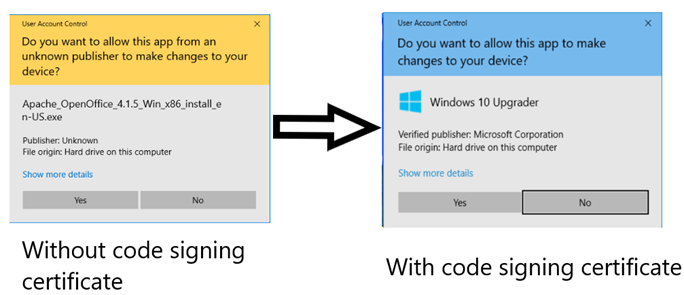
Background
Before we talk about the future we need to make sure we have a decent understanding of the past. X.509 based Public Key Infrastructure originally was created in the late 80s with a focus on enterprise and government use cases. These use cases were largely for private systems, it was not until a decade later this technology was applied to the internet at large.
Since the standards for enrollment and lifecycle management at the time were building blocks rather than solutions and were designed for government and enterprise use cases rather than the internet, the Web PKI, as it became known, relied largely on manual certificate lifecycle management and a mix of proprietary automation solutions.
While the use of PKI in the enterprise continued, primarily thanks to Microsoft AD/CS and its automatic certificate lifecycle management (I worked on this project), the Web PKI grew in a far more visible way. This was primarily a result of the fact that these certificates had to be acquired manually which led to the creation of an industry focused on sales and marketing of individual certificates.
The actors in this system had no incentive to push automation as it would accelerate the commoditization of their products. The reality was that these organizations had also lost much of their technical chops as they became sales and marketing organizations and could no longer deliver the technology needed to bring this automation anyways.
This changed in 2016 when the Internet Security Research Group, an organization I am involved in, launched Let’s Encrypt. This was an organization of technologists looking to accelerate the adoption of TLS on the web and as such started with a focus on automation as it was clear that without automation growth of HTTPS adoption would continue to be anemic. What many don’t know is in when Let’s Encrypt launched HTTPS adoption was at about 40% and year over year growth was hovering around 2-3%, about the rate of growth of the internet and — it was not accelerating.
Beyond that TLS related outages were becoming more frequent in the press, even for large organizations. Post mortems would continuously identify the same root causes, a manual process did not get executed or was executed incorrectly.
The launch of Let’s Encrypt gave the Internet the first CA with a standards-based certificate enrollment protocol (ACME), this combined with the short-lived nature of the certificates they issued meant those that adopted it would have to use automation for their services to reliably offer TLS. This enabled products to make TLS work reliably and by default, a great example of this is the Caddy web server. This quickly took the TLS adoption rate to around 10% year over year and now we are hovering around 90%+ HTTPS on the internet.
While this was going on the concept of microservices merged with containers which led to container-orchestration, which later adopted the concept of mesh networking. This mesh networking was often based on mutual-TLS (mTLS). The most visible manifestation of that being SPIFFE, the solution used by Kubernetes.
At the same time, we saw networks becoming more composable, pushing authentication and authorization decisions out to the edge of the network. While this pattern has had several names over the years we now call it Zero Trust and a visible example of that today is Beyond Corp from Google. These solutions again are commonly implemented ontop of mutual TLS (mTLS).
We now also see the concept of Secure Access Service Edge (SASE) or Zero-Trust Edge gaining speed which extends this same pattern to lower-level network definition. Again commonly implemented ontop of mTLS.
The reality is that the Web PKI CAs were so focused on sales and marketing they missed almost all of these trends. You can see them now paying lip service to this by talking about DevOps in their sales and marketing but the reality is that the solutions they offer in this area are both too late and too little. This is why cloud technology providers like Hashicorp and cloud providers like Amazon and Google (I am involved in this also) had to step in and provide their offerings.
We now see that Web PKI CAs are starting to more seriously embrace automation for the public PKI use cases, for example, most of the major CAs now offer ACME support to some degree and generally have begun to more seriously invest in the certificate lifecycle management for other use cases.
That being said many of these CAs are making the same mistakes they have made in the past. Instead of working together and ensuring standards and software exist to make lifecycle management work seamlessly across vendors, most are investing in proprietary solutions that only solve portions of the problems at hand.
What’s next?
The usage of certificates and TLS has expanded massively in the last decade and there is no clear alternative to replace its use so I do not expect the adoption of TLS to wain anytime soon.
