Many enterprise products these days have a core architecture that consists of placing a proxy in front of an existing service. While the facade architecture makes sense in some cases, it’s usually a temporary measure because it increases the costs of administration, scaling, security, and debugging. It also adds complexity to general management.
The use cases for these offerings often involve one team in an organization providing incremental value to a service operated by another team. This introduces various organizational politics, which make anything more than a proof of concept not really viable, at least on an ongoing basis.
Essentially, anyone who has ever carried a pager or tried to deploy even the most basic system in a large enterprise should avoid this pattern except as a stopgap solution for a critical business system. It is far better, in the medium and long term, to look at replacing the fronted system with something that provides the needed integration or capability natively.
For example, some solutions aim to enable existing systems to use quantum-secure algorithms. In practice, these solutions often look like a single TLS server sitting in front of another TLS server, or a TLS-based VPN where a TLS client (for example, integrating via SOCKS) interfaces with your existing TLS client, which then communicates with that TLS server sitting in front of another TLS server. You can, of course, implement this, and there are places where it makes sense. However, on a long-term basis, you would be better off if there were native support for quantum-secure algorithms or switching out the legacy system altogether.
Similarly, it’s very common now for these enterprise-focused solutions to split the architecture between on-premise/private cloud and a SaaS component. This approach has several benefits: the on-premise part enables integration, core policy enforcement, and transaction handling, and, if done right, ensures availability. The SaaS component serves as the control plane. This combination gives you the best benefits of both on-premise and SaaS offerings and can be implemented while minimizing the security impact of the service provider.
Another pattern that might be confused with this model is one where transactional policy enforcement or transaction handling happens in the SaaS part of the solution, while the integration element remains on-premise. This is probably the easiest to deploy, so it goes smoothly in a proof of concept. However, it makes the SaaS component mission-critical, a performance bottleneck, and a single point of failure, while also pulling it entirely into the threat model of the component. There are cases where this model can work, but for any system that needs to scale and be highly reliable, it’s often not the best choice.
These architectural decisions in third-party solutions have other large impacts that need to be considered, such as data residency and compliance. These are especially important topics outside the US but are also issues within the US if you handle sensitive data and work in regulated markets. Beyond that, architecture and design choices of third-party products can have vendor lock-in consequences. For example, if the solution is not based on open standards, you may find yourself in an inescapable situation down the road without a forklift upgrade, which is often not viable organizationally if the solution fails to deliver.
So why does all of this matter? When we evaluate the purchase of enterprise security software, we need to be sure to look beyond the surface, beyond the ingredient list, and understand how the system is built and how those design decisions will impact our security, availability, performance, maintainability and total cost of ownership both in the near term and long term. Enterprise architects and decision-makers should carefully consider these factors when evaluating different architectural patterns.
At Black Hat this year, I did my usual walk around the vendor floor. I talked to lots of companies about their products. One thing that stood out to me is vendors either by accident or on purpose are redefining terms in a way that does harm. One vendor in particular was calling “bearer tokens” “attestations” in both their marketing and product documentation. Let’s use this as an example and break down why this matters.
What’s an attestation?
An attestation is when someone says something is true and puts their reputation behind that statement. It’s like when your friend vouches for you at a new job. A good technology example is a TPM attestation. The TPM in your computer can prove certain things about how your machine started up. When we trust the chip’s design and the company that made it, we can believe what it tells us.
What’s a claim?
A claim is just something someone says. It might be true, but there’s no proof. If I tell you my name is Ryan Hurst, that’s a claim. I haven’t shown you my ID or anything. Claims can also be about other people or things. If I say Cloudflare is safe to use, that’s just my opinion unless I back it up with something.
What’s a bearer token?
A bearer token is like a temporary password. It’s a secret that proves who you are to a service. Anyone who has the token can pretend to be you. We use them because they’re necessary, but we try to limit their use in modern systems.
You usually get a bearer token by trading in something more permanent, like an API key, which is essentially a long-lived password. It’s like swapping a house key for a hotel room key. The hotel key only works for a short time, but anyone who finds it can get into your room.
Why does any of this matter?
When companies use the wrong terms to explain what they do it can lead people to make bad security choices. For example, If you hear a vendor say their system relies on bearer tokens and then you do a search on the term, you’ll find experts talking about their risks and how to manage them. But if you search for attestations, you’ll find different info about how they help prove things are reliable, trustworthy or factual.
If a company selling security products tells you it does one thing, but it does another, it’s a bad sign. They either have some technical debt buried in the design that may have a negative impact, don’t know what they’re talking about, or they’re trying to confuse you. Either way, you might want to look at other options.
So, when you’re buying security products for your company, pay attention to how vendors use words. If they’re changing the meaning of important terms, be careful. It could mean you’re not getting what you think you are.
When we discuss “secure by design,” we often focus on capabilities, features, and defaults—such as logging and monitoring, default-deny, regular updates, authentication, and minimizing by default privileges—rather than focus on the word “design.” Don’t get me wrong; those things are important. But if we have learned anything from the last several decades of evolving security practices, it is that security features and settings alone do not make for secure products.
For instance, the recent CrowdStrike outages and the Microsoft Storm 0558 incident illustrate that design choices have a significant impact on the security and reliability of a system. So what does it mean to have a secure “design” then?
The whole concept of interconnected systems was bolted onto the way computers work. We didn’t even see a TCP/IP stack included by default in an operating system until BSD did this in 1983. Microsoft Windows didn’t get a TCP/IP stack until 1994, around the same time TISFWTK was released, which was a framework to build a firewall, not a firewall itself. For some, these developments may seem like ancient history; however, the methods we use to build and secure software and systems have evolved from this bolt-on approach to security.
“The beginning is the most important part of the work.” — Plato
In my view, a secure design incorporates an understanding of the entire lifecycle of a system. It recognizes that the question is not if it will be hacked, but when. It then employs questions such as “How do you reduce the chances of that happening?” and “How can you make it easy to recover when it does?” to inform the system’s shape.
The Storm case is a great example of insecure design. Loading extremely valuable keys into memory on a front-end machine, in the user context of code parsing user-supplied data, enabled an unauthenticated user on the internet to trigger a memory dump that exposed the key to theft via another attack vector. At a minimum, this key should have been kept in a separate user process, one that operated at a different permission level.
