Caddy is a powerful and easy-to-use web server that can be configured to use a variety of certificate authorities (CA) to issue SSL/TLS certificates. One popular CA is Google Trust Services, which offers an ACME endpoint that is already compatible with Caddy because it implements the industry-standard ACME protocol (RFC 8555).
This means that Caddy can automatically handle the process of certificate issuance and renewal with Google Trust Services, once the External Account Binding (EAB) credentials required have been configured.
How do I use it?
Using global options
To use the Google Trust Services ACME endpoint you will need an API key so you can use a feature in ACME called External Account Binding. This enables us to associate your certificate requests to your Google Cloud account and allows us to impose rate limits on a per-customer basis. You may easily get an API key using the following commands:
In this example Google Trust Services will be tried and if there is a problem it will fall back to Let’s Encrypt.
It is also worth noting that the Google Trust Services EAB key is one time use only. This means that once Caddy has created your ACME account these can be safely removed.
Using the tls directive
If you want to use Google Trust Services for only some of your sites, you can use the tls directive in your Caddyfile like you’re used to:
The email address in this example identifies the ACME account to be used when doing enrollment.
In conclusion, using Caddy with Google Trust Services is a simple and simple and secure way to issue and manage SSL/TLS certificates for your websites. With the easy-to-use Caddyfile configuration, you can quickly and easily configure your server to use Google Trust Services for all of your sites or just a select few. With Google Trust Services, you can trust that your websites will be secure and your visitors’ data will be protected.
Every service should strive to provide perfect availability, the reality is that it’s not possible to be perfect. Mistakes happen, it’s how you deal with them that is important.
Successfully dealing with availability issues requires planning, and when dealing with a client-server solution, it requires both parties to make improvements.
In the context of ACME today the large majority of clients have no failover or logic. This means if the enrollment fails due to connectivity issues to the specified CA, the CA has an outage, or the CA suspends operations for one reason or another the enrollment will fail.
This is a problem for any service protected with TLS, which is basically every service, that wants to have a highly available service. One of the ways services deal with this is to proactively acquire two certificates for every endpoint, this is viable, but I would argue this is not the right solution.
The right solution is to not rely on a single CA and instead failover between many CAs that are capable of servicing your needs. This way if any single CA fails you are fine, you can just keep chugging along.
That is not sufficient to address this risk though. Not all certificates have the same level of device trust. Sometimes clients make bad assumptions and trust specific CA hierarchies assuming these configurations are static, even when they are not.
To help mitigate this behavior clients should implement a round-robin or random CA selection logic so that subsequent renewals will hit different CAs. This will force clients to make sure they work with any of your chosen CAs. This way you won’t find yourself breaking apps that make those bad assumptions when your CA fails.
Caddy Server already implements both of these strategies as I understand it but every ACME client should be doing the same thing.
My father always says it’s not a problem to make a mistake, what is important is how you deal with it.
The same thing is true when it comes to WebPKI CAs, broadly the incident response process used in this ecosystem could be categorized as Blameless Post Mortem. The focus is on what happened, what contributed to it, and what was done to address the issue and not on fault.
A few years ago a number of large CAs had to do millions of revocations, in all of the cases I am thinking the required deadline for those revocations was 5 days. Revoking a large number of certificates that are not directly obvious but if you’re a CA who has done any moderate level of planning it’s something you should be up for.
The thing is that doing so can cause harm, for example, the issue that necessitates the revocation might be incredibly subtle and not security-impacting. Nonetheless, the requirement is what the requirement is — the certificate needs to be revoked.
The question then becomes how can you meet that timeline objective without creating an unnecessary outage for customers? If you defy the rules you risk being distrusted, if you act blindly you could take down your customer’s services.
The question then becomes how do you contact millions of customers and give them enough time to replace their certificates without an outage with these constraints?
Like most scale problems the answer is automation, in the context of certificate lifecycle management that means an extension to the ACME protocol. To that end, there is now a draft for something called “ACME Renewal Information” which when implemented by CAs and ACME clients will enable a CA to signal that there may be a need to replace their certificate earlier than expected.
The basic idea with this proposal is that the CA will make available hints on when it would like certificates to be updated and the client will periodically check this information and use it to guide its renewal behavior.
