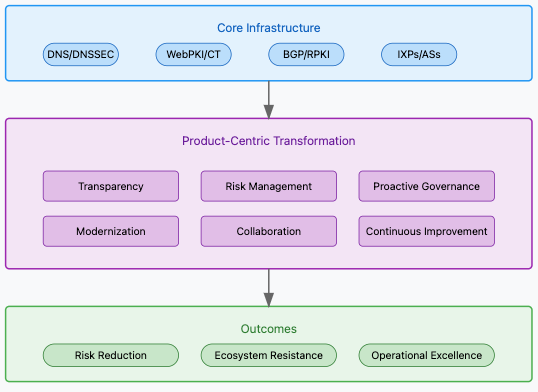
The internet rests on a foundation of core infrastructure components that make global communication possible. Among these load-bearing elements are DNS, DNSSEC, BGP, BGPsec, WebPKI, RPKI, transparency logs, IXPs, Autonomous Systems, and various registries. This includes critical governance bodies like ICANN and IANA, standards bodies like the CA/Browser Forum. These systems don’t just enable the internet – they are the internet, forming the critical backbone that allows us to establish secure connections, route traffic reliably, and maintain operational trust across the global network.
The PKI and transparency mechanisms that support these systems, particularly WebPKI, RPKI, and Certificate Transparency, are especially critical load-bearing elements essential to delivering the internet’s net value. When these foundational elements fail, they don’t just impact individual services – they can undermine the security and reliability of the entire internet infrastructure and erode the fundamental trust that billions of users and organizations place in the internet. This trust, once damaged, is difficult to rebuild and can have lasting consequences for how people interact with and rely upon digital services.
This foundational role makes the governance of root programs, which oversee these trust systems, absolutely critical. Yet recent incidents and historical patterns suggest we need to improve how we approach their governance. While no root program is perfect, and some have made significant strides in adopting product-focused practices and proactive risk management, there remains substantial room for improvement across the ecosystem. This framework isn’t meant to dismiss current efforts, but rather to synthesize best practices and push the conversation forward about how we can collectively strengthen these critical trust anchors.
To transform root programs from reactive administrative functions into proactive product-driven systems, we need a clear framework for change. This starts with defining our core mission, establishing a vision for the future state we want to achieve, and outlining the strategic pillars that will get us there.
Mission
To safeguard global trust in internet infrastructure by managing systemic risks, driving technical innovation, fostering transparent governance, and building durable systems that serve generations to come.
Vision
A resilient and adaptive trust ecosystem where:
- Governance is proactive and risk-aware, balancing technical rigor with user-centric principles
- Infrastructure and processes are continuously validated, transparent, and simplified
- Collaboration fosters innovation to address emerging challenges and deliver long-term security
Strategy
1. Transparency and Accountability
- Establish robust public verifiability for all CA operations, leveraging tools like transparency logs and continuous compliance monitoring
- Communicate decisions on inclusion, removal, reentry, and policy changes openly, ensuring stakeholder trust
- Build mechanisms for regular stakeholder feedback and confidence measurement, ensuring the ecosystem remains responsive to both technical and user needs
2. Integrated Risk Management
- Apply blast radius management to minimize the impact of failures, for example by segmenting trust dependencies and ensuring risks remain contained
- Use real-time monitoring and automated enforcement to detect and mitigate systemic risks
- Implement standardized processes for risk assessment and mitigation
3. Proactive Governance
- Shift from reactive to anticipatory governance by identifying potential risks and implementing early countermeasures
- Leverage automated monitoring and enforcement to prevent and catch issues before they become incidents
- Maintain clear lifecycle management processes for all ecosystem participants
4. Modernization and Simplification
- Establish WebPKI governance primacy for included roots and minimize cross-ecosystem trust relationships
- Limit what each CA is trusted for, reducing complexity and narrowing the scope of potential failures
- Employ these measures as part of broader blast radius management strategies
5. Collaborative Ecosystem Building
- Support and fund foundational open-source projects and critical infrastructure that the ecosystem depends on
- Implement shared accountability mechanisms, ensuring all ecosystem participants bear responsibility for maintaining trust and integrity
- Encourage CAs to align their policies not only with their own standards but also with aggregated internet governance policies, and best practices, especially for global use cases like TLS
- Partner with browsers, CAs, and researchers to co-develop solutions for current and emerging threats
- Foster an environment of mutual respect and constructive partnership
6. Commitment to Continuous Improvement
- Drive decisions through data collection, measurement, and empirical analysis
- Evolve policies based on quantitative feedback, incident analyses, and advancements in technology
- Regularly reassess and refine program criteria to remain relevant and effective
- Maintain clear processes for managing organizational transitions
The Stakes Are Higher Than Ever
The history of CA failures tells a sobering story – major CA distrust events occur on average every 1.23 years, each one threatening the foundation of trust that enables secure internet communication. These aren’t isolated incidents but rather represent recurring patterns of systemic failures in CA operations and governance.