Similarly, the update mechanism for CrowdStrike’s ‘signatures’ functioned like a command and control network for a large array of bots installed on mission-critical systems. The fact that they could, in essence, push code at runtime, at will into the kernel privilege space of their customers means that a malicious actor with access to these systems could push malicious code onto all of those endpoints simultaneously. This insecure design choice put customers in a precarious position, making CrowdStrike’s update system a direct and uncontrollable method for compromising their systems.
How Did We Get Here?
Today, much of the software we depend on still carries the legacy of this bolt-on approach to security. This led the industry to adopt compliance and audit standards similar to the programs used in financial services, such as the Sarbanes-Oxley Act, which paved the way for standards like ISO 27001 and PCI DSS which aspired to manage this risk. However, these measures, like the financial audits that preceded them and missed major frauds such as those at Enron and Wirecard, unsurprisingly also often fail to prevent significant security risks.
This in turn led to a shift towards posture management, where products aimed at risk discovery have proliferated. However, these solutions predominantly focus on identifying potential problems and leave the filtering and remediating of them to IT security, thereby turning into a flurry of risk mitigation tasks rather than identifying the root causes and manifesting into design changes that would fundamentally reduce the risk. These approaches are symptomatic of a broader issue in security—treating the symptoms of poor foundational security rather than addressing the root causes.
Alongside these developments, the last few decades have seen massive growth in the adoption of distributed computing technologies, which first led to MSPs, then SaaS, and now cloud computing. This brought about the concept of shared responsibility, where security is managed as an incremental part of “solving the problem” for the buyer, allowing them to focus on their core business. For many, if not most business problems, this is the right way to go but it also often complicates accountability and obscures the visibility of security controls, sometimes exacerbating the very issues it seeks to mitigate.
Is It Really That Bleak?
At first glance, this all might seem pretty dire. After all, we do not get to replace all the technology we depend on at once, and even if we could, these new solutions will always come with their own problems. However, we must accept that you can’t effectively retrofit “secure by design” onto an existing system—or if you do, at best it will take decades to replace poorly designed bits and pieces of those existing systems. Even when improvements do occur, as we saw with Microsoft’s Trustworthy Computing initiative, eventually the organization may lose focus and start to regress, leaving us on a rollercoaster of empty promises.
We have seen some organizations take this to heart; a good example is Google. They built their infrastructure and processes on platforms that address foundational issues, allowing the vast majority of their developers to remain largely unaware of the broad spectrum of security challenges that operating services like theirs are subject to. For instance, most Google developers couldn’t tell you much about the infrastructure that runs their code. They build on top of mandated frameworks that “make the right thing the easy thing,” enabling the central security organization to perform core security functions.
A telling example of the design of these systems is how the entire concepts of authentication, authorization, and encryption are abstracted away from the developer, so they largely just happen automatically. To be clear, this approach is not without its faults, and Google’s systems are neither perfect nor suitable for all types of workloads. However, the base principles applied here are fairly universal: Make investments in infrastructure design upfront to ensure that the systems built on them are secure, well, by design.
We are starting to see the industry come around to this reality with the advent of platforms like Kubernetes and infrastructure such as SPIFFE (the Secure Production Identity Framework For Everyone), which are designed to foster environments where security is integrated at the core rather than being an add-on but this is just the beginning of this focus on incorporating security infrastructure into the way we build, not the end.
Conclusion
What is necessary is a cultural shift in how we approach design. For this to happen, customers need to start demanding transparency from vendors about how their systems are designed, assessed, operated, and serviced. Part of this responsibility involves conducting their own assessments and not relying solely on blind faith. The recent recognition on supply chain risks and global scale outages is a direct result of such blind trust.
By demanding vendors to provide a comprehensive narrative on how they’ve built their systems to be secure, rather than merely listing security features, and by engaging in initial and continuous technological due diligence to hold them accountable, we can hasten the transition to a world where security is woven into the fabric of every system, not merely added as an afterthought.
In conclusion, while we are just at the beginning of this journey and will have to continue managing systems that were not designed with transparent “secure by design” principles for decades, the direction is clear. We are moving towards a world where code, as well as users, are authenticated, and automated intelligent systems that utilize expert systems and AI evaluate whether systems are regressing or living up to their promises. If we continue on this path, our children and grandchildren may have the opportunity to live in a world that is inherently more secure, or at the very least, they will be better equipped to manage the security risks associated with the massive expansion of technology that we rely on daily.
Phishing attacks often begin with a seemingly simple email. These emails appear to be from trusted sources and include links to fake websites or messages that create a false sense of urgency, prompting users to act without considering the consequences. Once on the phishing site, everything looks familiar. Attackers meticulously copy the layout, design, and even the content from real websites. The only noticeable difference in a well-executed phishing site is where the data is submitted.
Although studies show that users typically do not scrutinize the address bar or understand URLs, some more technical users may check the domain name hosting the content as a last resort to verify its legitimacy. This approach, however, is problematic for several reasons:
Domain Confusion: Not everyone knows which domain is appropriate for which content. For example, TD Bank, N.A. issues co-branded credit cards for various companies. When paying your credit card bill online, you might see a domain name owned by TD Bank rather than the brand on your credit card.
Unrelated Legal and Domain Names: Company brands and their legal names often differ, as do their domain names. This discrepancy makes domain names more useful to attackers than to users for detection.
Furthermore, compromised websites from small businesses, churches, and other less technical organizations are frequently used to host phishing content. The key takeaway here is that content, not the domain name, is what makes a phishing campaign successful. The familiar look and feel of the content on phishing sites play a crucial role in deceiving users, making them less likely to question the site’s authenticity.
The Role of Certificate Authorities
Certificate authorities (CAs) in the web ecosystem exist to solve the trust-on-first-use problem introduced by our desire to protect the content we submit over the web from prying eyes (for more information, see TOFU and the Web). At its core, this problem arises because if you perform an anonymous key exchange or simply download the public key of a website from an unauthenticated source like DNS (while DNSSEC does technically exist, it is poorly adopted outside of TLDs), an attacker could replace the published key with one they control. This allows them to perform a man-in-the-middle (MITM) attack.
Certificate authorities are the answer to this problem. Browsers maintain a set of requirements that CAs must meet if they are to be distributed as “trusted” within their browsers (for more information, see Why We Trust WebPKI Root Certificate Authorities). In this ecosystem, browsers delegate solving the trust-on-first-use problem to the CAs. Essentially, they require CAs to prove that the requester of a certificate has administrative control over the domain and issue a certificate that attests to this. This enables browsers, as agents of the user, to assure the user that no one else should be able to intercept the information sent to the website (for some value of “website” — the modern website is made up of many third-party components that can potentially see your content also, but that’s a topic for another post).