To be clear, this is just a hint, a CA might be providing this hint just to smooth out the load, but there is no mandate to rely on the hint. With that said I do hope that all major ACME clients implement this standard and respect it by default because it will make the WebPKI a lot less fragile.
I’ll start by saying this post is just a collection of personal thoughts and not a statement from my employer, nor does it reflect anyone’s opinions other than my own.
A common problem in the WebPKI is that CAs forget why they exist. No one cares about their business objectives. They exist to serve the public interest, more explicitly they exist to help the web solve the TOFU problem for domain control verification.
They exist because user agents (usually browsers) made the decision to delegate the TOFU problem to certificate authorities. To understand the browser’s motivation you simply need to look at the name “user agent” to understand that they directly serve the user.
These user agents used to meet individually with each and every one of these CAs to discuss the user agent requirements for CAs but ultimately decided to do this in a more collaborative way by participating in the CA/Browser Forum.
Simply put, this organization would very likley stop existing if the user agents stopped participating and did not rely on the documents that come from this organization.
We know this to be true because of the voting structure of the forum and because the forum does not produce documents that govern the user agents, it produces documents that govern the practices of CAs.
To understand the nature of the CA/Browser program you just have to look at the name of the first and most important document they produced — the Server Certificate Baseline Requirements.
base·line
noun
a minimum or starting point used for comparisons.
That’s right, it sets the minimum bar that a user agent should consider when trusting a certificate authority.
Far too often compliance programs end up driving the roadmap and operational practices of CAs and it stops being about what is right and becomes what is minimally required.
This leads to all kinds of spectacular failures, including basic failures in communication:
Instead of this compliance-focused mindset, CAs must be focused on why they exist, who they serve, and what is at risk if they mess things up.
I would argue that every major failure in the WebPKI has stemmed from forgetting about these simple questions.
I’ll start by saying this post is just a collection of personal thoughts and not a statement from my employer, nor does it reflect anyone’s opinions other than my own.
For the uninitiated, TOFU is an acronym for Trust On First Use. The basic idea is that the user makes the trust decision associated with a communication channel on the first visit.
To understand the concept here, you need to know what we mean by “communication channel” and what we “trust” them for.
Let’s start with what we mean by the “communication channel”. In the context of the web, for the most part, a user agent (often a browser) initiates communication to a service located at a fully qualified domain name. This is usually done using the Transport Layer Security (TLS) protocol.
Next, let’s look at what “trust decision” is being made. Notice we don’t have an application yet, we have just established a session that an application and a service can use to exchange information. As a result, the trust decision we are making is:
Did my traffic end up at a service associated with the aforementioned fully qualified domain name?
The naive way to answer the question is to ask that question every time a user visits the service. In fact, some browsers support this model explicitly:
This is the moral equivalent of saying “do you feel lucky?” because the user has no way to answer this question.
It is actually worse than that, the few ways you can answer that question require the participation of the service being authenticated. That means any solution has to potentially scale up to the 5 billion users on the internet.
Since each of these users has varying degrees of technical prowess and the service in question has a limited amount of time and resources; doing this for every user interactivity would be impractical.
The gray hairs of the internet decided to solve this problem by delegating this trust decision to entities known as Certificate Authorities (CAs). They indirectly act as a middleman for the session establishment, they do this by issuing the service a credential it can use to prove that someone did this verification for them.
These CAs do this verification by having the service perform some authenticatable action that only someone that controls the fully qualified domain name in question could complete This whole dance is basically delegated TOFU of control of the fully qualified domain name.
Over the last 28 years, this delegation has taken us from no HTTPS to near-ubiquitous HTTPS.
This is of course fantastic but it does beg the question what has this journey taught us and what might we change moving forward?
For one right now, if we believe this table, there are about 89 organizations in the world that are approved Certificate Authorities. But the top 5 of those CAs issue 99% of all certificates in use on the web.
That’s right 96% of the CAs that can issue certificates for the web could disappear tomorrow and most people would not notice.
What concerns me is that running a CA is hard, expensive, and has materially different operating constraints than other services. This combined with the love nation-state attackers have for these services has led to numerous colorful events over the years 1,2,3,4,5,6.
