two enduring advantages:
Massive Infrastructure Scale: The capital-intensive nature of global data center networks
Operational Excellence: The specialized expertise required to run complex, global systems reliably
The first advantage remains formidable—the sheer scale of hyperscalers’ infrastructure represents a massive barrier to entry that will endure. The second, however, faces new challenges.
The Evolving Moat: How AI is Transforming Operational Expertise
Cloud providers’ most valuable operational asset has been the expertise required to run complex, distributed systems at scale. This knowledge has been nearly impossible to replicate, requiring years of specialized experience managing intricate environments.
AI is now systematically transforming this landscape:
AI-Powered Operations Platforms: New tools are encapsulating advanced operational knowledge, enabling teams to implement practices once reserved for elite cloud operations groups.
Cross-Cloud Management Systems: Standardized tools and AI assistance are making it possible for organizations to achieve operational excellence across multiple cloud providers simultaneously—an important shift in vendor dynamics.
Democratized Security Controls: Advanced security practices once requiring specialized knowledge are now embedded in automated tools, making sophisticated protection more widely accessible.
AI is transforming operational expertise in cloud computing. It isn’t eliminating the value of human expertise but rather changing who can possess it and how it’s applied. Tasks that once took years for human operators to master can now be implemented more consistently by AI systems. However, these systems have important limitations that still require human experts to address. While AI reduces the need for certain routine skills, it amplifies the importance of human experts in strategic oversight, ensuring that AI is used effectively and ethically.
The New Infrastructure Reality: Beyond Provider Lock-In
The fundamental value of cloud infrastructure isn’t diminishing—in fact, with AI workloads demanding unprecedented compute resources, the physical footprint of major providers becomes even more valuable. What’s changing is the level of provider-specific expertise required to leverage that infrastructure effectively.
The Multi-Cloud Opportunity
AI-powered operations are making multi-cloud strategies increasingly practical:
Workload Portability: Organizations can move applications between clouds with reduced friction
Best-of-Breed Selection: Companies can choose optimal providers for specific workloads
Cost Optimization: Customers can leverage price competition between providers more effectively
Risk Mitigation: Businesses can reduce dependency on any single provider
This doesn’t mean companies will abandon major cloud providers. Rather, they’ll be more selective about where different workloads run and more willing to distribute them across providers when advantageous. The infrastructure remains essential—what changes is the degree of lock-in.
The New Challenges: Emerging Demands on Cloud Operations
As operational advantages evolve, cloud providers face several converging forces that will fundamentally reshape traditional models. These emerging challenges extend beyond conventional scaling issues, creating qualitative shifts in how cloud infrastructure must be designed, managed, and secured.
The Vibe Coding Revolution
“Vibe coding” transforms development by enabling developers to describe problems in natural language and have AI generate the underlying code. This democratizes software creation while introducing different infrastructure demands:
Applications become more dynamic and experimental, requiring more flexible resources
Development velocity accelerates dramatically, challenging traditional operational models
Debugging shifts from code-focused to prompt-focused paradigms
As newer generations of developers increasingly rely on LLMs, critical security challenges emerge around software integrity and trust. The abstraction between developer intent and implementation creates potential blind spots, requiring governance models that balance accessibility with security.
Meanwhile, agentic AI reshapes application deployment through autonomous task orchestration. These agents integrate disparate services and challenge traditional SaaS models as business logic migrates into AI. Together, these trends accelerate cloud adoption while creating challenges for conventional operational practices.
The IoT and Robotics Acceleration
The Internet of Things is creating unprecedented complexity with over 30 billion connected devices projected by 2026. This expansion fragments the operational model, requiring seamless management across central cloud and thousands of edge locations. The boundary between edge and cloud creates new security challenges that benefit from AI-assisted operations.
Robotics extends this complexity further as systems with physical agency:
Exhibit emergent behaviors that weren’t explicitly programmed
Create operational challenges where physical and digital domains converge
Introduce security implications that extend beyond data protection to physical safety
Require real-time processing with strict latency guarantees that traditional cloud models struggle to address
The fleet management of thousands of semi-autonomous systems requires entirely new operational paradigms that bridge physical and digital domains.