Where things start to get tricky is how standards are defined. Anyone who works in a standards body knows that getting to a consensus is hard and often leads to less-than-ideal explanations of things. This is made worse by not everyone who participates understands the whole problem domain. Unfortunately, this is as true in the CA/Browser Forum as it is in other standards bodies. In the context of phishing, this comes into play in the “Baseline Requirements for the Issuance and Management of Publicly-Trusted TLS Server Certificates”, which has the concept of a “High-Risk Certificate Request” that states:
High-Risk Certificate Request: A Request that the CA flags for additional scrutiny by reference to internal criteria and databases maintained by the CA, which may include names at higher risk for phishing or other fraudulent usage, names contained in previously rejected certificate requests or revoked Certificates, names listed on the Miller Smiles phishing list or the Google Safe Browsing list, or names that the CA identifies using its own risk-mitigation criteria.
(It is worth noting Google Safe Browsing isn’t a list it is a web service…. sigh….)
And
The CA SHALL provide all personnel performing information verification duties with skills-training that covers basic Public Key Infrastructure knowledge, authentication and vetting policies and procedures (including the CA’s Certificate Policy and/or Certification Practice Statement), common threats to the information verification process (including phishing and other social engineering tactics), and these Requirements.
On its surface, this seems harmless enough. It doesn’t mandate that the CA do anything for phishing beyond training its validation staff about the contents but does allow them to do something about it if they can. After all, maybe they see phishing content and can stop the issuance altogether before a certificate is issued, preventing the use of SSL on the phishing site altogether. The problem is this all does more harm than good.
Why CAs Don’t Make Good Content Police
Determining whether content is phishing or legitimate can be highly subjective and context-dependent. What might appear as a phishing attempt to one person could be a legitimate operation to another.
As of 2024, there are approximately 1.13 billion websites on the internet, of which around 201.9 million are actively maintained and regularly updated. Each of these websites often consists of many different subdomains, all of which receive certificates, the large majority via automation with no opportunity for manual content inspection.
Simply put, this is a scale of a problem that does not lend itself to manual review or subjective assessments of phishing. But it gets worse.
There are around 86 WebPKI trusted certificate authorities on the web today, many of which operate with just a handful of people. Beyond that, though they exist to serve the whole web, they are in many different legal jurisdictions around the world, each with its own cultural norms and expectations. However, the web is an international asset, and if we were to rely on CAs to be the content police on the web, we would have hugely inconsistent results, especially given the current rules.
It is also worth noting if the decision-making power regarding content trustworthiness is applied at the domain name control verification, users are disempowered and it begins to resemble censorship rather than protection. Users should have the ability to choose what kind of subjectivity they want when it comes to protecting themselves from malicious content.
So why don’t we just make the rules clearer on what constitutes appropriate content? Most would agree this is a hugely difficult problem, but even if we put that aside, the reality is that CAs visit websites only at issuance time, often before there is any content published, since SSL is a requirement for a website to even launch. Beyond that, websites often serve different content to different users. In my last role at Microsoft, I was responsible for security engineering for the advertising business. Malicious advertisers would often serve Microsoft IP addresses content that met our policies but serve other users content that violated our policies. So even if CAs did check for phishing, all the phishers would need to do is serve clean content to the CA or change the content after the fact.
Beyond that, there is the question of how a CA would respond to finding a website hosting phishing content. They could revoke it, but as I mentioned earlier, often the website hosting content has been compromised in some way, and revoking that certificate would impact that other website. For example, it’s not uncommon to see phishing content served through shared services like drive.google.com or S3 bucket URLs. Revoking that certificate would impact all of those users, that is if revocation was actually effective, but it is not.
Revocation services like OCSP and CRL repositories are often so slow or unreliable that browsers were never able to deploy what we call hard fail revocation. This means that even when a certificate is revoked, the revocation message might never reach the browser for various reasons, so the CA may feel better that they have revoked the certificate, but in practice, it would at best deliver inconsistent results, making the web less reliable without actually addressing the real problems that enable phishing.
So What Can We Do to Help with the Problem of Phishing?
To effectively combat phishing, we need a robust reputation system that continuously monitors content over time from many different network perspectives. This includes residential IPs, commercial ones, and more. Here are just a few examples of things we could look at with such a service:
Analyze Domain Registration: Look at the age and subject of the domain registration and the registrar of the domain since some are used more commonly than others.
Examine Hosting Providers: Identify patterns in hosting providers serving the content, as certain providers may be more frequently associated with phishing activities.
Inspect Website Scripts: Evaluate the JavaScript on the website to understand its functionality and detect potentially malicious behavior.
Assess Content Similarity: Compare the content served by the website to other known websites to identify similarities that might indicate phishing.
Utilize Machine Learning Models: Feed all of this data into well-trained machine learning models to generate probability scores indicating the likelihood of phishing.
This system should be integrated into user agents, such as browsers, so phishing checks can occur as part of the rendering process, providing real-time protection for users. Technologies like Google Safe Browsing and Microsoft SmartScreen already do some of this, and similar projects are often staffed with hundreds of engineers and other professionals. They deal with recourse for mislabeling, monitor false positives and false negatives, and tweak algorithms to improve solutions, all while designing privacy-preserving methods.
Are these services perfect? Absolutely not! Can they improve? The answer is unquestionably yes, but the key thing is that ad hoc censorship at issuance time by CAs is simply not the answer. It makes the web less reliable and at best offers a false sense of value in exchange for giving CAs a market message that they are fighting phishing when in reality they deliver no material value to the problem.
Over the years, various efforts have worked towards addressing this challenge. These efforts aimed to solve the problem of undetectable modifications to these central key servers. For example:
CONIKS was the first academic attempt to create a key transparency framework that enabled users to verify the authenticity of keys in a privacy-preserving way without relying solely on the key server’s integrity.
Google Key Transparency, based on CONIKS, was Google’s effort to prove it was possible to deploy these patterns at an internet scale.
Apple Contact Discovery was the first deployment of these patterns for a large-scale messaging system.
Arguably the most successful and well-understood implementation of these patterns though is Facebook’s Auditable Key Directory (AKD), which is intended to be used across its messaging offerings but is already deployed with WhatsApp. Like the other solutions mentioned above, it is reliant on constant monitoring and verification to ensure global consistency, mitigating “Split View” attacks against its relying parties and ensuring these end-to-end encrypted messaging solutions maintain the promised security properties.