To be clear I am not making the case that those CAs should be removed, just making it clear that the web is carrying a much larger surface area than it strictly needs to deliver on its original design goal.
That takes us back to the question of what lessons the last 28 years have taught us and what might we change moving forward. The answer here is likely buried in the adage of having one joint and keeping it well-oiled is key.
The journey from 0% of the web being protected with HTTPS to nearly 100% has been one of simplification and automation. There is plenty of opportunity for us to do more of that and doing so will be key to the survivability of encryption on the web, some problems we might want to see in addressed that spirit include:
Too many single points of failure in the WebPKI. If any of those top 5 CAs were to fail we would experience a massive failure on the web. For us to address this we need to standardize on a single certificate enrollment protocol, this would make the CAs plug-and-play replacements for each other. We already have a de-facto standard RFC 8555 (ACME) which is responsible for around 70% of all certificate issuance. We should just embrace that and make it official. Once we see sufficient ACME adoption we need the ACME clients to fail over and round-robin across all the associated CAs. This will help ensure clients are able to survive any single CA failure.
We need the WebPKI to be less fragile. There are lots of examples of WebPKI fragility, some are:
Clients sometimes get hard coded to expect a single issuing CA. This is a very bad practice, one some CAs have already started to dissuade by randomly selecting issuing CAs.
Reliance on very long-lived root certificates instead of very frequent root updates. This is also thankfully starting to change but solving this problem will take us a very long time thanks to root programs that do not continually manage what roots are trusted in deployed systems.
The inability of the web to survive CA mistakes and potential security issues without creating outages. There is also work being done here in an extension to ACME called ARI to help enable the web to seamlessly renew certificates in such cases.
Too many CAs with too broad permissions. Since most CAs are not necessary for the web to operate but may still have a legitimate need to exist we should leverage usage and name constraints in root trust more. This would go a long way to both reduce the value of a compromise of these CA long tail CAs to an attacker as well as reduce the exposure to the web as a whole to the practices of these CAs. We should also come back and revisit the need for CAs to keep those permissions periodically.
Over-reliance on manual assessments by unqualified auditors and security professionals. This introduces a number of issues, some of which include:
The fiduciary relationship between an auditor and their client is such that no one wants to fail their client’s audit because they want to do next year’s audit.
Usually, these audits are performed by individuals with limited experience in PKI, operational systems, and security.
Root programs are too slow to respond to bad or questionable actors. Suspension of a CA is not-done and total distrust can take months or longer. There are a lot of politics involved here but equally important is the tooling to remove CAs, both procedurally and technically. In these things are simply not “well oiled”. They need to be made far more agile so that this long tail can be more effectively managed.
So what can you do about all of this? Well if you are a root program you should be looking at how you help address the above issues through the way you manage that program.
If you are a website operator? Well, the answer there is easy — adopt ACME-based certificate lifecycle management, keep an eye on Certificate Transparency logs for certificates issued by that long tail of CAs and consider specifying CAA restrictions that limit issuance to a small number of CAs.
As Google Trust Services has been available for a few weeks I thought it would be interesting to look at where it stands relative to other CAs based on its issuance volume.
#
CA Owner
Certificates
Pre-Certificates
All
Unexpired
All
Unexpired
1
Internet Security Research Group
2,972,072,131
270,986,317
2,689,923,862
233,570,311
2
DigiCert
115,808,406
7,603,151
443,129,508
138,144,685
3
Sectigo
580,982,481
45,262,868
517,794,477
46,204,659
4
Google Trust Services LLC
13,909,548
467,650
120,070,013
21,232,287
5
Microsoft Corporation
17,567
170
32,448,453
16,959,805
For more on this methodology of counting see this post.
If you live in the United States you surely get a ton of robocalls. As an aside, for whatever reason, it appears the problem is less severe in other countries.
If you look at these robocalls, one common element is that the phone numbers used are usually made up to look like they are hyper-local calls or simply do not disclose the origin. They do this to increase the chance you pick up the call.
This is possible because the phone system was largely designed on blind trust in telephone operators. As an example of this, you do not need to look further than the caller id metadata. Today the originator and their carrier get to set any phone number they like, as such, you can’t reliably block the call based on caller id or carrier metadata. Back when there was Ma Bell that was probably a rational choice. That said after Bell System was broken up it became far more problematic — the expansion of telephone services made that design assumption a larger issue.