Consider the range of critical failures we’ve seen: From DigiNotar’s complete infrastructure compromise in 2011 leading to rogue Google certificates to TURKTRUST’s “accidental” intermediate certificates in 2013, to government-affiliated CAs repeatedly undermining trust through deliberate actions or “accidents.” Take for example the ICP-Brasil case, where a root that had announced the end of SSL issuance continued to issue certificates months later – demonstrating how root programs’ decisions (or lack thereof) to maintain trust in roots that should no longer be part of the WebPKI can create unnecessary risks.
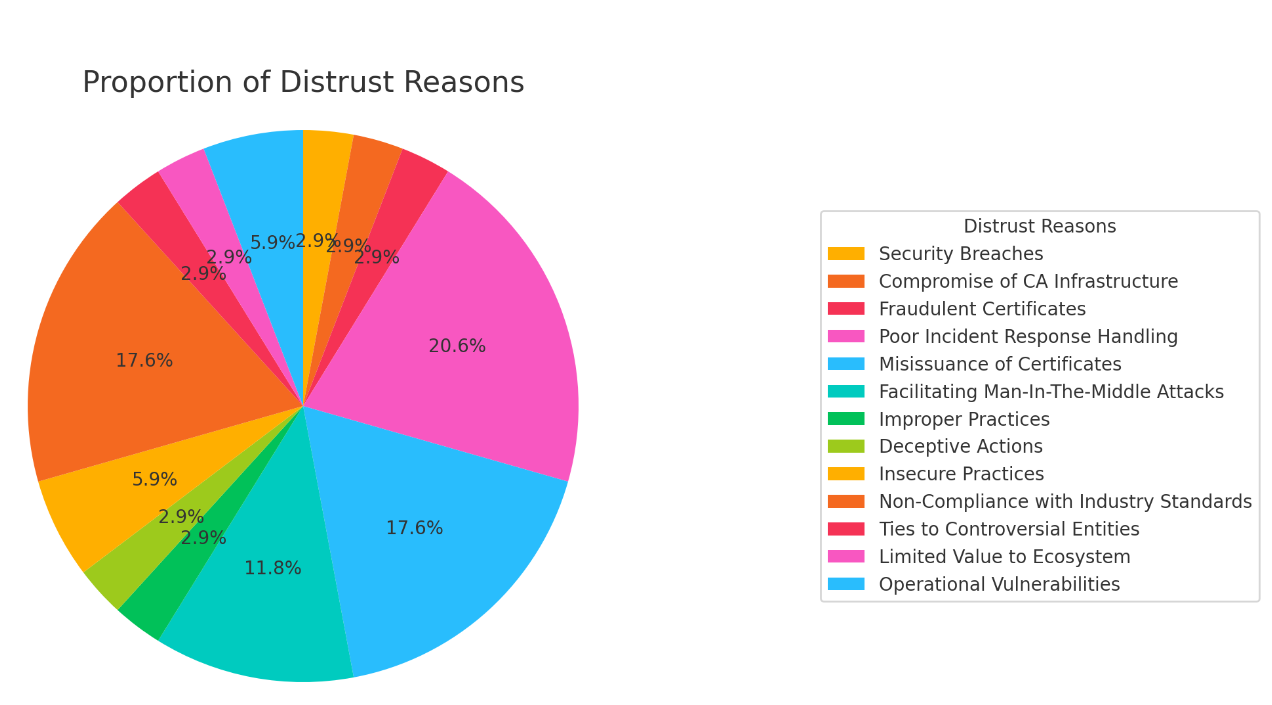
These incidents follow disturbingly consistent patterns:
- Security breaches and infrastructure compromises that enable unauthorized certificate issuance
- Systematic misissuance of certificates that undermine the entire trust model
- Poor incident response handling that compounds initial failures
- Non-compliance with industry standards despite clear requirements
- Operational vulnerabilities that go unaddressed until it’s too late
- Deceptive actions that breach the fundamental trust of the ecosystem
The Economic Reality
The current ecosystem suffers from fundamentally misaligned incentives. Root programs are typically run by browser vendors as a necessary cost of doing business, often competing with commercial priorities for resources and attention. Meanwhile, CAs face strong pressure to maintain their trusted status but weak incentives to uphold rigorous security practices. When security failures occur, users bear the cost while CAs often face minimal consequences. This economic reality is compounded by an ineffective auditing system where CAs select and pay their own auditors – reminiscent of the dynamics that enabled financial scandals like Wirecard and Enron.