A research paper by Sarah Meiklejohn et al., titled “Think Global, Act Local: Gossip and Client Audits in Verifiable Data Structures” (https://arxiv.org/abs/2011.04551), set out to define a verifiable scheme to perform this verification in a cost-efficient and provable way. The essential idea in the paper is that the problem can be solved by gossiping the state of the underlying verifiable data structure across a network of perspectives. The goal is to ensure that relying parties verify they are seeing the same version of the directory as everyone else who is participating.
Introducing Google’s Armored Witness
Google’s Armored Witness project aims to operationalize this concept by providing a geographically distributed network of secure hardware-based “notaries.” Its design is based on custom hardware, the USB Armory, designed with security, verifiability, and maximal openness given commercially available components and associated constraints. It modifies the USB Armory by removing unused components and adding Power over Ethernet (PoE).
The USB Armory platform uses a Go unikernel design, which has many benefits. For one, Go naturally supports “reproducible builds,” meaning that any attempt to rebuild from an application’s source will yield the same binary. This is important because it enables the hardware to report what firmware it is running and map that back to the source, allowing you to understand what is happening inside.
The hardware itself also contains a trusted execution environment and a secure element that enables sensitive code to be isolated and the keys to be secured from many classes of logical and physical attacks. These keys are then used to do the “notarization” of their observation of these ledgers.
Hardware alone isn’t enough, though. We need a global network based on these devices so that relying parties can get assurance that an adequate number of network perspectives are seeing the same log contents.
Here’s how an integration of Google’s Armored Witness into Facebook’s AKD framework could work:
Log Integration and Epoch Consistency: By integrating Armored Witness into the AKD framework, each Armored Witness device can act as a witness to a log of AKD epoch roots. Specifically::
Log Integration: Each AKD epoch root is added to the log, such that the Nth epoch root is present at the Nth log index.
Witness Network: The witness network, comprising Armored Witness devices, counter-signs checkpoints from these logs, providing an additional layer of verification.
Client-Side Verification: As the AKD is updated, AKD clients are provided with epoch update bundles, which include:
Clients verify these bundles by:
Checking the signature on the directory epoch root.
Verifying the countersignatures on the log checkpoint.
Using the inclusion proof to confirm the correct log position of the epoch root, ensuring that the Nth root is in the Nth log position.
Split View Protection: The distributed nature of Armored Witness devices ensures that:
Split views of the log are prevented due to the geographically distributed countersigning by the witness network.
The log sequence number matches the directory epoch number, maintaining a strict one-to-one correspondence.
Heavy Lift Verifiers: Heavy lift verifiers, which perform more in-depth consistency checks, can source epoch roots from the log for pairwise append-only verification. This process ensures the correct operation of the directory over time, further strengthening the security framework.
The new directory epoch root commitment.
Inclusion proof hashes for the epoch root in the log.
The countersigned log checkpoint.
Conclusion
Integrating Google’s Armored Witness with Facebook’s AKD framework offers a simple solution to a very hard problem. More importantly, adopting this approach not only addresses the split-view problem for Facebook but also provides a substrate that can protect all verifiable data structures.
By leveraging a generic network of geographically distributed Armored Witness devices, solutions dependent on verifiable data structures to prove integrity, such as AKD deployments, can achieve robust split-view protection, ensuring integrity and authenticity across different regions.
Incident response is notoriously challenging, and with the rise in public reporting obligations, the stakes have never been higher. In the WebPKI world, mishandling incidents can severely damage a company’s reputation and revenue, and sometimes even end a business. The Cyber Incident Reporting for Critical Infrastructure Act of 2022 has intensified this pressure, requiring some companies to report significant breaches to CISA within 72 hours. This isn’t just about meeting deadlines. The stakes are high, and the pressure is on. Look at the recent actions of the Cyber Safety Review Board (CSRB), which investigates major cyber incidents much like how plane crashes are scrutinized. The recent case of Entrust’s cascade of incidents in the WebPKI ecosystem, and the scrutiny they have gone under as a result, shows how critical it is to respond professionally, humbly, swiftly, and transparently. The takeaway? If you don’t respond adequately to an incident, someone else might do it for you, and even if not, mishandling can result in things spiraling out of control.
The Complexity of Public Reporting
Public reports attract attention from all sides—customers, investors, regulators, the media, and more. This means your incident response team must be thorough and meticulous, leaving no stone unturned. Balancing transparency with protecting your organization’s image is critical. A well-managed incident can build trust, while a poorly handled one can cause long-term damage.
Public disclosures also potentially come with legal ramifications. Everything must be vetted to ensure compliance and mitigate potential liabilities. With tight timelines like the CISA 72-hour reporting requirement, there’s little room for error. Gathering and verifying information quickly is challenging, especially when the situation is still unfolding. Moreover, public reporting requires seamless coordination between IT, legal, PR, and executive teams. Miscommunication can lead to inconsistencies and errors in the public narrative.
The Role of Blameless Post Mortems
Blameless post-mortems are invaluable. When there’s no fear of blame, team members are more likely to share all relevant details, leading to a clearer understanding of the incident. These post-mortems focus on systemic issues rather than pointing fingers, which helps prevent similar problems in the future. By fostering a learning culture, teams can improve continuously without worrying about punitive actions.
It’s essential to identify the root causes of incidents and ensure they are fixed durably across the entire system. When the same issues happen repeatedly, it indicates that the true root causes were not addressed. Implementing automation and tooling wherever possible is crucial so that you always have the information needed to respond quickly. Incidents that close quickly have minimal impact, whereas those that linger can severely damage a business.
Knowing they won’t be blamed, team members can contribute more calmly and effectively, improving the quality of the response. This approach also encourages thorough documentation, creating valuable resources for future incidents.
Evolving Public Reporting Obligations
New regulations demand greater transparency and accountability, pushing organizations to improve their security practices. With detailed and timely information, organizations can better assess and manage their risks. The added legal and regulatory pressure leads to faster and more comprehensive responses, reducing the time vulnerabilities are left unaddressed. However, these strict timelines and detailed disclosures increase stress on incident response teams, necessitating better support and processes. Additionally, when there are systemic failures in an organization, one incident can lead to others, overwhelming stakeholders and making it challenging to prioritize critical issues.