That takes us to STIR/SHAKEN — this blind trust still exists in much of the telephone ecosystem and one area where this manifests today is these robocalls.
STIR/SHAKEN is intended to solve this problem, or at least be a key foundation for solving the problem. By making each telephone operator cryptographically sign the call metadata it becomes possible to hold the originator and their carrier accountable.
While this will not solve the problem of robocalls it does introduce a durable cryptographically verifiable credential that can be used to build databases of a reputation for both originating phone numbers and telephone companies.
In other words, adopting SHAKEN/STIR is about making it possible to fight robocalls, not fighting them directly. To be clear, there may be some ancillary reduction of robocalls due to the increased cost and complexity associated with participating in the STIR/SHAKEN ecosystem but this is at best a speed bump to a motivated attacker.
The good news is that once there is near ubiquitous adoption of this standard, it becomes far more practical for needed reputation systems to built. This in turn will hopefully enable the telephone companies to make a big dent in the problem.
In my opinion, the development and maintenance of these reputation systems is the harder problem of the two parts. I say this because today there is no signal from end-users to indicate that they believe the call was in fact a robocall.
While it is technically possible to look at aggregate user behavior, for example how quickly they hang up, or if they do not answer, to come up with a probability of being a robocall without this positive signal it will be a guess. The same is said for traffic pattern reputation systems, these are essentially a guess without affirmative labeling from the user.
The other problem that exists here is that this behavior data is only available to handset manufacturers and telephone network operators. I also suspect in both cases each party has usage restrictions on what they can do with the data, for example, are they allowed to share the data with other telephone network operators or handset manufacturers?
There are several robocall abatement applications out there that try to address this problem, the ones I have looked at appear to have horrible privacy policies and many are free suggesting their revenue model must be based on leveraging your call history.
Once installed these applications are surely sending this behavioral data to the cloud to analyze it for this specific purpose. The apps I have seen also expose ways to explicitly flag calls as spam or unwanted. This is probably the best you can do as a third party to build such a reputation system,
All of this basically means that you are in essence being asked to give up your privacy, and the privacy of those you communicate with, in exchange to avoid nuisance calls.
For some, this may be a good trade-off but for others, it likely is not.
I would rather see a model where telephone operators were required to share data with each other and do so with data usage constraints. If that was combined with some standardization by platforms like Android and IOS that made it possible for users to flag unwanted calls, and made it so that information could be shared across providers we might see a reliable, privacy-respecting solution to this problem become reality at some point.
In an earlier post, I talked about what it is like to get an EV Code Signing Certificate in 2022 but what I didn’t talk about in that post was token management.
The first thing is that most smart cards implement a proprietary card edge, for example, the SafeNet 5110 is probably the most popular PKI-based smart card token. Since this token is totally proprietary you need to install what is called the SafeNet Authentication Client (SAC) before you can do much of anything with this token.
Most CAs will mail you an unprovisioned token, and tell you to install this client which contains amongst other things a PKCS#11 library that can work with it. The most important part of this package is actually the administration client though.
Without this, you can not initialize the token (roughly the equivalent of formatting it), set or change the passwords for using it, unblock it, or delete certificates from it (necessary as they have limited space).
What is important to understand is that these smart cards have their own administration model, in essence, there is a root user (the Security Officer or SO) and a regular user (that’s the person doing the code signing).
To make things easier for the recipient of a token these tokens are shipped with default secrets, at a minimum that involves the SO and user password (often all zeros or some other well-known sequence of numbers). For example, the default SO password for the SafeNet 5100 is a sequence of 48 zeros.
While the SAC client will generate a random value for the SO password if you want it to, if you do not know what you are doing, it’s actually pretty natural to let it keep re-using the all zeros secret. On the other hand, if you let it assign a random value and do not secure it in some way so it is not lost if you type your password wrong 5 times the token is bricked.
This leaves us with a spectrum of choices that starts with a charade of protection and ends with something that would fail to meet the most basic business continuity expectations.