The AI Compute Demand
AI training and inference are reshaping infrastructure requirements in ways that differ fundamentally from traditional workloads. Large language model training requires unprecedented compute capacity, while inference workloads demand high availability with specific performance characteristics. The specialized hardware requirements create new operational complexities as organizations balance:
Resource allocation between training and inference
Specialized accelerators with different performance characteristics
Cost optimization as AI budgets expand across organizations
Dynamic scaling to accommodate unpredictable workload patterns
These represent fundamentally different resource consumption patterns that cloud architectures must adapt to support—not simply larger versions of existing workloads.
The Security Imperative
As systems grow more complex, security approaches must evolve beyond traditional models. The attack surface has expanded beyond what manual security operations can effectively defend, while AI-powered attacks require equally sophisticated defensive capabilities. New security challenges include:
Vibe-coded applications where developers may not fully understand the generated code’s security implications
Robotics systems with physical agency creating safety concerns beyond data protection
Emergent behaviors in AI-powered systems requiring dynamic security approaches
Compliance requirements across jurisdictions demanding consistent enforcement at scale
Current cloud operations—even with elite human teams—cannot scale to these demands. The gap between operational requirements and human capabilities points toward AI-augmented security as the only viable path forward.
The Changing Competitive Landscape: A 5-10 Year Horizon
Over the next 5-10 years, these technological shifts will create significant changes in the cloud marketplace. While the timing and magnitude of these changes may vary, clear patterns are emerging that will reshape competitive dynamics, pricing models, and value creation across the industry.
Value Migration to Orchestration and Agentic Layers
Just as telecom saw value shift from physical networks to OTT services, cloud is experiencing value migration toward higher layers of abstraction. Value is increasingly found in:
Multi-cloud management platforms that abstract away provider differences
AI-powered operations tools that reduce the expertise barrier
Specialized services optimized for specific workloads or regulatory regimes
AI development platforms that facilitate vibe coding approaches
Agentic AI systems that can autonomously orchestrate tasks across multiple services
Hybrid SaaS/AI solutions that combine traditional business logic with intelligent automation
This doesn’t eliminate infrastructure’s value but alters competitive dynamics and potentially compresses margins for undifferentiated services. As Chuck Whitten noted regarding agentic AI’s impact on SaaS: “Transitions lead not to extinction but to transformation, adaptation, and coexistence.”
Increased Price Sensitivity for Commodity Services
As switching costs decrease through standardization and AI-powered operations, market dynamics shift significantly. We’re seeing:
Basic compute, storage, and networking becoming more price-sensitive
Value-added services facing more direct competition across providers
Specialized capabilities maintaining premium pricing while commoditized services face margin pressure
This creates a strategic landscape where providers must carefully balance commoditized offerings with differentiated services that address specific performance, security, or compliance requirements.
The Rise of Specialized Clouds
The market is evolving toward specialization rather than one-size-fits-all solutions. Three key categories are emerging:
Industry-specific clouds optimized for particular regulatory requirements in healthcare, finance, and government
Performance-optimized environments for specific workload types like AI, HPC, and real-time analytics
Sovereignty-focused offerings addressing geopolitical concerns around data governance and control
These specialized environments maintain premium pricing even as general-purpose computing becomes commoditized, creating opportunities for focused strategies that align with specific customer needs.
Salt Typhoon as a Cautionary Tale
The telecom industry’s commoditization journey reached a critical inflection point with the 2024-2025 Salt Typhoon cyberattacks. These sophisticated breaches targeted nine major US telecommunications companies, including giants like Verizon, AT&T, and T-Mobile, compromising sensitive systems and exposing metadata for over a million users. This crisis revealed how commoditization had led to chronic underinvestment in security innovation and resilience.
The aftermath was unprecedented: the FBI directed citizens toward encrypted messaging platforms as alternatives to traditional telecommunication—effectively steering users away from legacy infrastructure toward newer, more secure platforms. This government-endorsed abandonment of core telecom services represented the ultimate consequence of commoditization. Just as commoditization eroded telecom’s security resilience, cloud providers risk a similar fate if they grow complacent in an increasingly standardized market.