Importance of a Strong Communication Strategy
Maintaining trust and credibility through transparent and timely communication is essential. Clear messaging prevents misinformation and reduces panic, ensuring stakeholders understand the situation and response efforts. Effective communication can mitigate negative perceptions and protect your brand, even in the face of serious incidents. Proper communication also helps ensure compliance with legal and regulatory requirements, avoiding fines and legal issues. Keeping stakeholders informed supports overall recovery efforts by maintaining engagement and trust.
Implementing Effective Communication Strategies
Preparation is key. Develop a crisis communication plan that outlines roles, responsibilities, and procedures. Scenario planning helps anticipate and prepare for different types of incidents. Speed and accuracy are critical. Provide regular updates as the situation evolves to keep stakeholders informed.
Consistency in messaging is vital. Ensure all communications are aligned across all channels and avoid jargon. Transparency and honesty are crucial—acknowledge the incident and its impact, and explain the steps being taken to address it. Showing empathy for those affected and offering support and resources demonstrates that your organization cares. Keep employees informed about the incident and the organization’s response through regular internal briefings to ensure all teams are aligned and prepared to handle inquiries.
Handling Open Public Dialogues
Involving skilled communicators who understand both the technical and broader implications of incidents is crucial. Coordination between legal and PR teams ensures that messaging is clear and accurate. Implement robust systems to track all public obligations, deadlines, and commitments, with regular audits to ensure compliance and documentation. Prepare for potential delays or issues with contingency plans and pre-drafted communications, and proactively communicate if commitments cannot be met on time.
Communication with Major Customers: It often becomes necessary to keep major customers in the loop, providing them with timely updates and reassurances about the steps being taken. Build plans for how to proactively do this successfully.
Clear Objectives and Measurable Criteria: Define clear and measurable criteria for what good public responses look like and manage to this. This helps ensure that all communications are effective and meet the required standards.
External Expert Review: Retain external experts to review your incidents with a critical eye whenever possible. This helps catch misframing and gaps before you step into a tar pit.
Clarity for External Parties: Remember that external parties won’t understand your organizational structure and team dynamics. It’s your responsibility to provide them with the information needed to interpret the report the way you intended.
Sign-Off Process: Have a sign-off process for stakeholders, including technical, business, and legal teams, to ensure the report provides the right level of information needed by its readers.
Track Commitments and Public Obligations: Track all your commitments and public obligations and respond by any committed dates. If you can’t meet a deadline, let the public know ahead of time.
In the end, humility, transparency, and accountability are what make a successful public report.
Case Study: WoSign’s Non-Recoverable Loss of Trust
Incident: WoSign was caught lying about several aspects of their certificate issuance practices, leading to a total non-recoverable loss of trust from major browsers and ultimately their removal from trusted root stores.
Outcome: The incident led to a complete loss of trust from major browsers.
Impact: This example underscores the importance of transparency and honesty in public reporting, as once trust is lost, it may never be regained.
Case Study: Symantec and the Erosion of Trust
Incident: Symantec, one of the largest Certificate Authorities (CAs), improperly issued numerous certificates, including test certificates for domains not owned by Symantec and certificates for Google domains without proper authorization. Their non-transparent, combative behavior, and unwillingness to identify the true root cause publicly led to their ultimate distrust.
Outcome: This resulted in a significant loss of trust in Symantec’s CA operations. Both Google Chrome and Mozilla Firefox announced plans to distrust Symantec certificates, forcing the company to transition its CA business to DigiCert.
Impact: The incident severely damaged Symantec’s reputation in the WebPKI community and resulted in operational and financial setbacks, leading to the sale of their CA business.
Conclusion
Navigating public reporting obligations in WebPKI and other sectors is undeniably complex and challenging. However, by prioritizing clear, honest communication and involving the right professionals, organizations can effectively manage these complexities. Rigorous tracking of obligations, proactive and transparent communication, and a robust incident response plan are critical. Case studies like those of WoSign and Symantec underscore the importance of transparency and honesty—once trust is lost, it may never be regained.
To maintain trust and protect your brand, develop a crisis communication plan that prioritizes speed, accuracy, and empathy. Consistent, transparent messaging across all channels is vital, and preparing for potential incidents with scenario planning can make all the difference. Remember, how you handle an incident can build or break trust. By learning from past mistakes and focusing on continuous improvement, organizations can navigate public reporting obligations more effectively, ensuring they emerge stronger and more resilient.
Imagine a world where every conversation, every movement, and every interaction is tracked in real-time by unseen eyes. This isn’t the plot of a dystopian novel—it’s a very real possibility enabled by today’s rapid technological advancements. As we develop and deploy powerful new tools, and maintain the ones that we built the internet on, the line between technology that makes our lives easier and invasive surveillance becomes increasingly blurred.
“In the future everyone will want to be anonymous for 15 minutes”, Banksy, 2011
This growing concern isn’t unfounded. In recent years, the push for censorship and surveillance has become more pronounced, driven by various geopolitical, social, and technological factors. While these measures often are framed around national sovereignty, combating terrorism, and protecting children, the unintended consequences could be far-reaching. Whether this occurs accidentally or purposely, the outcome can be equally invasive and harmful.
We stand at a point in history where the rapid development and deployment of new technologies, such as Microsoft’s Recall and Apple’s Private Cloud Compute, might inadvertently build the infrastructure that enables governments’ ultimate surveillance goals.
The advent of generative AI, which can extract insights at scale from video, audio, and text, opens the door to mass surveillance more than any other technology in history. These AI advancements enable detailed monitoring and analysis of vast amounts of data, making it easier for governments to track individuals and gain unprecedented insights into personal lives. To be clear, these technologies have amazing potential and are already making many people’s lives easier and making businesses more productive. In some cases, they also represent large and positive trends in privacy protection and should also give us faith in our ability to enable these innovations in a privacy-respecting way.
However, their use raises crucial questions about how we, as system designers, should evolve our philosophies on security and privacy.
A Timeline of Surveillance and Encryption Battles
Let’s take a step back and examine the historical context of government attempts to monitor citizens and the corresponding technological responses.
1990s
Introduction of technologies to enable government access, such as the Clipper Chip.
Backlash against government surveillance efforts and exposure of security flaws in Clipper Chip.
Encryption classified as a munition, leading to strict export control, an effort that held back security advancement for years..
2000s
Relaxation of U.S. export controls on encryption products in a tacit acknowledgment of its failure.
Expansion of law enforcement access to personal data through legislation like the USA PATRIOT Act.
2010s
Major leaks reveal extensive government surveillance programs.
Public debates over government backdoors in encryption.
Expansion of government surveillance capabilities through new legislation.
