There’s a saying, “where there’s smoke, there’s fire.” This adage holds especially true in the context of WebPKI Certificate Authorities (CAs). Patterns of issues are one of the key tools that root programs use to understand what’s happening inside organizations. While audits are essential, they are often insufficient. Historical cases like Wirecard and Enron illustrate how audits can provide a partial and sometimes incorrect picture. Just as in most interactions in life, understanding who you are dealing with is crucial for successful navigation, especially when a power dynamic differential exists.
The Limitations of Audits
Currently, there are 86 organizations in the Microsoft root program. Most root programs have at most two people involved in monitoring and policing these 86 CAs. Technologies like Certificate Transparency make this possible, and open-source tools like Zlint and others use this data to find technically observable issues. However, these tools, combined with audits, only provide a small slice of the picture. Audits are backward-looking, not forward-looking. To understand where an organization is going, you need to understand how they operate and how focused they are on meeting their obligations.
This is where the nuanced side of root program management, the standards, and norms of the ecosystem, come into play. If we look at signals in isolation, they often appear trivial. However, when we examine them over a long enough period in the context of their neighboring signals, a more complete picture becomes apparent.
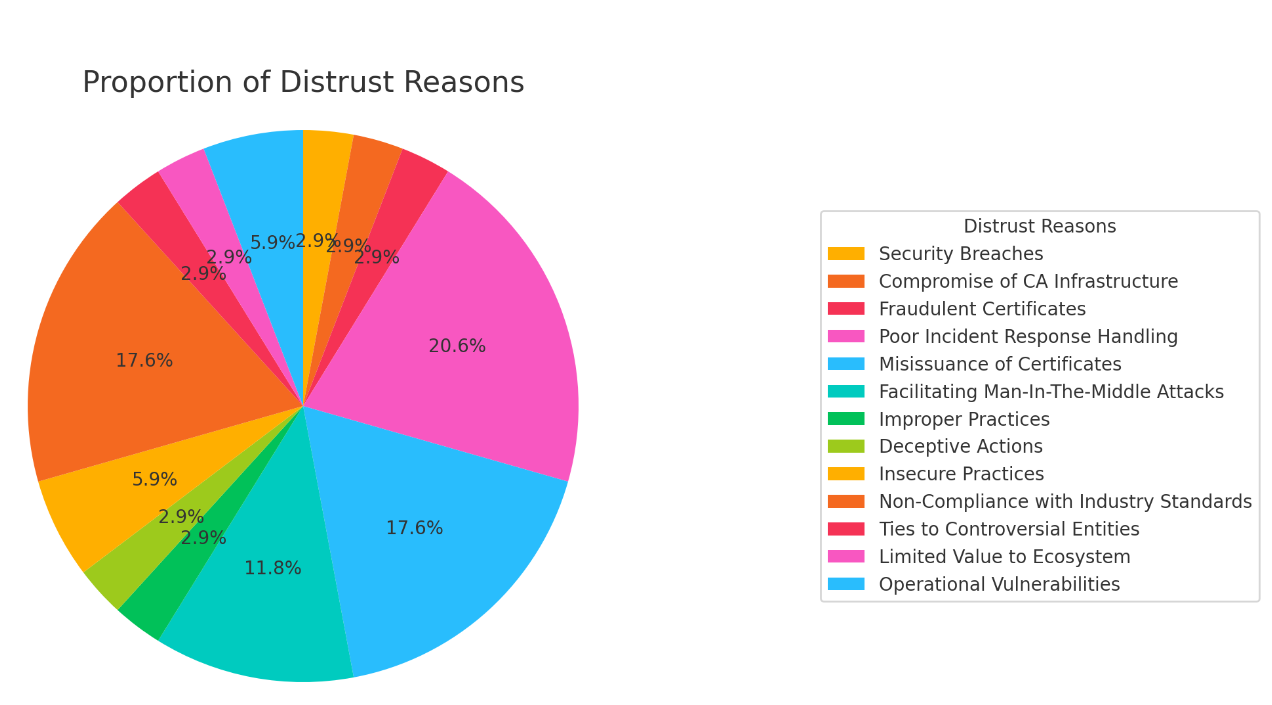
For example, consider a CA with minor compliance issues that seem trivial in isolation. A single misissued certificate might not seem alarming. But when you see a pattern of such incidents over time, combined with other issues like poor incident response or associations with controversial entities, the picture becomes clearer. These patterns reveal deeper issues within the organization, indicating potential systemic problems.
Root Program Challenges
Root programs face significant challenges in managing and monitoring numerous CAs. With limited personnel and resources, they rely heavily on technology and community vigilance. Certificate Transparency logs and tools like Zlint help identify and flag issues, but they are only part of the solution. Understanding the intentions and operational integrity of CAs requires a deeper dive into their practices and behaviors.
In the WebPKI ecosystem, context is everything. Root programs must consider the broader picture, evaluating CAs not just on isolated incidents but on their overall track record. This involves looking at how CAs handle their responsibilities, their commitment to security standards, and their transparency with the community. A CA that consistently falls short in these areas, even in seemingly minor ways, can pose a significant risk to the ecosystem.
Conclusion
Understanding the nuances of CA operations and focusing on their adherence to obligations is critical. By examining patterns over time and considering the broader context, root programs can better identify and address potential risks. The combination of audits, technological tools, and a keen understanding of organizational behavior forms a more comprehensive approach to maintaining trust in the WebPKI system.
It’s always important to remember that CAs need to be careful to keep this in mind. After all, it’s not just what you do, but what you think you do. Having your house in order is essential. By learning from past mistakes and focusing on continuous improvement, organizations can navigate public reporting obligations more effectively, ensuring they emerge stronger and more resilient.