One might argue that anyone who wants to use a smart card would be savvy enough to know the above and make sure to use the appropriate practices. I personally find that hard to believe. If you do a search on the web right now I bet the only thing you will find is a few screenshots of how to get the token to the point it can have a key generated on it.
There are some providers who have built out remote signing capabilities using proprietary REST APIs and tooling, these are arguably a better choice than using a smart card but they also tend not to work very well or be very reliable. Not exactly what you want in a process that can gate your releases.
In summary, today, even when you manage to get a smart card enrollment to work remotely, there is a very good chance that you are not managing the smart card lifecycle and associate secretes effectively.
The first thing you will need to do is to find a Windows machine, that is because it is only possible to enroll for an EV Code Signing certificate on Windows. The only browser that provides a way to enroll for a certificate with a smart card is Internet Explorer.
Internet explorer was deprecated on June 15, 2022, but the reality is that its market share had dropped to almost nothing long before that. Today .28% of web browser traffic is from IE.
Edge does have an “IE Mode” that allows you to reload a page with this older version of the browser which still supports this smart card enrollment capability. The thing is that usually IE is only needed for one small part of a flow, for example when ordering an EV certificate you may complete the entire flow in your primary browser and have to start over again in this IE mode to do the actual enrollment.
While IE mode will continue to be supported through 2029. Edge only has about 4.11% of the browser market share today which means at a minimum most users must change browsers before they can get to this deprecated functionality. This pain is all rooted in an older technology known as COM. IE used to let you access COM components on the web, this was done via something known as ActiveX.
ActiveX was a bad idea that was poorly executed but it did enable ways to break out of the browser sandbox to do interesting things. Unfortunately, those interesting things were also often interesting to attackers. This is why it was deprecated by IE long before IE itself was deprecated.
A limited set of ActiveX components got a stay of execution when that happened, one such component is CertEnroll. This control was allowed listed and has been used by CAs to facilitate certificate lifecycle management of user certificates on the web. Despite the proliferation of individual user/organization certificates (they are used more now than ever) there was no replacement made.
The thing is, even when it worked, it didn’t work well. For example, the CertEnroll component will commonly becomes non-responsive — as a result, the web browser ends up freezing. Recently I did an enrollment and IE hung for 4 minutes. I had two options, kill the browser with task manager or wait and pray it would return.
In summary, 96% of people on the web would need to change their browser and jump through a user experience that was designed in the early 2000s, an experience that was never invested in sufficiently, to get an EV code signing certificate today.
Another problem that exists here is that this is all smoke and mirrors from a security perspective. These EV certificates are required to have their keys stored on a smart card, this is effectively accomplished with some client-side javascript filtering of what middleware is used for the enrollment. This can be trivially bypassed with a few lines of Javascript in the browser console window. Doing this gives you an EV code signing certificate that has keys stored in the software. I have, for example, encountered CA websites that use third-party analytics javascript in their enrollment flows, any of these third parties could exfiltrate the code signing keys and the user wouldn’t notice. And if they did it would be because they would have had a better experience because of the issues I call out above.
YubiKey is the only smart card I know that supports an attestation for X.509 certificate keys that tells the CA that it is managing the key. This would mitigate this issue but there is no way to access this attestation information from the browser. If it were me I would mandate that only the YubiKey token be used for EV code signing certificates and either use a third-party solution like Fortify to interact with these tokens or require the YubiKey console tools be used for the enrollment. This would allow CAs to verify one of these tokens was actually being used to protect these keys.
Code signing is an important tool in protecting the software supply chain. It helps us understand an artifact’s origin, its integrity, and in the best case what quality bars the code meets. It would be fantastic if the scaffolding that enabled it wasmade so it was both easy and secure to do the right thing.
There is a class of problems in information security that are intractable. This is often because they have conflicting non-negotiable requirements.
A good example of this is what I like to call the “re-entry” problem. For instance, let’s say you operated a source control service, let’s call it “SourceHub”. To increase adoption you need “SourceHub” to be quick and easy for anyone to join and get up and running.
But some users are malicious and will do nefarious things with “SourceHub” which means that you may need to kick them off and keep them off of your service in a durable way.
These two requirements are in direct conflict, the first essentially requires anonymous self-service registration and the second requires strong, unique identification.