Proposals for key escrow systems and their criticisms from security experts.
2020s
Controversies over commercial companies their data collection and sale practices, and the use of the data by the government against citizens.
Legislative proposals and debates around encryption and privacy, such as the EARN IT Act.
EU pushes to limit CAs ability to remove EU CAs from their root programs and the mandated trust of EU CAs.
Tech companies’ attempts to implement on-device monitoring of your data and the ensuing backlash.
Suppression of legitimate discourse about COVID-19, leading to long-term impacts on public trust.
Ongoing legislative efforts to expand surveillance capabilities in the EU.
New Technologies and Surveillance Risks
Fast forward to today, and we are witnessing the rise of new technologies designed to make our data more useful. However, in our rush to build out these new capabilities, we might be inadvertently paving the way for government surveillance on an unprecedented scale.
To give this some color, let’s look back at another technological innovation: payphones. Payphones became widespread in the 1930s, and by the 1950s, the FBI under J. Edgar Hoover’s COINTELPRO program was using phone tapping to target civil rights organizations, feminist groups, and others advocating for political change. Regardless of your political leanings, we can all hopefully agree that this was an infringement on civil liberties.
Pay Phone in the Haight, San Francisco, 1967
Similarly, the advent of generative AI, which can extract insights at scale from video, audio, and text, opens the door to mass surveillance more than any other technology in history. These AI advancements enable detailed monitoring and analysis of vast amounts of data, making it easier for governments to track individuals and gain unprecedented insights into personal lives. While these technologies are useful they present a double-edged sword: the potential for more usable technology and improved productivity on one hand, and the risk of pervasive surveillance on the other.
Fast forward to the early 2000s, the USA PATRIOT Act expanded the surveillance powers of U.S. law enforcement agencies, laying the groundwork for extensive data collection practices. These powers eventually led to the Snowden revelations in 2013, which exposed the vast scope of the NSA’s surveillance programs, including the bulk collection of phone metadata and internet communications.
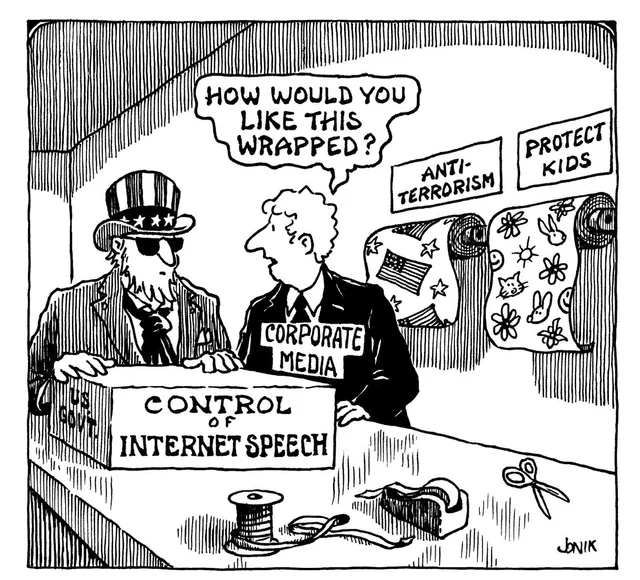
“How would you like this wrapped?” John Jonik, early 2000s
Clay Bennett, Christian Science Monitor, 2006
As George Santayana famously said, ‘Those who cannot remember the past are condemned to repeat it.’ Technological advancements intended to be used for good can enable detailed, real-time surveillance on a national or even global scale. This dual-use nature underscores the critical need for robust, transparent frameworks to prevent misuse and ensure these technologies align with our fundamental rights and freedoms.
Striking a Balance: Innovation and Vigilance
We do not want, nor can we afford, to be Luddites; this is a world economy, and time and technology move on. Nor do we want to let fear convince us to give up essential liberty to purchase a little temporary safety. Instead, we must strive to strike a balance between innovation and vigilance. This balance involves advocating for robust, transparent, verifiable, and accountable frameworks that ensure the use of technology aligns with our fundamental rights and freedoms.
For example, historically, many security practitioners have pushed back against the use of client-side encryption claiming it is a distraction from real security work because the software or service provider can bypass these protections. However, as we see now, applying these technologies serves as a useful tool for protecting against accidental leakage and for defense in depth more broadly. This change exemplifies the need to continually reassess and adapt our security strategies so they match the actual threat model and not some ideal.
An essential aspect of this balance is the governance of the foundational elements that ensure our privacy on the web. Root programs that underpin the WebPKI play a critical role in maintaining trust and security online. The WebPKI provides the infrastructure for secure Internet communication, ensuring that users can trust the websites they visit and the transactions they perform. Efforts to weaken this system, such as the eIDAS regulation in the EU, pose significant risks. Certificate Transparency (CT) logs, which provide a transparent and publicly auditable record of all certificates issued, are crucial for detecting and preventing fraudulent certificates, thus ensuring the infrastructure remains robust and reliable. Trusted root certificate authorities (CAs) must demonstrate principled, competent, professional, secure, and transparent practices, with continual review to maintain the WebPKI’s integrity. By protecting and strengthening these foundational elements, we ensure that the infrastructure supporting our digital world remains secure and trustworthy. This vigilance is crucial as we continue to innovate and develop new technologies that rely on these systems.
By protecting and strengthening these foundational elements, we ensure that the infrastructure supporting our digital world remains secure and trustworthy. This vigilance is crucial as we continue to innovate and develop new technologies that rely on these systems.
Here are several guiding principles to consider:
Transparency: Companies developing these technologies must be transparent about their data practices and the potential risks involved. Clear communication about how data is collected, stored, and used can help build trust.
Accountability: Ensuring accountability involves creating systems and processes that allow for oversight and verification of how data is handled. This can include audits, reports, and other mechanisms that demonstrate a company’s commitment to ethical data management.
Privacy by Design: Incorporating privacy features from the ground up is essential. Technologies should embed privacy controls, transparency encryption, as Private Cloud Compute does, as fundamental components, not as afterthoughts.
Legal and Ethical Standards: There must be robust legal frameworks and ethical standards governing the use of surveillance technologies. These frameworks should ensure that surveillance is conducted legally, with proper oversight, and that it respects individuals’ rights and is discoverable when it has been done so it is harder to abuse.
Public Dialogue and Advocacy: Engaging in public dialogue about the implications of these technologies is crucial. Advocacy groups, policymakers, and the tech industry need to work together to educate the public and advocate for policies that protect privacy and civil liberties.