What I do think is going to happen is a unification of certificate lifecycle management for private PKI use cases and public PKI use cases. Mesh networking, Zero-Trust, and Zero-Trust edge is going to drive this unification.
This will manifest into the use of ACME for these private PKI use cases, in-fact this has already started, just take a look at Cert Manager and Small Step Certificates as small examples of this trend.
This combined with the ease of deploying and managing private CAs via the new generation of Cloud CA offerings will result in more private PKIs being deployed and the availability problems from issues like certificate expiration and scalability will no longer be an issue.
We will also see extensions to the ACME protocol that make it easier to leverage existing trust relationships which will simplify the issuance process for private use cases as well as ways to leverage hardware-backed device identity and key protection to make the use of these certificate-based credentials even more secure.
As is always the case the unification of common protocols will enable interoperability across solutions, improve reliability and as a result accelerate the adoption of these patterns across many products and problems.
It will also mean that over time the legacy certificate enrollment protocols such as SCEP, WSTEP/XCEP, CMC, EST, and others will become less common.
Once this transition happens this will lead us to a world where we can apply policy based on subjects, resources, claims, and context across L3 to L7 which will transform the way we think about access control and security segmentation. It will give both more control and visibility into who has access to what.
What does this mean for the Web PKI?
First I should say that Web PKI is not going anywhere – with that said it is evolving.
Beyond the increase in automation and shorter certificate validities over the next decade we will see several changes, one of the more visible will be the move to using dedicated PKI hierarchies for different use cases. For example, we will ultimately see server authentication, client authentication, and document signing move to their own hierarchies. This move will better reflect the intent of the Web PKI and prevent these use cases from holding the Web PKI’s evolution back.
This change will also minimize the browser influence on those other scenarios. It will do this at the expense of greater ecosystem complexity around root distribution but the net positive will be felt regardless. I do think this shift will give the European CAs an advantage in that they can rely on the EUTL for distribution and many non-web user agents simply do not want to manage a root program of their own so the EUTL has the potential to be adopted more. I will add that is my hope these user agents instead adopt solution-specific root programs vs relying on a generic one not built for purpose.
The Web PKI CAs that have not re-built their engineering chops are going to fall further behind the innovation curve. Their shift from engineering companies to sales and marketing companies resulted in them missing the move to the cloud and those companies that are going through digital transformation via the adoption of SaaS, PaaS, and modern cloud infrastructures are unlikely to start that journey by engaging with a traditional Web PKI CA.
To address this reality the Web PKI CAs will need to re-invent themselves into product companies focusing on solving business problems rather than selling certificates that can be used to solve business problems. This will mean, for example, directly offering identity verification services (not selling certificates that contain assertions of identity), providing complete solutions for document signing rather than certificates one can use to sign a document or turnkey solutions for certificate and key lifecycle management for enterprise wireless and other related use cases.
This will all lead to workloads that were once on the Web PKI by happenstance being moved to dedicated workload/ecosystem-specific private PKIs. The upside of this is that the certificates used by these infrastructures will have the opportunity to aggressively profile X.509 vs being forced to carry the two decades of cruft surrounding it like they are today.
The Web PKI CAs will have an opportunity to outsource the root certificate and key management for these use cases and possibly subcontract out CA management for the issuing CAs but many of these “issuing CA” use cases are likely to go to the cloud providers since that is where the workloads will be anyway.
Due to the ongoing balkanization of the internet that is happening through increased regional regulation, we will see smaller CAs get acquired, mainly for their market presence to let the larger providers play more effectively in those markets.
At the same time, new PKI ecosystems like those used for STIR/SHAKEN and various PKIs to support IoT deployments will pop up and as the patterns used by them are found to be inexpensive, effective, and easily deployable they will become more common.
We will also see that the lifecycle management for both public and private PKI will unify ontop of the ACME enrollment protocol and that through that a new generation of device management platforms will be built around a certificate-based device identity anchored in keys bound to hardware where the corresponding certificates contain metadata about the device it is bound to.
This will lay the groundwork for improved network authentication within the enterprise using protocols like EAP-TTLS and EAP-TLS, enable Zero-Trust and Zero-Trust Edge deployments to be more easily deployed which will, in turn, blur the lines further between what is on-premise and what is in the cloud.
This normalization of the device identity concepts we use across solutions and the use of common protocols for credential lifecycle will result in better key hygiene for all use cases, and simplify deployment for those use cases.