While cloud providers currently prioritize security more than telecom historically did, the Salt Typhoon incident illustrates the dangers of underinvestment in a commoditizing field. With innovation cycles compressed roughly 7-fold compared to telecom—meaning cloud technologies evolve at a pace telecom took decades to achieve—they have even less time to adapt before facing similar existential challenges. As AI agents and orchestration platforms abstract cloud-specific expertise—much like telecom’s reliance on standardized systems—security vulnerabilities could emerge, mirroring the weaknesses Salt Typhoon exploited.
Stakeholder Implications
The accelerating commoditization of cloud services transforms the roles and relationships of all stakeholders in the ecosystem. Understanding these implications is essential for strategic planning.
For Operations Teams
The shift from hands-on execution to strategic oversight represents a fundamental change in skill requirements. Engineers who once manually configured infrastructure will increasingly direct AI systems that handle implementation details. This evolution mirrors how telecom network engineers transitioned from hardware specialists to network architects as physical infrastructure became abstracted.
Success in this new paradigm requires developing expertise in:
AI oversight and governance
Cross-cloud policy management
Strategic technology planning
Risk assessment and mitigation
Rather than platform-specific implementation knowledge, the premium skills become those focused on business outcomes, security posture, and strategic optimization.
For Customers & End Users
The democratization of operational expertise through AI fundamentally transforms the customer’s role in the cloud ecosystem. Just as telecom users evolved from passive consumers of fixed telephone lines to active managers of their communication tools, cloud customers are transitioning from consumers of provider expertise to directors of AI-powered operations.
Enterprise teams no longer need specialized knowledge for each platform, as AI agents abstract away complexity. Decision-making shifts from “which cloud provider has the best expertise?” to “which orchestration layer best manages our multi-cloud AI operations?” This democratization dramatically reduces technical barriers to cloud migration and multi-cloud strategies, accelerating adoption while increasing provider switching frequency.
For Security Posture
The Salt Typhoon breach offers a sobering lesson about prioritizing efficiency over security innovation. The democratization of operational expertise through AI creates a paradox: security becomes both more challenging to maintain and more essential as a differentiator.
Organizations that can augment AI-driven security with human expertise in threat hunting and response will maintain an edge in an increasingly commoditized landscape. Without this focus, cloud providers risk becoming the next victims of a Salt Typhoon-scale breach that could potentially result in similar government recommendations to abandon their services for more secure alternatives.
For the Industry as a Whole
The drastic compression of innovation cycles means even foundational assets—massive infrastructure and deep operational expertise—face unprecedented pressure. Cloud providers must simultaneously integrate new AI capabilities while preserving their core strengths.
The rapid emergence of third-party orchestration layers is creating a new competitive battleground above individual clouds. This mirrors how over-the-top services disrupted telecom’s business model. Cloud providers that fail to adapt to this new reality risk following the path of telecom giants that were reduced to “dumb pipes” as value moved up the stack.
The Strategic Imperative: Evolution, Not Extinction
Cloud providers face a significant strategic challenge, but not extinction. The way forward requires evolution rather than entrenchment, with four key imperatives that can guide successful adaptation to this changing landscape. These strategies recognize that cloud’s value proposition is evolving rather than disappearing.
Embrace AI-Enhanced Operations
Providers that proactively integrate AI into their operational models gain significant advantages by:
Delivering higher reliability and security at scale
Reducing customer operational friction through intelligent automation
Focusing human expertise on high-value problems rather than routine tasks
Creating self-service experiences that democratize capabilities while maintaining differentiation
The competitive advantage comes not from simply adopting AI tools, but from reimagining operations with intelligence embedded throughout the stack—transforming how services are delivered, monitored, and optimized.
Lead the Multi-Cloud Transition
Rather than resisting multi-cloud adoption, forward-thinking providers are positioning themselves to lead this transition by:
Creating their own cross-cloud management capabilities
Optimizing for specific workloads where they excel
Developing migration paths that make them the preferred destination for critical workloads
Building partnership ecosystems that enhance their position in multi-cloud environments
The goal is becoming the strategic foundation within a multi-cloud strategy, rather than fighting against the inevitable trend toward workload distribution and portability.