Technological Safeguards: Implementing technological safeguards to prevent misuse is critical. This includes encryption, verifiable designs, and transparent audit-ability so reliance on blind faith isn’t a necessary precondition to ensure that surveillance capabilities are not abused.
The Role of the Tech Community
The tech community plays a pivotal role in shaping the future of these technologies. By fostering a culture of ethical development and responsible innovation, developers, engineers, and tech companies can influence how new tools are designed and deployed. This involves prioritizing user privacy and security at every stage of development and ensuring that these principles are not compromised for convenience or profit.
Historical examples demonstrate the effectiveness of this approach. The Clipper Chip breakage in the 1990s is a notable case where researchers exposed significant security flaws, proving that government-mandated backdoors can undermine overall security. More recently, the advocacy for end-to-end encryption (E2EE) and the supporting technologies showcase the tech community’s positive influence. Companies like WhatsApp, Signal and Apple have implemented E2EE, setting new standards for privacy and security in communications.
Continued innovation in this regard can be seen in developments like key transparency and contact discovery. Key transparency mechanisms allow users to verify that the encryption keys they are using have not been tampered with, minimizing the amount of trust required in service providers and showing leadership for the industry as a whole.
Developers should also advocate for and adopt open standards that enhance verifiability, auditability, security, and privacy. These standards can serve as benchmarks for best practices, helping to establish a baseline of trust and reliability in new technologies. Collaboration within the tech community can lead to the creation of robust, interoperable systems that are harder for malicious actors to exploit.
Additionally, academia plays a crucial role in this endeavor by researching and developing provably secure models for various technologies. Academic work often focuses on creating rigorous, mathematically sound methods for ensuring security and privacy. By integrating these academic findings into practical applications, we can build more secure and trustworthy systems. This partnership between industry and academia fosters innovation and helps establish a foundation for secure technology development.
Moreover, the tech community must actively engage in policy discussions. By providing expert insights and technical perspectives, they can help shape legislation that balances innovation with the protection of civil liberties. This engagement can also help policymakers understand the technical complexities and potential risks associated with surveillance technologies, leading to more informed and balanced decision-making.
And finally, important we help regulators understand that technology alone cannot solve deeply rooted social problems and over-reliance on technology will lead to unintended consequences. A balanced approach that integrates technology with thoughtful policy, ethical considerations, and social engagement is essential if we want to see effective changes.
Education and Awareness
Educating the public about the implications of these technologies is crucial. Many people may not fully understand how their data is collected, used, and potentially monitored. By raising awareness about these issues, we can empower individuals to make informed decisions about their digital privacy.
Educational initiatives can take many forms, from public awareness campaigns to integrating privacy and security topics into school curriculums. At the same time, we must be careful to recognize the concerns and motivations of those advocating for these cases. This is not a situation where preaching to the choir or pontificating about abstract possibilities will be effective. We must anchor this education in recent history and concrete examples to avoid sounding like zealots.
Conclusion
The increasing push for censorship and the risk of enabling government surveillance underscore the delicate balance between technological advancement and civil liberties. Emerging technologies bring both promise and peril, potentially enabling unprecedented surveillance.
To address these risks, we must advocate for transparency, accountability, and privacy by design. Establishing robust legal and ethical standards, engaging in public dialogue, and raising awareness about digital privacy are essential steps. The tech community must prioritize ethical development, adopt open standards, and participate in policy discussions to ensure that innovation does not come at the cost of individual rights.
In conclusion, while new technologies offer significant benefits, they also pose risks that demand careful management. By balancing innovation with vigilance, we can create a future where technology enhances usability without compromising our fundamental freedoms.
Despite the broad use of open source, the large majority of software is still delivered and consumed in binary form. There are a few reasons for this, but the most obvious is that the sheer size and complication of code bases combined with the limited availability of expertise and time within consuming organizations makes the use of the source to manage risk impractical.
At the same time, it’s clear this issue is not new, for example in 1984, Ken Thompson, in his Turing Award Lecture, mentioned, “No amount of source-level verification or scrutiny will protect you from untrusted code”. This statement has been partially vindicated recently, as intelligent code analysis agents, although faster ways to produce code, have been found to exert downward pressure on code quality while also reducing the developer’s understanding of the code they produce — a bad combination.
To the extent these problems are resolved we can expect the attackers to be using the same tools to more rapidly identify new and more complex attack chains. In essence, it has become an arms race to build and apply these technologies to both offensive and defensive use cases.
The saying “In the middle of difficulty lies opportunity” aptly describes the current situation, where numerous security focused startups claim to offer solutions to our problems. However, the truth is often quite different.
Some of those racing to take advantage of this opportunity are focusing on software supply chain security, particularly with a focus on software composition analysis. This is largely driven by regulatory pressures to adopt the Software Bill of Materials concept. Yet, most tools that generate these documents only examine interpreted code and declared dependencies. As previously mentioned, the majority of code is delivered and consumed in compiled form, leaving customers unable to assess its correctness and completeness without enough data to do so. As a result, although these tools may help with compliance, they inadvertently cause harm by giving a false sense of security.
There are other vendors still that are essentially scaling up traditional source code reviews using large language models (LLMs). But as we’ve discussed, these tools are currently showing signs of reducing code quality and developers’ understanding of their own code. At the same time these tools produce such a high volume of false positives given the lack of context this analysis has available to it triaging the outputs can turn into a full-time job. This suggests that negative outcomes could ensue over time if we don’t adjust how we apply this technology or see significant improvements in the underlying technology itself.
These efforts are all concentrated on the software creators but if we expand the problem domain to include the consumers of software we see that outside of cloud environments, where companies like Wiz and Aqua Security provide vulnerability assessments at scale, there are hardly any resources aiding software consumers in making informed decisions about the risks they face by the software they use. A big part of this is the sheer amount of noise even these products produce, combined with the lack of actionability in such data for the consumer of the software. With that said these are tractable problems if we just choose to invest in new solutions rather than apply the same old approaches we have in the past.
As we look toward the next decade, it is clear that software security is at a pivotal point, and navigating it goes beyond just technology; it requires a change in mindset towards more holistic security strategies that consider both technical and human factors. The next few years will be critical as we see whether the industry can adapt to these challenges.
Efforts have been made for years to detect modified content by enabling content-creation devices, such as cameras, to digitally sign or watermark the content they produce. Significant efforts in this area include the Content Authenticity Initiative and the Coalition for Content Provenance and Authenticity. However, these initiatives face numerous issues, including privacy concerns and fundamental flaws in their operation, as discussed here.
