Phishing attacks often begin with a seemingly simple email. These emails appear to be from trusted sources and include links to fake websites or messages that create a false sense of urgency, prompting users to act without considering the consequences. Once on the phishing site, everything looks familiar. Attackers meticulously copy the layout, design, and even the content from real websites. The only noticeable difference in a well-executed phishing site is where the data is submitted.
Although studies show that users typically do not scrutinize the address bar or understand URLs, some more technical users may check the domain name hosting the content as a last resort to verify its legitimacy. This approach, however, is problematic for several reasons:
- Domain Confusion: Not everyone knows which domain is appropriate for which content. For example, TD Bank, N.A. issues co-branded credit cards for various companies. When paying your credit card bill online, you might see a domain name owned by TD Bank rather than the brand on your credit card.
- Brand Ambiguity: The global uniqueness of business names or brands is not something you can rely on. For instance, when I hear “Stripe,” I think of the San Francisco-based payments company, but there could be other companies with the same name, such as one in the pavement striping industry. To put that into context it costs about $100 and 24 hours of somebody else’s money to register a company with virtually whatever name you want.
- Unrelated Legal and Domain Names: Company brands and their legal names often differ, as do their domain names. This discrepancy makes domain names more useful to attackers than to users for detection.
Furthermore, compromised websites from small businesses, churches, and other less technical organizations are frequently used to host phishing content. The key takeaway here is that content, not the domain name, is what makes a phishing campaign successful. The familiar look and feel of the content on phishing sites play a crucial role in deceiving users, making them less likely to question the site’s authenticity.
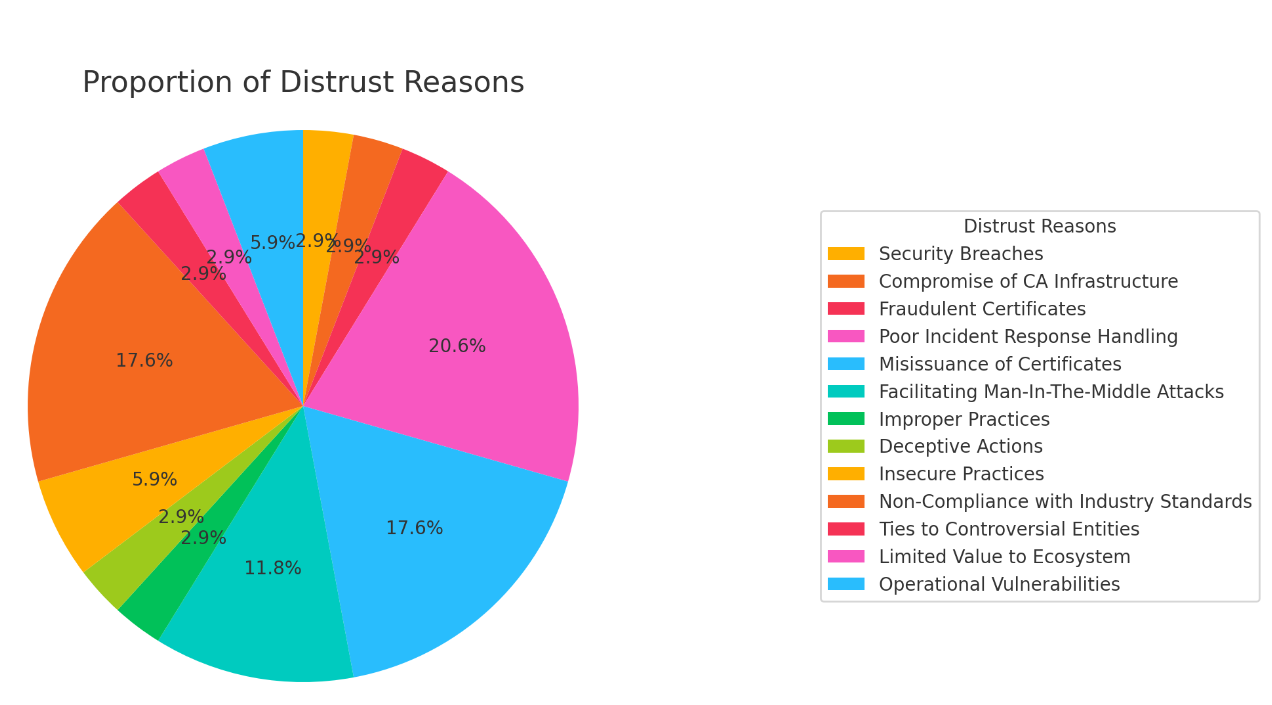
The Role of Certificate Authorities
Certificate authorities (CAs) in the web ecosystem exist to solve the trust-on-first-use problem introduced by our desire to protect the content we submit over the web from prying eyes (for more information, see TOFU and the Web). At its core, this problem arises because if you perform an anonymous key exchange or simply download the public key of a website from an unauthenticated source like DNS (while DNSSEC does technically exist, it is poorly adopted outside of TLDs), an attacker could replace the published key with one they control. This allows them to perform a man-in-the-middle (MITM) attack.
Certificate authorities are the answer to this problem. Browsers maintain a set of requirements that CAs must meet if they are to be distributed as “trusted” within their browsers (for more information, see Why We Trust WebPKI Root Certificate Authorities). In this ecosystem, browsers delegate solving the trust-on-first-use problem to the CAs. Essentially, they require CAs to prove that the requester of a certificate has administrative control over the domain and issue a certificate that attests to this. This enables browsers, as agents of the user, to assure the user that no one else should be able to intercept the information sent to the website (for some value of “website” — the modern website is made up of many third-party components that can potentially see your content also, but that’s a topic for another post).