Invest in Infrastructure Differentiation
Physical infrastructure remains a durable advantage when strategically positioned. Differentiation opportunities include:
Specialization for emerging workloads like AI
Optimization for performance characteristics that matter to key customer segments
Strategic positioning to address sovereignty and compliance requirements
Energy efficiency design in an increasingly carbon-conscious market
Architecture to support real-time processing demands of robotics and autonomous systems
Ultra-low latency capabilities for mission-critical applications
Infrastructure isn’t becoming irrelevant—it’s becoming more specialized, with different characteristics valued by different customer segments.
Develop Ecosystem Stickiness
Beyond technical lock-in, providers can build lasting relationships through ecosystem investments:
Developer communities that foster innovation and knowledge sharing
Education and certification programs that develop expertise
Partner networks that create business value beyond technical capabilities
Industry-specific solutions that address complete business problems
This ecosystem approach recognizes that relationships and knowledge investments often create stronger bonds than technical dependencies alone, leading to more sustainable competitive advantages over time.
The Path Forward: Three Strategic Options
Cloud providers have three strategic options to avoid the telecom commoditization trap as I see it right now:
Vertical integration into industry-specific solutions that combine infrastructure, expertise, and deep industry knowledge in ways difficult to commoditize. This approach focuses on value creation through specialized understanding of regulated industries like healthcare, finance, and government.
Specialization in emerging complexity areas where operational challenges remain high and AI assistance is still developing. These include domains like quantum computing, advanced AI training infrastructure, and specialized hardware acceleration that resist commoditization through continuous innovation.
Embracing the orchestration layer by shifting focus from infrastructure to becoming the universal fabric that connects and secures all computing environments. Rather than fighting the abstraction trend, this strategy positions providers at the center of the multi-cloud ecosystem.
Conclusion
Cloud providers face a clear choice, continue investing solely in operational excellence that is gradually being democratized by AI, or evolve their value proposition to emphasize their enduring advantages while embracing the changing operational landscape.
For cloud customers, the message is equally clear: while infrastructure remains critical, the flexibility to leverage multiple providers through AI-powered operations creates new strategic options. Organizations that build intelligence-enhanced operational capabilities now will gain unprecedented flexibility while potentially reducing costs and improving reliability.
The pattern differs meaningfully from telecom. While telecommunications became true commodities with minimal differentiation, cloud infrastructure maintains significant differentiation potential through performance characteristics, geographic distribution, specialized capabilities, and ecosystem value. The challenge for providers is to emphasize these differences while adapting to a world where operational expertise becomes more widely distributed through AI.
The time to embrace this transition isn’t in some distant future—it’s now. Over the next 5-10 years, the providers who recognize these shifts early and adapt their strategies accordingly will maintain leadership positions, while those who resist may find their advantages gradually eroding as customers gain more options through AI-enhanced operations.
The evolution toward AI-enhanced operations isn’t just another technology trend—it’s a significant shift in how cloud value is created and captured. The providers who understand this transformation will be best positioned to thrive in the next phase of cloud’s rapid evolution.
When selling security solutions to enterprises, understanding who makes purchasing decisions is critical to success. Too often, security vendors aim their messaging at the wrong audience or fail to recognize how budget authority flows in organizations. This post tries to break down the essential framework for understanding enterprise security buyer dynamics.
While this framework provides a general structure for enterprise security sales, industry-specific considerations require adaptation. Regulated industries like healthcare, finance, and government have unique compliance requirements, longer approval cycles, and additional stakeholders (e.g., legal, risk committees).
The Buyer Hierarchy
The first key concept to understand is the buyer hierarchy in enterprise security.