It is important to understand that detecting fakes differs from authenticating originals. This distinction may not be immediately apparent, but it is essential to realize that without 100% adoption of content authentication technology—an unachievable goal—the absence of a signature or a watermark does not mean that it is fake. To give that some color just consider that photographers to this day love antique Leica cameras and despite modern alternatives, these are still often their go-to cameras.
Moreover, even the presence of a legitimate signature on content does not guarantee its authenticity. If the stakes are high enough, it is certainly possible to extract signing key material from an authentic device and use it to sign AI-generated content. For instance, a foreign actor attempting to influence an election may find the investment of time and money to extract the key from a legitimate device worthwhile. The history of DVD CSS demonstrates how easy it is for these keys to be extracted from devices and how even just being able to watch a movie on your favorite device can provide enough motivation for an attacker to extract keys. Once extracted, you cannot unring this bell.
This has not stopped researchers from developing alternative authenticity schemes. For example, Google recently published a new scheme they call SynthID. That said, this approach faces the same fundamental problem: authenticating trustworthy produced generative AI content isn’t the same thing as detecting fakes.
It may also be interesting to note that the problem of detecting authentic digital content isn’t limited to generative AI content. For example, the Costco virtual member card uses a server-generated QR code that rotates periodically to limit the exposure of sharing of that QR code via screenshots.
This does not mean that the approach of signing or watermarking content to make it authenticatable lacks value; rather, it underscores the need to recognize that detecting fakes is not the same as authenticating genuine content — and even then we must temper the faith we put in those claims.
Mobile phones, such as iPhones and Android devices, offer features that help remote servers authenticate the applications they communicate with. While not foolproof, assuming a hardened and unmodified mobile device, these features provide a reasonable level of protection against specific attacks. However, if a device is rooted at the kernel level, or physically altered, these protective measures become ineffective. For instance, attaching an external, virtual camera could allow an attacker to input their AI-generated content without the application detecting the anomaly.
There have also been efforts to extend similar capabilities to browsers, enabling modern web applications to benefit from them. Putting aside the risks of abuse of these capabilities to make a more closed web, the challenge here, at least in these use cases, is that browsers are used on a wider range of devices than just mobile phones, including desktops, which vary greatly in configuration. A single driver update by an attacker could enable AI-generated content sources to be transmitted to the application undetected.
This does not bode well for the future of remote identification on the web, as these problems are largely intractable. In the near term, the best option that exists is to force users from the web to mobile applications where the server captures and authenticates the application, but even this should be limited to lower-value use cases because it too is bypassable by a motivated attacker.
In the longer term, it seems that it will fuel the fire for governments to become de facto authentication service providers, which they have demonstrated to be ineffective at. Beyond that, if these solutions do become common, we can certainly expect their use to be mandated in cases that create long-lasting privacy problems for our children and grandchildren.
UPDATE:A SecurityWeek article came out today on this topic that has some interesting figures on this topic.
In September 2023, the SMIME Baseline Requirements (BRs) officially became a requirement for Certificate Authorities (CAs) issuing S/MIME certificates (for more details, visit CA/Browser Forum S/MIME BRs).
The definition of these BRs served two main purposes. Firstly, they established a standard profile for CAs to follow when issuing S/MIME certificates. Secondly, they detailed the necessary steps for validating each certificate, ensuring a consistent level of validation was performed by each CA.
One of the new validation methods introduced permits mail server operators to verify a user’s control over their mailbox. Considering that these services have ownership and control over the email addresses, it seems only logical for them to be able to do domain control verification on behalf of their users since they could bypass any individual domain control challenge anyway. This approach resembles the HTTP-01 validation used in ACME (RFC 8555), where the server effectively ‘stands in’ for the user, just as a website does for its domain.
Another new validation method involves delegating the verification of email addresses through domain control, using any approved TLS domain control methods. Though all domain control methods are allowed for in TLS certificates as supported its easiest to think of the DNS-01 method in ACME here. Again the idea here is straightforward: if someone can modify a domain’s TXT record, they can also change MX records or other DNS settings. So, giving them this authority suggests they should reasonably be able to handle certificate issuance.
Note: If you have concerns about these two realities, it’s a good idea to take a few steps. First, ensure that you trust everyone who administers your DNS and make sure it is securely locked down.
To control the issuance of S/MIME certificates and prevent unauthorized issuance, the Certification Authority Authorization (CAA) record can be used. Originally developed for TLS, its recently been enhanced to include S/MIME (Read more about CAA and S/MIME).
Here’s how you can create a CAA record for S/MIME: Suppose an organization, let’s call it ‘ExampleCo’, decides to permit only a specific CA, ‘ExampleCA’, to issue S/MIME certificates for its domain ‘example.com’. The CAA record in their DNS would look like this:
example.com. IN CAA 0 smimeemail "ExampleCA.com"
This configuration ensures that only ‘ExampleCA.com’ can issue S/MIME certificates for ‘example.com’, significantly bolstering the organization’s digital security.
If you wanted to stop any CA from issuing a S/MIME certificate you would create a record that looks like this:
example.com. IN CAA 0 issuemail ";"
Another new concept introduced in this round of changes is a new concept called an account identifier in the latest CAA specification. This feature allows a CA to link the authorization to issue certificates to a specific account within their system. For instance:
example.com. IN CAA 0 issue "ca-example.com; account=12345"
This means that ‘ca-example.com’ can issue certificates for ‘example.com’, but only under the account number 12345.
This opens up interesting possibilities, such as delegating certificate management for S/MIME or CDNs to third parties. Imagine a scenario where a browser plugin, is produced and managed by a SaaS on behalf of the organization deploying S/MIME. This plug-in takes care of the initial enrollment, certificate lifecycle management, and S/MIME implementation acting as a sort of S/MIME CDN.
This new capability, merging third-party delegation with specific account control, was not feasible until now. It represents a new way for organizations to outsource the acquisition and management of S/MIME certificates, simplifying processes for both end-users and the organizations themselves.
To the best of my knowledge, no one is using this approach yet, and although there is no requirement yet to enforce CAA for SMIME it is in the works. Regardless the RFC has been standardized for a few months now but despite that, I bet that CAs that were issuing S/MIME certificates before this new CAA RFC was released are not respecting the CAA record yet even though they should be. If you are a security researcher and have spare time that’s probably a worthwhile area to poke around 😉