Where things start to get tricky is how standards are defined. Anyone who works in a standards body knows that getting to a consensus is hard and often leads to less-than-ideal explanations of things. This is made worse by not everyone who participates understands the whole problem domain. Unfortunately, this is as true in the CA/Browser Forum as it is in other standards bodies. In the context of phishing, this comes into play in the “Baseline Requirements for the Issuance and Management of Publicly-Trusted TLS Server Certificates”, which has the concept of a “High-Risk Certificate Request” that states:
High-Risk Certificate Request: A Request that the CA flags for additional scrutiny by reference to internal criteria and databases maintained by the CA, which may include names at higher risk for phishing or other fraudulent usage, names contained in previously rejected certificate requests or revoked Certificates, names listed on the Miller Smiles phishing list or the Google Safe Browsing list, or names that the CA identifies using its own risk-mitigation criteria.
(It is worth noting Google Safe Browsing isn’t a list it is a web service…. sigh….)
And
The CA SHALL provide all personnel performing information verification duties with skills-training that covers basic Public Key Infrastructure knowledge, authentication and vetting policies and procedures (including the CA’s Certificate Policy and/or Certification Practice Statement), common threats to the information verification process (including phishing and other social engineering tactics), and these Requirements.
On its surface, this seems harmless enough. It doesn’t mandate that the CA do anything for phishing beyond training its validation staff about the contents but does allow them to do something about it if they can. After all, maybe they see phishing content and can stop the issuance altogether before a certificate is issued, preventing the use of SSL on the phishing site altogether. The problem is this all does more harm than good.
Why CAs Don’t Make Good Content Police
Determining whether content is phishing or legitimate can be highly subjective and context-dependent. What might appear as a phishing attempt to one person could be a legitimate operation to another.
As of 2024, there are approximately 1.13 billion websites on the internet, of which around 201.9 million are actively maintained and regularly updated. Each of these websites often consists of many different subdomains, all of which receive certificates, the large majority via automation with no opportunity for manual content inspection.
Simply put, this is a scale of a problem that does not lend itself to manual review or subjective assessments of phishing. But it gets worse.
There are around 86 WebPKI trusted certificate authorities on the web today, many of which operate with just a handful of people. Beyond that, though they exist to serve the whole web, they are in many different legal jurisdictions around the world, each with its own cultural norms and expectations. However, the web is an international asset, and if we were to rely on CAs to be the content police on the web, we would have hugely inconsistent results, especially given the current rules.
It is also worth noting if the decision-making power regarding content trustworthiness is applied at the domain name control verification, users are disempowered and it begins to resemble censorship rather than protection. Users should have the ability to choose what kind of subjectivity they want when it comes to protecting themselves from malicious content.
So why don’t we just make the rules clearer on what constitutes appropriate content? Most would agree this is a hugely difficult problem, but even if we put that aside, the reality is that CAs visit websites only at issuance time, often before there is any content published, since SSL is a requirement for a website to even launch. Beyond that, websites often serve different content to different users. In my last role at Microsoft, I was responsible for security engineering for the advertising business. Malicious advertisers would often serve Microsoft IP addresses content that met our policies but serve other users content that violated our policies. So even if CAs did check for phishing, all the phishers would need to do is serve clean content to the CA or change the content after the fact.
Beyond that, there is the question of how a CA would respond to finding a website hosting phishing content. They could revoke it, but as I mentioned earlier, often the website hosting content has been compromised in some way, and revoking that certificate would impact that other website. For example, it’s not uncommon to see phishing content served through shared services like drive.google.com or S3 bucket URLs. Revoking that certificate would impact all of those users, that is if revocation was actually effective, but it is not.
Revocation services like OCSP and CRL repositories are often so slow or unreliable that browsers were never able to deploy what we call hard fail revocation. This means that even when a certificate is revoked, the revocation message might never reach the browser for various reasons, so the CA may feel better that they have revoked the certificate, but in practice, it would at best deliver inconsistent results, making the web less reliable without actually addressing the real problems that enable phishing.
For more insights on the challenges and limitations of CAs in fighting phishing and malware, check outLet’s Encrypt’s post on “The CA’s Role in Fighting Phishing and Malware”.
So What Can We Do to Help with the Problem of Phishing?
To effectively combat phishing, we need a robust reputation system that continuously monitors content over time from many different network perspectives. This includes residential IPs, commercial ones, and more. Here are just a few examples of things we could look at with such a service:
- Analyze Domain Registration: Look at the age and subject of the domain registration and the registrar of the domain since some are used more commonly than others.
- Examine Hosting Providers: Identify patterns in hosting providers serving the content, as certain providers may be more frequently associated with phishing activities.
- Inspect Website Scripts: Evaluate the JavaScript on the website to understand its functionality and detect potentially malicious behavior.
- Assess Content Similarity: Compare the content served by the website to other known websites to identify similarities that might indicate phishing.
- Utilize Machine Learning Models: Feed all of this data into well-trained machine learning models to generate probability scores indicating the likelihood of phishing.
This system should be integrated into user agents, such as browsers, so phishing checks can occur as part of the rendering process, providing real-time protection for users. Technologies like Google Safe Browsing and Microsoft SmartScreen already do some of this, and similar projects are often staffed with hundreds of engineers and other professionals. They deal with recourse for mislabeling, monitor false positives and false negatives, and tweak algorithms to improve solutions, all while designing privacy-preserving methods.
Are these services perfect? Absolutely not! Can they improve? The answer is unquestionably yes, but the key thing is that ad hoc censorship at issuance time by CAs is simply not the answer. It makes the web less reliable and at best offers a false sense of value in exchange for giving CAs a market message that they are fighting phishing when in reality they deliver no material value to the problem.