The requirement of strong unique identification might seem straightforward on the surface but that is far from the case. For example, in my small social circle, there are four “Natallia’s” who are often are at the same gatherings, everyone must qualify which one we are talking to at these events. I also used to own ryanhurst.com but gave it up because of the volume of spam I would get from fans of Ryan Hurst the actor because spam filters would fail to categorize this unique mail as spam due to the nature of its origin.
Some might say this problem gets easier when dealing with businesses but unfortunately, that is not the case. Take for example the concept of legal identity in HTTPS certificates — we know that business names are not globally unique, they are not even unique within a country which often makes the use of these business names as an identifier useless.
We also know that the financial burden to establish a “legal business” is very low. For example in Kentucky, it costs $40 to open a business. The other argument I often hear is that despite the low cost of establishing the business the time involved is just too much for an attacker to consider. The problem with this argument is the registration form takes minutes to fill out and if you toss in an extra $40 the turnaround time goes from under 3 weeks to under 2 days — not exactly a big delay when looking at financially incentified attackers.
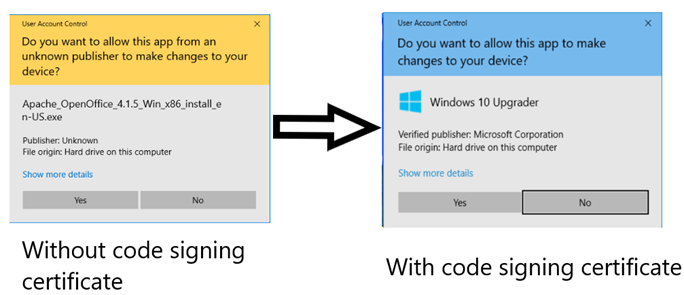
To put this barrier in the context of a real-world problem let’s look at Authenticode signing certificates. A basic organizationally validated Authenticode code signing certificate costs around $59, With this certificate and that business registration, you can get whatever business name and application name you want to show in the install prompt in Windows.
This sets the bar to re-enter this ecosystem once evicted to around $140 dollars and a few days of waiting.
But what about Authenticode EV code signing? By using an EV code signing certificate you get to start with some Microsoft Smart Screen reputation from the get-go – this certainly helps grease the skids for getting your application installed so users don’t need to see a warning.
But does this reduce the re-entry problem further? Well, the cost for an EV code signing certificate is around $219 which does take the financial burden for the attacker to about $300. That is true at least for the first time – about $50 of that first tome price goes to a smart card like the SafeNet 5110cc or Yubikey 5. Since the same smart card can be used for multiple certificates that cost goes down to $250 per re-entry. It is fair to say the complication of using a smart card for key management also slows the time it takes to get the first certificate, this gets the timeline from incorporation to having an EV code signing certificate in hand to about 1.5 weeks.
These things do represent a re-entry hurdle, but when you consider that effective Zero Day vulnerabilities can net millions of dollars I would argue not a meaningful one. Especially when you consider the attacker is not going to use their own money anyway.
You can also argue that it offers some rate-limiting value to the acquisition pipeline but since there are so many CAs capable of issuing these certificates you could register many companies, somewhat like Special Purpose Acquisition Companies (SPAC) in the stock market, so that when the right opportunity exists to use these certificates it’s ready and waiting.
This hurdle also comes at the expense of adoption of code signing. This of course begs the question of was all that hassle was worth it?
Usually the argument made here is that since the company registration took place we can at least find the attacker at a later date right? Actually no, very few (if any) of these company registrations verify the address of the applicant.
As I stated, in the beginning, this problem isn’t specific to code signing but in systems like code signing where the use of the credential has been separated from the associated usage of the credential, it becomes much harder to manage this risk.
To keep this code signing example going let’s look at the Apple Store. They do code-signing and use certificates that are quite similar to EV code-signing certificates. What is different is that Apple handles the entire flow of entity verification, binary analysis, manual review of the submission, key management, and signing. They do all of these things while taking into consideration the relationship of each entity and by considering the entire history available to them. This approach gives them a lot more information than you would have if you did each of these things in isolation from each other.
While there are no silver bullets when it comes to problems like this getting the abstractions at the right level does give you a lot more to work with when trying to defend from these attacks.