The Long Tail Problem
A particularly concerning aspect of the current system is the “long tail” of rarely-used CAs. Many root certificates in browser trust stores belong to CAs that issue only dozens to hundreds of certificates annually, yet they maintain the same broad trust as major CAs issuing millions. These low-volume CAs pose risks that far outweigh their utility, creating unnecessary attack surfaces in our trust infrastructure. Regular assessment of each CA’s ongoing value to the ecosystem, balanced against their inherent risks, should inform continued inclusion in trust stores. This approach ensures the ecosystem maintains an appropriate balance between accessibility and security.
The Product-Centric Approach
To address these challenges, root programs must evolve from administrative oversight roles to become proactive, risk-managed entities. Here’s how a product-centric framework can transform root program governance:
1. Transparency and Accountability
- Implement robust public verifiability for all CA operations
- Leverage transparency logs and continuous compliance monitoring
- Ensure open communication about inclusion, removal, and policy changes
- Require automated reporting of security incidents and operational compliance
2. Blast Radius Management
- Segment trust dependencies to contain potential failures
- Implement dedicated hierarchies for specific use cases
- Limit CA trust scope to reduce complexity and narrow failure impacts
- Deploy real-time monitoring and automated enforcement
3. Risk-Based Governance
- Move from reactive to anticipatory governance
- Apply different levels of scrutiny based on CA context and risk profile
- Regularly assess whether each CA’s utility justifies its risks
- Implement meaningful technical restrictions on certificate issuance
4. Modernization and Simplification
- Establish and maintain WebPKI governance primacy
- Implement dedicated hierarchies for specific use cases
- Limit CA trust scope to reduce complexity and narrow failure impacts
- Deploy real-time monitoring and automated enforcement
5. Shared Accountability
- Support and fund critical infrastructure and monitoring
- Foster collaboration between browsers, CAs, and researchers
- Establish clear responsibilities across all ecosystem participants
- Create incentives that align with security goals
- Balance rigorous oversight with constructive partnership
- Develop clear processes for managing CA transitions and lifecycle events
Measuring Success
Like any product, root programs need clear metrics for success:
1. Risk Reduction
- Track mis-issuance rates and time-to-remediate
- Measure decrease in systemic vulnerabilities
- Monitor adoption of proactive security measures
- Track stakeholder confidence through regular surveys
2. Ecosystem Resistance
- Assess recovery capabilities from disruptions
- Track implementation and effectiveness of blast radius containment measures
- Monitor CA inclusion, removal, and reentry success rates
3. Operational Excellence
- Monitor CA inclusion and removal process efficiency
- Track adoption of modern security and governance practices
- Measure response times to security incidents and evaluate the thoroughness of incident handling
- Evaluate lifecycle management process consistency and post-incident improvements
Lifecycle Excellence
The sustainability of root programs depends on having clear, repeatable processes for managing the complete lifecycle of CAs – from inclusion to potential removal. This includes:
- Standardized onboarding and transition procedures
- Regular assessment checkpoints
- Clear criteria for maintaining trusted status
- Efficient processes for handling CA turnover
- Proactive planning for ecosystem evolution
The Trust Paradox
One of the most challenging aspects of root program governance is the inherent contradiction between trust and security. As we’ve seen with government-affiliated CAs and others, institutional incentives often directly conflict with security goals. A product-centric approach helps address this by:
- Implementing consistent risk evaluation frameworks that account for different institutional incentives and constraints
- Requiring proactive enforcement rather than post-incident reactions
- Creating clear, measurable criteria for ongoing trust
- Establishing automated compliance checks and monitoring
- Establishing feedback loops between governance bodies, CAs, and end-users to maintain alignment
The Path Forward
Root programs must continue evolving beyond reactive governance and inconsistent enforcement. By adopting a product mindset that emphasizes continuous improvement, measurable outcomes, and proactive risk management, we can build an even more resilient trust ecosystem.
Immediate actions should include:
- Implementing automated compliance monitoring
- Establishing clear criteria for CA risk assessment
- Developing robust blast radius management strategies
- Creating transparent processes for trust decisions
- Supporting proper funding for monitoring infrastructure
- Implementing standardized CA lifecycle management processes
- Building collaborative frameworks that balance accountability with mutual trust
Conclusion
The security of the internet depends on root programs functioning effectively. By treating them as products rather than administrative functions, we can build a more secure, transparent, and reliable trust ecosystem. This transformation won’t be easy, but the cost of maintaining the status quo – as evidenced by the long history of failures – is simply too high.
The question isn’t whether we need root programs – we absolutely do. The question is how we can continue evolving them to meet the security challenges of today’s internet. A product-centric approach, focused on proactive risk management and measurable outcomes, offers our best path forward.