Figure 1: The Buyer Hierarchy
This pyramid structure represents who typically makes purchasing decisions at different price points:
At the base of the pyramid are Security and IT Managers. These individuals make most purchase decisions, particularly for:
Standard solutions with established budget lines
Renewals of existing products
Smaller ticket items
Solutions addressing immediate operational needs
Moving up the pyramid, we find Security and IT Directors who typically approve:
Larger deals requiring more significant investment
In security sales, it’s crucial to distinguish between two key players:
The Champion: This person is chartered to solve the problem. They’re typically your main point of contact and technical evaluator – often a security engineer, DevOps lead, or IT admin. They’ll advocate for your solution but rarely control the budget.
The Buyer: This is the person who owns the budget. Depending on the size of the deal, this could be a manager, director, or in some cases, the CISO. They make the final purchasing decision.
Understanding this dynamic is critical. Too many sales efforts fail because they convinced the champion but never engaged the actual buyer.
The Budget Factor
Another critical dimension is whether your solution is:
Pre-budgeted: Already planned and allocated in the current fiscal year
Unbudgeted: Requires new budget allocation or reallocation from other initiatives
Figure 2: Budgetary Timing Diagram
This distinction dramatically impacts who needs to approve the purchase. Unbudgeted items almost always require higher-level approval – typically at the CISO level for any significant expenditure, as they have the authority to reallocate funds or tap into contingency budgets.
The Cross-Organizational Challenge
A critical dimension often overlooked in enterprise security sales is cross-organizational dynamics.
When security purchases span multiple departments (e.g., budget from Compliance, implementation by Engineering), the buyer hierarchy becomes more complex. Moving funds between departmental budgets often requires executive approval above the standard buyer level.
Different departments operate with separate success metrics, priorities, and approval chains. What solves one team’s problems may create work for another with no benefit to their goals. These cross-organizational deals typically extend sales cycles by 30-50%.
For vendors navigating these scenarios, success depends on mapping all stakeholders across departments, creating targeted value propositions for each group, and sometimes elevating deals to executives who can resolve cross-departmental conflicts.
The Cost of Sale Framework
As solutions become more enterprise-focused, the cost of sale increases dramatically.
Figure 3: Cost of Sale Diagram
This framework illustrates a critical principle: The cost of sale must be aligned with the buyer level.
For solutions with a higher cost of sale (requiring more sales personnel time, longer sales cycles, more supporting resources), vendors must sell higher in the organization to ensure deal sizes justify these costs.
Key components affecting cost of sale include:
Sales personnel salary
Number of accounts per sales rep
Sales cycle length
Supporting resources required
This explains why enterprise security vendors selling complex solutions must target the CISO budget – it’s the only way to recoup their significant cost of sale.
Relationship Dynamics and Timing Considerations
While understanding the buyer hierarchy is essential, most successful enterprise security deals don’t happen solely through identifying the right level in an organization.
Figure 4: Cost of Sale Diagram
Two critical factors often determine success:
Relationship Development: Successful sales rarely happen in a transactional manner. They require:
Building trust through consistent value delivery before the sale
Understanding the internal politics and relationships between champions and buyers
Developing multiple organizational touchpoints beyond just the champion
Recognizing the personal career motivations of both champions and buyers
Timing Alignment: Even perfect solutions fail when timing is wrong:
Budget cycle alignment is critical – engage 3-6 months before annual planning
Crisis or incident response periods can accelerate purchases or freeze them
Organizational changes (new leadership, restructuring) create both opportunities and risks
Regulatory deadlines often drive urgent security investments
The most effective security vendors don’t just target the right level in the hierarchy – they strategically time their engagements and invest in relationship development that transcends organizational charts.
Practical Application
For security vendors, this framework provides practical guidance:
Know your buyer level: Based on your solution’s price point and complexity, identify your primary buyer persona (Manager, Director, or CISO)
Target champions appropriately: Ensure your technical messaging resonates with the people who will evaluate and champion your solution
Align marketing to both: Create distinct messaging for champions (technical value) and buyers (business value)
Understand the budget cycle: Time your sales efforts to align with budget planning for better success with larger deals
Match sales approach to cost structure: Ensure your go-to-market approach and resources match your cost of sale
By aligning your sales and marketing efforts with these buyer dynamics, you’ll significantly improve your efficiency and close rates in the enterprise security market.